

Sponsored by:

Our sponsors make financial contributions toward the costs of publishing Linux Gazette. If you would like to become a sponsor of LG, e-mail us at .
Write the Gazette at
|
Contents: |
 Date: Wed, 02 Jul 1997 22:30:26 -0700
Date: Wed, 02 Jul 1997 22:30:26 -0700
From: Wood Ellis
Subject: Newbie Needs More Definitive Article on Parallel Port Tape Drives
The various leads which can be followed from the parport home page tend to indicate that it's just not worth all the hassle to try to operate a tape on the parallel port, unless you are an expert and maybe want to program it yourself. I just cannot believe that it is that difficult.
I would appreciate it if you were to provide an article which, in simple, newbie language, tells how to do it. The article should include definitive solutions for every brand of parallel port tape drive which is commonly available. Mine is an HP-1000 travan-1. My system is Redhat 4.1. One can imagine that some linux devotees enjoy the abstruseness of things new and difficult and exclusive. Contrary to that viewpoint, I believe that we all should strive to make linux easier and more available to the relatively uninformed. Probably you share my feeling. That's as close as I can come to a flaming request right now. I really appreciate all the good stuff in the Gazette.
Thank you,
Date: Sun Jul 6 16:35:46 1997
From: Takkala,
Subject: Please help me....
Recently, ever since I upgraded to Slackware 3.2/Redhat 4.1, I have noticed that my modem has been behaving rather erratically. My modem is a Motorola ModemSurfr 28.8. Now, when I type 'ppp-on' to initiate a ppp session, many times, the modems TR led lights up, and then nothing happens, until the computer times out 45 seconds later and aborts the ppp session. Normally, when I type 'ppp-on' the modem almost immediately begins dialing up my isp, and connecting, but most of the time, it would just sit there, until I killed the process and tried again, it may take up to twelve or more tries for the modem to dial, but sometimes it will dial on the first try. This erratic behavior only began occurring (from what I can tell, I'm not sure) ever since I upgraded to redhat 4.1, and now slackware 3.2. My modem does work fine in windows 95, and also if I use DIP, or minicom to try and connect. So I was wondering if this may be a timing error somewhere in the ppp-on script. Has anyone else had similar problems? I myself tried tweaking some of the abort timeouts, but that didn't help.
Someone please help me! Thanks for any help suggestions...
Jari
Date: Mon, 07 Jul 1997 01:00:35 -0700
From: Paul M.,
Subject: Deluxe Paint IIe
Don't mean to come out of the blue but... I was searching the net for some reference to Deluxe Paint IIe for the PC and ended up here... Can you send me any information you can about how I might get a hold of a copy of this program which I assume is discontinued. I come from an Amiga background and still feel there are some redeeming features to this program that I would like to use on my PC...
Thanks for any information you can impart!
Paul Marcano
Date: Fri, 11 Jul 1997 16:57:33 -0300
From: Annette Sahores
Subject: Problem with adaptec 2940U
I'm trying to install linux red hat 2.0.x in a machine with an Adaptec 2940U host adapter an a scsi external 4x cdrom. The problem is that the bootdisk does not recognize the host adapter, so I can't set the linux and swap partitions. may be the problem is that the driver aic7xxx is old and doesn't work whith the 2940 ultra.
Thank You
Annette Sahores
Date: Tue, 15 Jul 97 15:01:00 PDT
From: Mark Mangolas
Subject: Linux on a ThinkPad
Hello,
I am writing this in hopes that you can help me with my Linux configuration. I have Linux Slackware 3.2 running on an IBM 760E Thinkpad and I can't get X to run properly. It scrunches the screen when I fire up X and then scrambles everything when I exit forcing me to reboot. I've tried almost all of the video cards, chipsets, etc. in XF86Setup and nothing helps. Any help would be greatly appreciated......thank you,
Mark Mangolas
Date: Wed, 16 Jul 1997 15:01:49 -0400
From: Scott Fowler
Subject: Pnp Modem and mouse
Help I have a plug and pray modem and mouse, actually my mouse is a ps/2 mouse, will the program isapnptools fix all the pnp problems?
Date: Sun, 20 Jul 1997 10:43:54 -0600
From: Doug Milligan, Red Hat Linux User
Subject: Disk deferag?
I'm new to Linux, but like it very much having recently installed RedHat 4.2 via FTP. In looking through utility software I have not run accross any disk defragmentor programs nor have seen references to them in any Linux books that I have consulted. Is disk degragmentation not needed in maintaining a Linux file system?
Thanks,
Doug Milligan
Date: Sat, 19 Jul 1997 18:58:20 +0200 (SAT)
From: Abraham vd Merwe
Subject: Chown Problem
Hi!
You can make anybody the owner of your files right? At least that is w hat I always thought, but take a look at this:
% whoami ixion % cat /dev/null > ChownTest ; chmod 0777 ChownTest ; ls -l ChownTest -rwxrwxrwx 1 ixion users 0 Jul 19 18:10 ChownTest % cat /etc/passwd | grep fakeuser fakeuser:x:1005:100:Nobody:/home/fakeuser:/bin/bash % chown fakeuser ChownTest chown: ChownTest: Operation not permitted
I've tried it on various systems and it turns out that I can't make an ybody the owner of my files when I'm a user (root obviously can). Why? I'd b e very grateful if you can explain how to do it or if not possibly, at l east why I can't do it...
Thanks
Abraham
Date: Sat, 19 Jul 1997 04:40:56 +0100
From: Emmet
Subject: Firewire and DV
Hi,
I've nearly got my brother converted to Linux, except he's interested in using firewire cards and whatever software to edit video from a DV camera. After some web-searching, and a several sites, it seems that there are no firewire drivers or spiffy DV software for Linux.
Even worse, Adaptec, who manufacture what appears to be becoming a very popular card, are only supporting MS and Mac platforms. To add insult to injury, their FAQ, in response to a question about the possibility of drivers for Un*x, etc., contains the single word "No", no explanation or euphemisms, just "No".
At this point in time, horror of horrors, it looks like I'm going to wind up with my brother using NT. Frankly, I'd rather have a sister in a whorehouse than a brother using NT. Check out Mitch Stone's excellent site at http://www.vcnet.com/bms for why.
Does anybody know different? Are there any plans afoot in this direction? Maybe somebody in a position of influence could lean on some firewire card manufacturers to make their driver software available for porting to Linux? Maybe the Linux community could email or asking them to reconsider making drivers available?
Any information about the possibility of DV editing software or firewire drivers would be most appreciated. I'll help if I can.
Thanks,
Emmet.
Date: Wed, 23 Jul 1997 22:24:44 -0500
From: Ben and Nick
Subject: cpu Speed
I was wondering if you could tell me where I could get a listing of bogomites? bogomytes? on different cpu's and computers?
Thanks Ben
Date: Wed, 23 Jul 1997 15:56:49 -0400 (EDT)
From: Jon Lewis
Subject: Linux Uptimes
Do you have any idea what the longest uptime on a linux system is? I have a system with over 14 months of uptime, and am wondering if its heading for some kind of record. I've been told that with the 1.2.x kernels, uptimes longer than about 16.4 months are thought to be impossible due to jiffy counter wrap.
Date: Thu, 3 Jul 1997 19:12:36 -0700 (PDT)
From: Greg Roelofs
Subject: Re: Changing video modes
A friend of mine wants to know how to change video modes without restarting X, and I noticed you say you can do that on your Linux page. How can this be done? (I'm using XFree86, he's using MkLinux)
Just changing *modes* is easy: use ctrl-alt-gray+ and ctrl-alt-gray- to cycle between the resolutions defined in your XF86Config file. I have the following defined:
Modes "1280x1024" "1536x1152" "1600x1200" "640x480" "800x600" "1024x768"To run multiple X servers is a little trickier, and I've been meaning to write up a Linux Gazette or Linux Journal article on that. Assuming you use startx instead of xdm, the basic trick is to do something like this:
startx -- :4 -bpp 32 &My default (16-bit mode) command is this:
startx -- :1 -bpp 16 &You can switch between them via ctrl-alt-F7 through F10, typically-- F1 through F6 tend to be normal text-mode Linux consoles.
It's really best to alias these things and make sure the screen numbers (:0 or :2 or whatever) don't collide; if they do, the second X server will "steal" the number from the first, and you won't be able to start any more windows or even restart the window manager under the first server.
The special 320x200 game mode is even more complicated, and I won't even try to explain that here. It can be done with a second XF86Config or with additional lines in the main one under some circumstances.
I don't know how AccelX and XiGraphics and MetroX handle these things.
Date: Mon, 07 Jul 1997 10:27:46 -0700
From: James Gilb
Subject: *2+ Processing
Check out the Linux SMP page at http://www.uk.linux.org/SMP/title.html and get a new distribution. I think that SMP became part of the standard kernel at 2.0, so 2.0.?? might be a good choice (check out the SMP page, I think some patch levels are broken with respect to SMP).
If you are pretty good a Linux installs (and from the multiplicity of your OS's is sounds like you are), you could pick up a RedHat distribution for less than USD $10. I can't help you with availability in Sweden, but check out Caldera, RedHat, Craftworks, SuSE and Yggdrasil (sp?), I think most of them support SMP. If you need pointers to their web pages, try http://www.linuxmall.com, http://www.linux.org, or http://www.ssc.com/ (had to put a plug in for the sponsor of the excellent LG).
Date: Tue, 8 Jul 1997 09:10:32 -0700
From: Robert Christ
Subject: Spam Counter Attack
In Linux Gazette #19 you say:
SPAM Counter Attack! If you'd like to have your voice heard regarding SPAM mail, why don't you consider writing a letter to your representative?
I would just like to add a counter point that I would prefer that my congress person not attempt to regulate any aspect of the net. I have the tools and skills to prevent spamming all by myself. Laws regulating behavior seems to set a dangerous precedent..
thanks for your time,
Rob
Date: Sat, 5 Jul 1997 21:25:48 -0600 (MDT)
From: Michael J. Hammel
Subject: User-Level Driver For HP ScanJet 5p?
To:
You asked about HP Scanjet 5P support in Linux. Check XVScan at http://tummy.com. It supports this scanner and is a commercial product.
If you're looking for drivers for other scanners check out my review of scanners in my Graphics Muse column in the March 1997 Linux Gazette (that is in issue 15) at http://www.ssc.com/lg/.
Hope this helps.
Michael J. Hammel
Date: Sat, 5 Jul 1997 21:21:08 -0600 (MDT)
To:
Subject: Problems with XFree86
You wrote to the Linux Gazette:
I'm a new user to Linux and the problem still XFree86! So then I tried to know want can I do to Linux community. In Issue #16, you said that the problem is not video card and is Monitor balancing. So why Windows 95 can have all these preset on monitor and Linux don't have? Why we can't use the stuff in the Microsoft Lib to transfer it into the database of XF86Setup or something like that. Cause that's real that the dotclock and all this is very scrambled! Why not just resolution and Virtual Refresh, that's all we need to know, the program could do the rest! We don't have to know what horizontal frequency and dotclock it is!
Answer: Xi Graphics AcceleratedX 3.1. It does pretty much what you're asking for here. See http://www.xi.com.
Michael J. Hammel
Date: Sat, 5 Jul 1997 21:18:18 -0600 (MDT)
To:
Subject: CD Burners, Scanners, Digital Cameras, etc.
You asked the following in the July Linux Gazette:
1.Will a Sony CDU926S burner work with xcdroast? Don't know about this one, but I may have to find out soon. I'd like to create a CD full of graphics tools, but I've never tried to do anything like this before. If I do find info I'll probably write it up in my Graphics Muse column in the Gazette.
2. What is a good, but cheap flatbed scanner to use? (Good means 24 bit color and >= 300dpi optical resolution.) What software (in Linux) supports the scanner?
Answer: Check my March 1997 Graphics Muse column. I did a review of the scanners currently supported (at that time). A good place to look (which is listed in that issue of the Muse) is the SANE Project.
3.I can't afford one, but... Are there any 35mm slide scanners on the market with Linux support?
Answer:I haven't seen any announced yet. I get info like this alot due to my work with Graphics Tools for Linux, but so far no one has pointed out any web pages or ftp sites for such drivers.
4.And as long as I'm asking dumb questions... Does Linux have support for any digital cameras yet?
Answer:Don't waste your money on these just yet, even if a driver exists (I haven't seen one of these either). Even the vendors have been saying this technology is too new and they haven't established the "rules of the game" for standards or formats. Many are using ordinary JPEG formats, but getting the data to your PC is variable and depends on the makers choice of protocols, connectors and so forth.
Hope this helps a little.
-- Michael J. Hammel
Date: Sat, 5 Jul 1997 21:09:06 -0600 (MDT)
To:
Subject: Interfacing Genius Color Page-CS Scanner
You asked about using your Genius Scanner with Linux. I don't know if a driver is available although in a survey of scanners I did for the Graphics Muse Column (March 1997, Issue 15) of the Linux Gazette there was info on the Genius GS-B105G, Genius GS4500 and probably the GS4000 and GS4500A. Also, there is work being done on generic scanner support for the GIMP and other Linux applications via the SANE project.
I suggest you either look for the author of the Genius scanners to see if support for your particular scanner is forthcoming (assuming yours is from the same manufacturer as his). You should also check with the SANE Project to see if they have any ideas. Both should have pointers on how to write drivers and get info the specs for that scanner if they don't already have it.
One other place to look is http://tummy.com. This is the site for XVScan, a front end to xv that primarily supports HP scanners. They can also write the driver for a fee. XVScan is a commercial product.
-- Michael J. Hammel
Date: Sat, 5 Jul 1997 20:56:53 -0600 (MDT)
To:
Subject: Matrox Mystique support
You wrote to the Linux Gazette:
Is there a chance to correctly configure a Matrox Mystique with 4MB RAM under X or I must throw away it ?
Answer: Xi Graphics AcceleratedX 3.1. I use it with my Matrox Mystique with 4MB RAM. There is a slightly annoying effect you'll see when moving windows (sort of like snow on a TV screen) but its minor and I hardly notice it anymore. They know about it and are working on a fix.
-- Michael J. Hammel
Date: Mon, 14 Jul 1997 13:51:38 -0400 (EDT)
From: Ade Bellini
Subject: Re: *2+ Processing Thank you for your interest and help, i am most pleased to have had so many helpful replies, this just goes to show how many friendly and informed readers the Linux gazette has (? blatant plug for the LG !). I am sorry this reply is in the form of a "shotgun" approach, but i really couldn't reply individually to so many, but to all of you that mailed me -- MANY THANKS. I have "solved" 1/2 the problem - i rebuilt the kernel ( to install sound blaster support) and some how (G-D knows how !) i can now run on *2 cpu but only drawing the affects of 1 !. tur i ur tur as they say in Sweden ! (luck in bad luck !!!). Again thanks for the help and keep on hacking !: Yours ade. Ade Bellini
Date: Sat, 19 Jul 1997 12:24:41 -0700 (MST)
From: Joel Hardy
Subject: Descent 3 for Linux?
Linux has always been the perfect platform for games, it's just very few developers (id and Crack.com are the only two worth mentioning that I know of) know that. Interplay and Parallax are developing the third game in their Descent series, and they're accepting ideas, so I think the Linux community should inform them of the benefits of supporting a Linux version. There have already been several (last estimate I heard was 90) people who have suggested that they support Linux, and they probably will if they're convinced enough people would buy it, so if you're interested in having the best DOS game ported to Linux, see http://www.interplay.com/descent/ideas and suggest Linux support.
-- Joel Hardy
![[ TABLE OF CONTENTS ]](../gx/indexnew.gif)
![[ FRONT PAGE ]](../gx/homenew.gif)
 More 2¢ Tips!
More 2¢ Tips! Boot Information Display
Boot Information DisplayDate: Wed, 2 Jul 1997 18:18:11 -0400
From: Jon Cox
I saw an article in July's LG that talked about using watch as a better way to monitor ftp downloads -- there 's an even BETTER way: Check out ncftp. It works much like ftp, but shows a progress bar, estimates time to completion, and saves bookmarks of where you've been. I think ncftp is pretty standard on all distributions these days.
-Enjoy Jon
Consider Glimpse Instead of GrepDate: Wed, 2 Jul 1997 18:18:11 -0400
From: Jon Cox
While grep works as a tool for searching through a big directory tree for a string, it's pretty slow for this kind of thing & a much better tool exists --Glimpse. It even has an agrep-style stripped down regexp capability for doing "fuzzy search", and is astonishingly fast. Roughly speaking:
glimpse is to grep as
locate is to find
I believe the latest rpm version is glimpse-4.0-4.i386.rpm You can find it in any site that mirrors Red hat's contrib directory.
Enjoy!
-Jon
CopyDate: Wed, 2 Jul 1997 18:18:11 -0400
From: Wim Jongman
I have hacked a helpful utility. Please have a look at it.
Regards,
Wim Jongman
I have been a satisfied diald user for quite some time. one of the things that were on my list of favorites was the possibility to activate the link from another location. I have written a small shell script that waits for activity on my telephone line.
If activity has been detected the script submits the ping utility which causes diald to set up a link to my ISP. If activity is detected from the inside (diald does the dialing) then the ping is also performed but there can be no harm in that.
My /etc/diald.conf looks like this:
mode cslip
connect /usr/local/bin/connect
device /dev/cua2
speed 115200
modem
lock
crtscts
local local.ip.ad.dres
remote ga.te.way.address
mtu 576
defaultroute
ip-up /usr/local/bin/getmail &
ip-down /usr/local/bin/waitmodem &
include /usr/lib/diald/standard.filter
The first time the link goes down, the program waitmodem is submitted. The script for /usr/local/bin/waitmodem is:
#!/bin/bash
# This script waits for data entering the modem. If data has arrived,
# then a host is pinged to allow diald to
# setup a connection (and you to telnet in.)
if test -f /var/locks/waitmodem
then
exit 0
else
touch /var/locks/waitmodem
sleep 5
read myvar < /dev/cua2
ping -c 10 host.com > /dev/nul & > /dev/nul
rm /var/locks/waitmodem
exit 0
fi
If the diald decides to drop the link, the ip-down keyword activates the waitmodem script. This creates a lock in /var/lock(s) and sleeps for five seconds to allow the modem buffers to flush. Then the modem device is read and if activity occurs, the ping is submitted. Change the italic bits in the scripts. The lock is removed and diald dials out. This allows you to access your machine. I guess you have to have a static ip for it to be useful.
Regards,
Wim Jongman
A New Tool for LinuxDate: Wed, 2 Jul 1997 18:18:11 -0400
From: Jordi Sanfeliu
hi !
This is my contribution to this beautiful gazette !! :))
tree is a simple tool that allows you to see the whole directory tree on your hard disk.
I think that is very cool, no?
#!/bin/sh
# @(#) tree 1.1 30/11/95 by Jordi Sanfeliu
# email: [email protected]
#
# Initial version: 1.0 30/11/95
# Next version : 1.1 24/02/97 Now, with symbolic links
#
# Tree is a tool for view the directory tree (obvious :-) )
#
search () {
for dir in `echo *`
do
if [ -d $dir ] ; then
zz=0
while [ $zz != $deep ]
do
echo -n "| "
zz=`expr $zz + 1`
done
if [ -L $dir ] ; then
echo "+---$dir" `ls -l $dir | sed 's/^.*'$dir' //'`
else
echo "+---$dir"
cd $dir
deep=`expr $deep + 1`
search # with recursivity ;-)
numdirs=`expr $numdirs + 1`
fi
fi
done
cd ..
if [ $deep ] ; then
swfi=1
fi
deep=`expr $deep - 1`
}
# - Main -
if [ $# = 0 ] ; then
cd `pwd`
else
cd $1
fi
echo "Initial directory = `pwd`"
swfi=0
deep=0
numdirs=0
zz=0
while [ $swfi != 1 ]
do
search
done
echo "Total directories = $numdirs"
Have fun !
Jordi
Hex DumpDate: Wed, 18 Jun 1997 10:15:26 -0700
From: James Gilb
I liked your gawk solution to displaying hex data. Two things (which people have probably already pointed out to you).
-v: The -v option causes hexdump to display all input data. Without the -v option, any number of groups of output lines, which would be identical to the immediately preceding group of output lines (except for the input offsets), are replaced with a line comprised of a single asterisk.
00000000: 01df 0007 30c3 8680 0000 334e 0000 00ff ....0.....3N.... 00000010: 0048 1002 010b 0001 0000 1a90 0000 07e4 .H.............. 00000020: 0000 2724 0000 0758 0000 0200 0000 0000 ..'$...X........ 00000030: 0000 0760 0004 0002 0004 0004 0007 0005 ...`............ 00000040: 0003 0003 314c 0000 0000 0000 0000 0000 ....1L.......... 00000050: 0000 0000 0000 0000 0000 0000 2e70 6164 .............pad 00000060: 0000 0000 0000 0000 0000 0000 0000 0014 ................ 00000070: 0000 01ec 0000 0000 0000 0000 0000 0000 ................ 00000080: 0000 0008 2e74 6578 7400 0000 0000 0200 .....text....... 00000090: 0000 0200 0000 1a90 0000 0200 0000 2a98 ..............*.
(I don't suppose it is surprising that emacs does this, after all, emacs is not just and editor, it is its own operating system.)
Hard Disk DuplicationDate: Tue, 24 Jun 1997 11:54:48 +0200
From: Jerko Golubovic
A comment on article "HARD DISK DUPLICATION" written by [email protected] in Linux Gazette #18 (June 97).
What I did at my place is following:
I SetUp root-NFS system to boot usable configuration over network. I just need a floppy with appropriate kernel command-line and system brings up.
When system brings up I mount as /root NFS volume where I store compressed images. In that way I have them readily available when I log-in.
With dmesg I find about geometry of the hard disk of the target system. Then, for taking a new image I do:
cat /dev/hda | gzip -9 > <somename>.gz
And for restore:
zcat <somename>.gz > /dev/hda
Of course, I don't have to use such system. It is enough to prepare one boot floppy containing just FTP client and network config. I made two shell scripts:
b: ---------------------- #!/bin/sh cat /dev/hda | gzip -9 r: ---------------------- #!/bin/sh gzip -d > /dev/hda Then, in FTP you do: put |./b <somename>.gz - to save image get <somename.gz> |./r - to restore image
ANY FTP server on ANY platform can be used for storage.
Not only that - you don't have to use FTP at all - you can use smbclient instead - and read directly from Win or Lanman shares - doing basically the same thing.
More on Grepping Files in a Directory TreeDate:Tue, 1 Jul 1997 13:12:34
From: Gene Gotimer
In Linux Gazette Issue 18, Earl Mitchell ([email protected]) suggested
grep foo `find . -name \*.c -print`
as a way to grep files in a directory tree. He warned about a command line character limit (potentially 1024 characters).
Another way to accomplish this, without the character limit, is to use the xargs command:
find . -name '*.c' -print | xargs grep foo
The xargs command accepts arguments on standard input, and tacks them on the end of the specified command (after any supplied parameters).
You can specify where in the command xargs will place the arguments (rather than just on the end) if you use the -i option and a pair of curly braces wherever you want the substitution:
ls srcdir | xargs -i cp srcdir/{} destdir/{}
xargs has a number of options worth looking at, including -p to confirm each command as it is executed. See the man page.
-- Gene Gotimer
More on Hard Disk DuplicationDate: Mon, 23 Jun 1997 08:45:48 +0200
From: Jean-Philippe CIVADE
I've written an utility under Windows 95 able to copy from disk to disk in a biney way. It's called Disk2file. It's findable on my web site under tools. The primary purpose of this utility was to make iso images from a hard disk (proprietary file system) to record them on a cdrom. I've used it yesterday do duplicate a red hat 4.1 installed disk with success. The advantage of this method is this is possible to product a serial of disk very quickly. This utility is written to tranfert up to 10Mb /s. The duplication time for a 540 Mb is about 10 mins.
The way to use it is:
It's referenced as a shareware in the docs but I conced the freeware mode to the Linux community for disk duplication only.
-- Best Regards Jean-Philippe CIVADE
A Script to Update McAfee VirusDate: Fri, 20 Jun 1997 00:05:33 -0500 (CDT)
From: Ralph
Here is a script I hacked together (trust me after you see it I'm sure you'll understand why this is my first script hack I'm sure) to ftp McAfee virus definitions unzip then and run a test to make sure they are ok...now ya gotta have vscan for linux located at ftp://ftp.mcafee.com/pub/antivirus/unix/linux
the first one does the work of pulling it down unzipping and testing
#!/bin/sh
# =====================================================================
# Name: update-vscan
# Goal: Auto-update McAfee's Virus Scan for Linux
# Who: Ralph Sevy [email protected]
# Date: June 19 1997
# ----------------------------------------------------------------------
# Run this file on the 15th of each month to insure that the file gets
# downloaded
# ======================================================================
datafile=dat-`date +%y%m`.zip
mcafeed=/usr/local/lib/mcafee
ftp -n ftp.mcafee.com << !
user anonymous [email protected]
binary
cd /pub/antivirus/datfiles/2.x
get $datafile
quit
!
if [ -f $mcafeed/*.dat ]; then
rm *.dat
fi
unzip $datafile *.DAT -d $mcafeed
for file in $(ls $mcafeed/*.DAT); do
lconvert $mcafeed/*.DAT
done
uvscan $mcafeed/*
exit
---------------------------------------------------------------------------
CUT HERE
lconvert is a 3 line script I stole looking in the gazette
CUT HERE
--------------------------------------------------------------------------
#!/bin/tcsh
# script named lconvert
foreach i (*)
mv $1 `echo $1 | tr '[A-Z]' '[a-z]'`
-------------------------------------------------------------------------
CUT HERE
The last thing you want to do is add an entry to crontab to update your files once a month....I prefer the 15th as it makes sure I get the file (dunno really how to check for errors yet, its my next project)
# crontab command line # update mcafee data files once a month on the 15th at 4am * 4 15 * * /usr/local/bin/update-vscan
Its not pretty I'm sure, but it works
Ralph http://www.kyrandia.com/~ralphs
Handling Log FilesDate: Thu, 3 Jul 1997 11:13:56 -0400
From: Neil Schemenauer
I have seen a few people wondering what to do with log files that keep growing. The easy solution is to trim them using:
cat </dev/null >some_filenameThe disadvantage to this method is that all your logged data is gone, not just the old stuff. Here is a shell script I use to prevent this problem.
#!/bin/sh
#
# usage: logroll [ -d <save directory> ] [ -s <size> ] <logfile>
# where to save old log files
SAVE_DIR=/var/log/roll
# how large should we allow files to grow before rolling them
SIZE=256k
while :
do
case $1 in
-d)
SAVE_DIR=$2
shift; shift;;
-s)
SIZE=$2
shift;shift;;
-h|-?)
echo "usage: logroll [ -d <save directory> ] [ -s <size> ] <logfile>"
exit;;
*)
break;;
esac
done
if [ $# -ne 1 ]
then
echo "usage: logroll [ -d <save directory> ] [ -s <size> ] <logfile>"
exit 1
fi
if [ -z `find $1 -size +$SIZE -print` ]
then
exit 0
fi
file=`basename $1`
if [ -f $SAVE_DIR/$file.gz ]
then
/bin/mv $SAVE_DIR/$file.gz $SAVE_DIR/$file.old.gz
fi
/bin/mv $1 $SAVE_DIR/$file
/bin/gzip -f $SAVE_DIR/$file
# this last command assumes the PID of syslogd is stored like RedHat
# if this is not the case, "killall -HUP syslogd" should work
/bin/kill -HUP `cat /var/run/syslog.pid`
Save this script as /root/bin/logroll and add the following to your /etc/crontab:
# roll log files 30 02 * * * root /root/bin/logroll /var/log/log.smb 31 02 * * * root /root/bin/logroll /var/log/log.nmb 32 02 * * * root /root/bin/logroll /var/log/maillog 33 02 * * * root /root/bin/logroll /var/log/messages 34 02 * * * root /root/bin/logroll /var/log/secure 35 02 * * * root /root/bin/logroll /var/log/spooler 36 02 * * * root /root/bin/logroll /var/log/cron 38 02 * * * root /root/bin/logroll /var/log/kernelNow forget about log files. The old log file is stored in /var/log/roll and gzipped to conserve space. You should have lots of old logging information if you have to track down a problem.
Neil
Exciting New Hint on xterm TitlesDate: Fri, 27 Jun 1997 15:43:44 +1000 (EST)
From: Damian Haslam
Hi, after searching (to no avail) for a way to display the currently executing process in the xterm on the xterm's title bar, I resorted to changing the source of bash2.0 to do what I wanted. from line 117 of eval.c in the source, add the lines marked with # (but don't include the #)
117: if (read_command () == 0)
118: {
#119: if (strcmp(get_string_value("TERM"),"xterm") == 0) {
#120: printf("^[]0;%s^G",make_command_string(global_command));
#121: fflush(stdout);
#122: }
#123:
124: if (interactive_shell == 0 && read_but_dont_execute)
.....
you can then set PROMPT_COMMAND to reset the xterm title to the pwd, or whatever takes your fancy.
cheers - damian
C Source with Line NumbersDate: Sun, 29 Jun 1997 10:09:52 -0400 (EDT)
From: Tim Newsome
Another way of getting a file numbered:
grep -n $ <filename>
-ntells grep to number its output, and $ means end-of-line. Since every line in the file has an end (except possibly the last one) it'll stick a number in front of every line.
Tim
Another Reply to "What Packages Do I Need?"Date: Wed, 02 Jul 1997 20:17:26 +0900
From: Matt Gushee
About getting rid of X components, Michael Hammel wrote that "...you still need to hang onto the X applications (/usr/X11R6/bin/*)." We-e-ll, I think that statement needs to be qualified. Although I'm in no sense an X-pert, I've poked around and found quite a few non-essential components: multiple versions of xclocks (wristwatches are more accurate and give your eyes a quick break). Xedit (just use a text-mode editor in an xterm). Fonts? I could be wrong, but I don't see any reason to have both 75 and 100dpi fonts; and some distributions include Chinese & Japanese fonts, which are BIG, and which not everyone needs. Anyway, poking around for bits and pieces you can delete may not be the best use of your time, but the point is that X seems to be packaged with a very broad brush. By the way, I run Red Hat, but I just installed the new (non-rpm) XFree86 3.3 distribution--and I notice that Red Hat packages many of the non-essential client programs in a separate contrib package, while the Xfree86 group puts them all in the main bin/ package.
Here's another, maybe better idea for freeing up disk space: do you have a.out shared libraries? If you run only recent software, you may not need them. I got rid of my a.out libs several months ago, and have installed dozens of programs since then, and only one needed a.out (and that one turned out not to have the features I needed anyway). Of course, I have the RedHat CD handy so I can reinstall them in a moment if I ever really need them.
That's my .02 .
--Matt Gushee
Grepping Files in a Tree with -execDate: Wed, 2 Jul 1997 09:46:33 -0400 (EDT)
From: Clayton L. Hynfield
Don't forget about find's -exec option:
find . -type f -exec grep foo {} \;
Clayton L. Hynfield
How Do You Un-Virtual a Virtual Screen?Date: Mon, 07 Jul 97 15:08:39 +1000
From: Stuart Lamble
With regards to changing the size of the X screen, I assume you're using XFree86. XFree will make your virtual screen size the larger of: *the specified virtual screen size *the _largest_ resolution you _might_ use with your video card (specified in 'Section "Screen"').
Open your XF86Config file in any text editor (ae, vi, emacs, jed, joe, ...) _as root_. (You need to be able to write it back out again.) Search for "Screen" (this is, IIRC, case insensitive, so for example, under vi, you'd type:
/[Ss][Cc][Rr][Ee][Ee][Nn]yeah, yeah, I know there's some switch somewhere that makes the search case insensitive (or if there isn't, there _should_ be :), but I can't remember it offhand; I don't have much use for such a thing.)
You'll see something like:
Section "Screen"
Driver "accel"
Device "S3 Trio64V+ (generic)"
Monitor "My Monitor"
Subsection "Display"
Depth 8
Modes "1024x768" "800x600" "640x480"
ViewPort 0 0
Virtual 1024 768
EndSubsection
Subsection "Display"
Depth 16
Modes "800x600" "640x480"
ViewPort 0 0
Virtual 800 600
EndSubsection
Subsection "Display"
Depth 24
Modes "640x480"
ViewPort 0 0
Virtual 640 480
EndSubsection
EndSection
(this is taken from a machine I use on occasion at work.)
The first thing to check is the lines starting with Virtual. If you want the virtual resolution to be the same as the screen size, it's easy to do - just get rid of the Virtual line, and it'll be set to the highest resolution listed in the relevant Modes line. (In this case, for 24bpp, it would be 640x480; at 16bpp, 800x600; at 8bpp, 1024x768.) Just be aware that if you've got a 1600x1200 mode at the relevant depth listed, the virtual screen size will stay at 1600x1200. You'd need to get rid of the higher resolution modes in this case.
I would strongly recommend you make a backup of your XF86Config file before you mess around with it, though. It's working at the moment; you want to keep it that way :-)
All of this is, of course, completely incorrect for MetroX, or any other commercial X server for Linux.
Cheers.
File Size Again...Date: Sun, 6 Jul 1997 13:13:29 -0400 (EDT)
From: Tim Newsome
Since nobody has mentioned it yet: procps (at least version 1.01) comes with a very useful utility named watch. You can give it a command line which it will execute every 2 seconds. So, to keep track of file size, all you really need is: watch ls -l filename Or if you're curious as to who's logged on: watch w You can change the interval with the -n flag, so to pop up a different fortune every 20 seconds, run: watch -n 20 fortune Tim
syslog ThingDate: Fri, 04 Jul 1997 14:50:08 -0400
From: Ian Quick
I don't know if this is very popular but my friend once told me a way to put your syslog messages on a virtual console. First make sure that you have the dev for what console you want. (I run RedHat 4.0 and they have them up tty12). Then edit your syslog.conf file and add *.* <put a few tabs for format> /dev/tty12. Reboot and TA DA! just hit alt-F12 and there are you messages logged to a console.
-Ian Quick
Ascii Problems with FTPDate: Mon, 7 Jul 1997 15:59:39 -0600 (CST)
From: Terrence Martin
This is a common problem that occurs with many of our Windows users when they upload html and perl cgi stuff to our web server.
The real fix for this has been available for years in ftp clients themselves. Every ftp client should have support for both 'Binary or type I' and 'Ascii or type 2' uploads/downloads. By selecting or toggling this option to Ascii mode (say in ws_ftp) the dos format text files are automagically translated to unix style without the ^M. Note you definitely do not want to transfer binary type files like apps or programs as this translation will corrupt them.
Regards
Terrence Martin
Running Squake from Inside XDate: Fri, 11 Jul 1997 00:27:49 -0400
From: Joey Hess
I use X 99% of the time, and I was getting tired of the routine of CTRL-ALT-F1; log in; run squake; exit; switch back to X that I had to go through every time I wanted to run squake. So I decided to add an entry for squake to my fvwm menus. To make that work, I had to write a script, I hope someone else finds this useful, I call it runvc:
#!/bin/sh
# Run something on a VC, from X, and switch back to X when done.
# GPL Joey Hess, Thu, 10 Jul 1997 23:27:08 -0400
exec open -s -- sh -c "$* ; chvt `getvc`"
Now, I can just type runvc squake (or pick my fvwm menu entry that does the same) and instantly be playing squake, and as soon as I quit squake, I'm dumped back into X. Of course, it works equally well for any other program you need to run at the console.
Runvc is a one-liner, but it took me some time to get it working right, so here's an explanation of what's going on. First, the open -s command is used to switch to another virtual console (VC) and run a program. By default, it's going to switch to the next unused VC, which is probably VC 8 or 9. The -s has to be there to make open actually change to that console.
Next, the text after the -- is the command that open runs. I want open to run 2 commands, so I have to make a small shell script, and this is the sh -c "..." part. Inside the quotes, I place $*, which actually handles running squake or whatever program you told runvc to run.
Finally, we've run the command and nothing remains but to switch back to X. This is the hard part. If you're not in X, you can use something like open -w -s -- squake and open will run squake on a new VC, wait for it to exit, and then automatically switch back to the VC you ran it from. But if you try this from inside X, it just doesn't work. So I had to come up with another method to switch back to X. I found that the chvt command was able to switch back from the console to X, so I used it.
Chvt requires that you pass it the number of the VC to switch to. I could just hard code in the number of the VC that X runs on on my system, and do chvt 7, but this isn't portable, and I'd have to update the script if this ever changed. So I wrote a program named 'getvc' that prints out the current VC. Getvc is actually run first, before any of the rest of the runvc command line, because it's enclosed in backticks. So getvc prints out the number of the VC that X is running on and that value is stored, then the rest of the runvc command line gets run, and eventually that value is passed to chvt, which finally switches you back into X.
Well, that's all there is to runvc. Here's where you can get the programs used by it:
/* getvc.c
* Prints the number of the current VC to stdout. Most of this code
* was ripped from the open program, and this code is GPL'd
*
* Joey Hess, Fri Apr 4 14:58:50 EST 1997
*/
#include <sys/vt.h>
#include <fcntl.h>
main () {
int fd = 0;
struct vt_stat vt;
if ((fd = open("/dev/console",O_WRONLY,0)) < 0) {
perror("Failed to open /dev/console\n");
return(2);
}
if (ioctl(fd, VT_GETSTATE, &vt) < 0) {
perror("can't get VTstate\n");
close(fd);
return(4);
}
printf("%d\n",vt.v_active);
}
/* End of getvc.c */
I hope this tip isn't too long!
-- see shy jo
Copying a Tree of FilesDate: Fri, 18 Jul 1997 00:33:48 +0200 (SAT)
From:
Hi!
First of all, I want to congratulate you with your fine magazine. Although I've been around for quite some time and known about the existance of LG, I've never had the time (or should I say I have been to ignorant) to read it. Well, I finally sat down and started reading all the issues and I must say I'm impressed. Therefore I decided I would show my gratitude by showing you some of my 2c Tips. Enjoy...
# Quick way to copy a tree of files from one place to another
----< cptree <----
#!/bin/sh
if [ $# = 2 ]
then
(cd $1; tar cf - .) | (mkdir $2; cd $2; tar xvfp -)
else
echo "USAGE: "`basename $0`" <source_directory> <dest_directory>"
exit 1
fi
----< cptree <----
# Quick way to move a tree of files from one place to another
----< mvtree <----
#!/bin/sh
if [ $# = 2 ]
then
(cd $1; tar cf - .) | (mkdir $2; cd $2; tar xvfp -)
rm -rf $1
else
echo "USAGE: "`basename $0`" <source_directory> <dest_directory>"
exit 1
fi
----< mvtree <----
# Rename numeric files (1.*, 2.*, 3.*, etc.) to it's correct numeric
# equivalents (01.*, 02.*, 03.*, etc.). Useful to prevent incorrect wild
# card matching
----< fixnum <----
#!/bin/sh
if [ $# = 0 ]
then
FILELIST=`ls {1,2,3,4,5,6,7,8,9}.mp3` 2> /dev/null
MPFILE="empty"
chmod -x *
for MPFILE in $FILELIST
do
if [ -e $MPFILE ]; then mv $MPFILE "`echo "0$MPFILE"`"; fi
done
fi
----< fixnum <----
# This one strips the given file name from it's extension (i.e. "file.txt"
# would become "file"
----< cutbase <----
#!/bin/sh
if [ $# = 1 ]
then
dotpos=`expr index $1 "."`
if [ $dotpos -gt 0 ]
then
dotpos=`expr $dotpos - 1`
stripfile=`expr substr $1 1 $dotpos`
else
stripfile=$1
fi
echo $stripfile
else
echo " USAGE: `basename $0` <filename>"
exit 1
fi
----< cutbase <----
# If you're desperately looking for a file containing something and you
# don't have a clue where to start looking, this one might be for you.
# It greps through all the files in the given directory tree for the given
# keyword and list all the files. For example: grepall /usr/doc PAP secrets
----< grepall <----
#!/bin/sh
if [ $# = 0 ]
then
DIR="."
else
DIR=$1
shift
find $DIR -type f -exec grep -lie "$@" {} \; | less
fi
----< grepall <----
# You might have seen some of the xterm titlebar tips posted in LG. Here
# is my variation of the theme. I like my xterm to keep it's title that
# I've either specified on the command-line or the name of the program
# and after I've run programs like Midnight Commander, that's changes the
# titlebar, I want it restored to it's old value. Here is my way of doing
# it. Just put the code in /etc/profile or ~/.profile or whatever startup
# file you use...
----< Titlebar 2c tip <----
if [ $TERM = "xterm" -o $TERM = "xterm-color" -o $TERM = "rxvt" ]
then
function TitlebarString()
{
local FOUND=0
local PIDTXT=`ps | grep $PPID`
for WORDS in $PIDTXT
do
if [ $FOUND = 1 ]; then break; fi
if [ $WORDS = "-T" ]; then export FOUND=1; fi
done
if [ $FOUND = 0 ]
then
WORDS=`(for TMP in $PIDTXT;do echo -n $TMP" ";done) | cut -f5 -d" "`
if [ "`echo $WORDS | grep -i xterm`" != "" ]; then WORDS="xterm"; fi
fi
echo -n $WORDS
unset WORDS
}
if [ $COLORTERM -a $COLORTERM = "rxvt-xpm" ]
then
alias mc='mc -c;echo -ne "\033[m\033]0;`TitlebarString`\007"'
else
alias mc='mc -c;echo -ne "\033]0;`TitlebarString`\007"'
fi
fi
----< Titlebar 2c tip <----
# This is an add-on for du. It shows the total disk usage in bytes,
# kilobytes, megabytes and gigabytes (I thought terabytes wouldn't be
# necessary (: )
----< space <----
#!/bin/sh
BYTES=`du -bs | cut -f1` 2> /dev/null
if [ $BYTES -lt 0 ]
then
KBYTES=`du -ks | cut -f1` 2> /dev/null
else
KBYTES=`expr $BYTES / 1024`
fi
MBYTES=`expr $KBYTES / 1024`
GBYTES=`expr $MBYTES / 1024`
echo ""
if [ $BYTES -gt 0 ]; then echo " $BYTES bytes"; fi
if [ $KBYTES -gt 0 ]; then echo " $KBYTES KB"; fi
if [ $MBYTES -gt 0 ]; then echo " $MBYTES MB"; fi
if [ $GBYTES -gt 0 ]; then echo " $GBYTES GB"; fi
echo ""
----< space <----
# A scripty to unzip all zipfiles specified or all those in the current
# directory and remove the orginal ones (Remember that GNU zip/unzip
# doesn't support wildcards)
----< unzipall <----
#!/bin/sh
if [ $# = 0 ]
then
ZIPLIST=`ls *.zip` 2> /dev/null
else
ZIPLIST="$@"
fi
ZIPFILE="garbage"
for ZIPFILE in $ZIPLIST
do
unzip -L $ZIPFILE
done
rm -f $ZIPLIST 2> /dev/null
----< unzipall <----
# Zip all the files in the current directory seperately and wipe the
# original files. Zip's them in a dos style (i.e. hungry.txt would
# be zipped to hungry.zip and not hungry.txt.zip)
----< zipall <----
#!/bin/sh
function stripadd ()
{
local dotpos=`expr index $1 "."`
if [ $dotpos -gt 0 ]
then
dotpos=`expr $dotpos - 1`
local stripfile=`expr substr $1 1 $dotpos`
else
local stripfile=$1
fi
echo $stripfile".zip"
}
function ziplist ()
{
zipfile="garbage"
for zipfile in "$@"
do
zip -9 `stripadd $zipfile` $zipfile
rm $zipfile
done
}
if [ $# -gt 0 ]
then
ziplist "$@"
else
ziplist `ls`
fi
----< zipall <----
Okay, now for some Window manager tips. Since '95 microsoft has launched a '95 keyboard campaign and in the process a lot of people (including me) have ended up with keyboards containing those silly, useless buttons. Luckily I've put them to good use. To give them the same functions in your window manager as in doze 95, just follow the instructions:
Edit ~/.Xmodmap and add the following lines: keycode 115 = F30 keycode 116 = F31 keycode 117 = F32
Now, edit your window manager configuration file and bind those keys. Here is the proper keybindings for fvwm95 and afterstep respectively
# Fvwm95 (edit ~/.fvwm2rc95) Key F30 A A CirculateDown Key F31 A A CirculateUp Key F32 A A PopUp "Utilities" # Afterstep (edit ~/.steprc) Key F30 A A CirculateDown Key F31 A A CirculateUp Key F32 A A PopUp "HotList"
Just remember that PopUp "Utilities" and PopUp "HotList" should be replaced by your actual popup menus. If you don't known what I'm talking about, just browse through your configuration file and read the comments - It'll become clear very soon.
I guess that's all for now. I've got some other (more useful) scripts and tips, but they are either system specific or just to large to include here and if I don't stop now, you'll need a seperate issue just for my tips.
Cheers
ixion
Using shar + RCS to Backup Set of Source FilesDate: Wed, 23 Jul 1997 09:28:24 -0300
From: Mario Storti
Hi, RCS (see rcs(1)) is a very useful tool that allows to store versions of a file by storing only the differences between successive versions. In this way I can make a large amounts of backups of my source files but with a negligible amount of storage. I use it all the time, even for TeX files!! However, when you are working with a set of source files (*.c, shell or Perl scripts, I work mainly with Fortran .f and Octave *.m files) what I want is to make backups of the whole set of files in such a way that you can recover the state of the whole package at a given time. I know that there is a script called rcsfreeze around, but I know that it has problems, for instance if you rename, delete or create new files, it is not guaranteed to recover the same state of the whole set.
I found a solution that seems to be simpler and is working for me: I make a `shar' of the files and then a version control of the shar file. (see shar(1)). Shar is a file that packs a set of text files in a single text file. It has been used since a long time to send set of files by e-mail.
It would be easy to write a script for this, but I prefer to include the shell code in a Makefile. The commands to be issued each time you want to make a backup are:
$ co -l source.shar
$ shar *.m Makefile >source.shar
$ ci -m"save package" source.shar
Here *.m and Makefile is the set of files that I want to backup periodically.
(I want to point out that RCS version control is far beyond the simple fact of making backups: It serves to manage files to be worked by different people, etc... Here I'm using a very small subset of the utilities of RCS.)
Hope this could be of use for someone else. It would be nice also to hear of other solutions,
Mario
Learning ExperienceDate: Wed, 23 Jul 1997 15:53:31 -0500
From: Debie Scholz
If you have a ps2 style mouse and the /dev/psaux gets deleted you must do a MAKEDEV busmice but it doesnt make a psaux it makes a psmouse so you must make a symbolic link to psaux.;
Debie Scholz
Sirius Systems Group, Inc.
LG #19, Grepping Files CommentsDate: Wed, 30 Jul 1997 08:35:46 +0200 (MET DST)
From: Werner Fleck
Hi!
I have read all the 2c tips on grepping files in a directory tree but I think all missed the ultimate tool for this: a perl script named ``mg''. With this you can:
Although it is written in perl it is very fast - I used it now for many years and it works wonderful for me.
FTP search results
Hardware by Opticom ASA, ITEA and IDI. Network by UNINETT. This server is located in Trondheim, Norway
"Exact search" for "mg-2.16"
1 -r--r--r-- 38.8K 1996 Oct 2 ftp.nuie.nagoya-u.ac.jp /languages/perl/sra-scripts/mg-2.16 2 -rw-r--r-- 38.8K 1995 Nov 16 ftp.et-inf.fho-emden.de /pub/.mnt2/perl/sra-scripts/mg-2.16 3 -rw-r--r-- 38.8K 1996 Oct 3 ftp.hipecs.hokudai.ac.jp /pub/LANG/perl/utashiro/mg-2.16 4 -rw-r--r-- 38.8K 1997 Mar 4 ftp.st.ryukoku.ac.jp /pub/lang/perl/mg-2.16 5 -r--r--r-- 38.8K 1996 Oct 2 ftp.elelab.nsc.co.jp /pub/lang/perl/scripts.sra/mg-2.16 6 -r--r--r-- 38.8K 1996 Oct 3 ftp.sra.co.jp /pub/lang/perl/scripts/utashiro-scripts/mg-2.16 7 -r--r--r-- 38.8K 1996 Oct 3 ftp.sra.co.jp /pub/lang/perl/sra-scripts/mg-2.16 8 -rw-r--r-- 38.8K 1995 Nov 16 ftp.fujitsu.co.jp /pub/misc/perl/sra-scripts/mg-2.16 9 -r--r--r-- 38.8K 1996 Oct 2 ftp.eos.hokudai.ac.jp /pub/tools/sra-scripts/mg-2.16 9 reported hits 0.018 seconds prospero 0.018 seconds HTTP 0 partial writes. DONE
FTP search, Copyright � 1994-1997 Tor Egge
Greetings, Werner

 |
Contents: |
 SAL--Scientific Applications on Linux
SAL--Scientific Applications on LinuxIf you are looking for a great collection of software information relating to science and engineering be sure to take a look at SAL -- the Scientific applications on Linux page. The page contains broad converage of different advancements adn points of interest in the Linux community. There are currently 1250 software entries at the SAL page! Luckily if you are looking for something specific, you may choose to search the Linux Applications. There are also sections which will help you find what you need. There are sections from Mathematics to Office Software and Numerical Analysis to Computer Graphics. Not only can you roam around the page looking at all of the applications, but you have a chance to make contributions of your own to the page. Don't miss the new and improved SAL at http://SAL.KachinaTech.COM. You'll be happy you visited.
Readers' Choice AwardsVote in Linux Journal's 1997 Readers' Choice Awards!
Linux Journal, the Premier Linux Magazine, is conducting its annual poll of Linux users. Vote for your favorites in twenty different categories including: Most desired upgrade, favorite shell and most indispensible Linux book.
The voting will take place on the Linux Journal web site from July 11th through August 26th. To place your vote simply go to http://www.ssc.com/lj/readchoice.html and follow the directions there. Please do not submit more than one form because all duplicate entries will be deleted.
Results will be published in the December issue of Linux Journal (on newsstands early November).
Subscriptions to Linux Journal are available by calling our toll free number (in the US/Canada) 888 66 LINUX or over our web page at http://www.ssc.com/lj/.
Check Out This Site!Take a look at http://www.m-tech.ab.ca/linux-biz. This page contains a list of commercial sites that use Linux for business. Check out all of the Linux users at work!
Evolution SchedulerCheck out Evolution Scheduler. The Evolution Scheduler is based on Genetic Algorithms and Evolutionary Programming. This scheduler can live with original Linux priority scheduler. This means you don't have to reboot to change the scheduling policy. You may switch between them at any time just by a simple command, say,
esep -cp 3.
A manager program esep(Evolution Scheduling and Evolving Processes), with which you can do scheduling administration job is provided.
If you are interested, see http://sunsite.unc.edu/pub/Linux/kernel looking for "esep-1.2.tgz" and "esep-1.2.lsm" or visit Jinlong Lin's homepage at http://www.iit.edu/~linjinl/esep.html
Alien Apache-SSL GNU Midnight CommanderThe GNU Midnight Commander is a Unix file manager and shell, useful to novice and guru alikes. Version 4.0 has many enhancements. See http://mc.blackdown.org/mc4 for the list of seventy download sites
GNU Midnight Commander is also included on most CD-ROMs containing GNU software and we expect the publishers of these CD-ROMs to include MC version 4.0 when they publish a next version of their CD-ROM.
See also the GNU Midnight Commander website at http://mc.blackdown.org/mc/
WatchdogWatchdog is a daemon that checks if your system is still working. If programs in user space are not longer executed it will reboot the system.
A few new features in 3.0 include:
Watchdog is available from: tsx-11.mit.edu /pub/linux/sources/sbin sunsite.unc.edu /pub/linux/system/daemons ftp.debian.org /pub/debian/development/source/misc
As of the end of July, O'Reilly and Associates have the domain http://www.oreilly.com. The company figured it would be easier to remember than their previous domain. Check out their site!
 The Answer Guy
The Answer Guy  Security Issues
Security IssuesFrom: Marcus Hufvudsson
Greetings Linux guru!
I recently read the Linux Journal May edition and some people had some serious security problems. I got some of them to, and in your answer to one you recommended the "Tripwire" program for more security. I hope you don't mind me mailing you (got the address from the article). Anyway you recommend ftp.cs.perdue.edu for downloading. But when I tried to connect it didn't respond. Do you know any mirrors or any other ftp that contains Linux security tools?
 - talos (root today, gone tomorrow)
- talos (root today, gone tomorrow)
There was a typo in that article. It WAS supposed to be ftp.cs.purdue.edu -- but is now supposed to be at ftp://coast.cs.purdue.edu/pub/COAST (they've been moved).
Here's the full URL to Tripwire: ftp://coast.cs.purdue.edu/pub/COAST/Tripwire
You should definitely browse around and read some of the other papers -- and try some of the other tools out there at the COAST (computer operations and security tools?) archive.
Sadly it seems to be neglected -- the whole "tools_new" tree is dated "October, 1995" and is empty.
All of the good stuff there is under: ftp://coast.cs.purdue.edu/pub/tools/unix (including symlinks that lead back to the Tripwire package).
Apparently they don't do anything with the FTP site because the real work as gone into their web pages at: http://www.cs.purdue.edu/coast/archive/Archive_Indexing.html
Another more recent effort which will be of more direct interest to Linux admins is: http://skynet.ul.ie/!flynng/security/The Irish Computer Security Archives ... with the following being of particular interest: http://skynet.ul.ie/~flynng/security/bugs/linux/ ... and: http://skynet.ul.ie/~flynng/security/tools
Another good site (recently moved) is at: http://www.aoy.com/Linux/SecurityThe Linux Security WWW ... where I particularly like: http://www.aoy.com/Linux/Security/OtherSecurityLinks.html
One of these days I'm going to annotate the 600 or so links in my main lynx_bookmarks file and post it to my own web pages. But -- not this morning (3 am).
I spend so much time doing TAG (The Answer Guy) and other mailing list and newsgroup stuff that I never get to my own web pages. However the patch that I created to allow Tripwire to compile cleanly under Linux is on my ftp site and a link can be found somewhere under http://www.starshine.org/linux/ (I really have to organize those pages one of these days).
-- Jim
All Those Little % ThingiesTo: Jonathan Albrecht
When setting your prompt or dates or app-defaults you sometimes need those little %N, or %d, or %m substitution thingies. What are they and where can I get a list of what they mean?
They are "replaceable parameters" and are used by a variety of shells and applications.
They differ for each shell or application. For example I use bash -- and my prompt is:
PS1=[\u@\h \W]\$
Which looks like:
[jimd@antares jimd]$
When I'm in my home directory and logged in as jimd and would look like:
[root@main local]#
If I was 'root' on the host "main" and in the /usr/local directory.
zsh, and tcsh also have similar "meta sequences" for their shell prompts. Just read the man pages for your shell and search for "prompt."
X app-default and other xrdb (X Windows resource database) entries are pretty mysterious to me. But I imagine that the info about these sequences is mostly in their man pages somewhere. I'm sure it's all in the sources.
The %d syntax is most often seen in the C programming language's printf() and scanf() functions. There are various "format specifiers" that dictate how a particular argument will be formatted. This includes information about whether a value will be displayed as a decimal number, a string, a hexadecimal value -- and how wide the field will be, whether it will be left or right justified -- etc. The \c syntax is also used in C for inserting "non-printing" characters -- like newlines, tabs, and for specifying ASCII characters by octal or hexadecimal value.
Since programmers are used to this syntax in their code they often use a similar syntax when they write scripting languages (shells) and when they design the configuration file syntax for their applications.
I'm sorry there's no "single source" or reference of all of these. However there isn't. You'll just have to hunt through the docs and man pages for easy of the apps and utilities that you're interested in.
Follow-up To NT and Linux ArticleFrom: Cyrille Chepelov
So far I've had the good sense to stay away from striping under NT and Linux. I've heard that the ccd code for FreeBSD is pretty stable, though.
Well, my linux partition is used <5% of the overall time, but sometime I need it to figure things -- once the "small" problem with disks ID was solved, there are no cohabitation problems between NT and Linux.
This sounds like a typically ignorant design decision. It seems to say to the world:
"Standards are for weaklings -- we don't need to follow them -- even when we created them!"
Sure, even if they did it unilaterally, it was up to them to at least loudly publicize what they did.
I disagree. "Unilateral" is completely anathema to "Industry Standards." It is totally arrogant to speak for an industry.
(We won't cover the issue of government regulatory bodies making determinations in a "unilateral" way -- since those aren't "industry standards" they are "government regulations").
Publicizing that you are violating industry standards doesn't improve interoperability. What other reason is there to create and publish a "standard" (even an ad hoc one).
If they think there's a real need to put proprietary information in the very first sector of the disk (the spot reserved for the MBR -- then perhaps they should announce that these disks won't have PC partitions at all. It then becomes a "all NT or nothing" decision for each disk.
I don't think there is such a need -- and I think their approach displays either a gross lack of consideration, creativity and foresight -- OR -- a deliberate act of hostility to those unruly customers who would dare use any "other" operating systems on "their" NT boxes (or maybe a little of each -- some from the programmers and some of the QA teams).
Microsoft can cop out with a line like: "We don't intend that NT Servers should be installed systems with other operating systems -- it is intended for dedicated systems."
It would irritate me. But I'm not one of their "important" customers anyway. Since most platforms outside of the PC market have an OS that's supplied by the vendor -- there isn't an expectation that those system will allow multiple operating systems to co-exist on the system (much less on the same drive).
However, in the PC market there is that expectation -- and has been for over fifteen years. IBM and Microsoft created that expectation (to co-exist with CP/M-86 and the UCSD p-system if my memory and reading of the history is correct).
Naturally the obvious place to put this sort of information would be in the logical boot record (what Unix/Linux refers to as a "Superblock"). This would only cost NT's code a few extra disk seeks at boot time -- seeks that it has to do anyway.
The reason (IMHO) why they put it in the MBR is that even an unpartitioned disk gets its ID. The ID is here for the disk, not the partition -- so it makes less sense to put it in the S-block (even if that sounds safer, cohabitation-wise. Those IDs are what they are -- disk IDs, not partition IDs.)
Classically an OS should ignore an unpartitioned disk. Why should the disk have an ID if it has no partition? If the purpose is to provide unique identification of filesystems so that the striping and mounting mechanisms won't fail as new drives are added to the system -- then you need a partition ID -- and you don't care about disk ID's at all. Additionally you want enough information stored in that ID to minimize the chance of inadvertent duplication and collision (for cases when we move a drive from one system to another).
Finally your mounting/mapping utilities should be robust enough to allow you to mount any of these stripe segments and get what you can off of them.
This sounds robust. NOT! Just what I want -- double the failure points for every volume.
Regardless of the OS, whenever you stripe, you double the possibility of not being able to mount. Not mounting at all (or mounting read-only) when something goes wrong can not be a blamable decision ! (and in the case of striped sets, mounting r-o makes little sense, since all structures are dispatched on both disks)
I can certainly "blame" a company for any deficiency that I perceive in their software. I select software to meet *my* requirements. Therefore I am the ultimate judge of what is a "deficiency."
My requirements for striping say that the loss of one segment or element in a striped set should not entail the loss of the data on the remaining segments. If no currently available striping system meets that requirement I'll avoid the use of the technology.
This means that a striping system should distribute "superblocks" and inode and directory entries in such a way as to keep them localized to the same segment as the data to which they apply (or duplicated on all segments).
(I realize that duplicating directory information on all segments may be costly -- and I understand that data files may cross multiple segments. Those are implementation details for the author(s) of the file system).
Out of curiosity: How many different striping systems have you used? The phrase "Regardless of the OS" seems awfully broad.
I will plead complete inexperience with them. My take on the term is that it refers to any technique of making multiple drives appear as a single file system (or volume) that doesn't involve redundancy (RAID) or duplication (mirroring/duplexing).
Is there a standard that specifies more implementation details? (i.e. does my set of requirement some how NOT qualify as a "striping" system).
Well, now that Microsoft has "spoken" we're probably all stuck with this [expletive omitted] forever. Please consider mailing a copy of your message and your patches to the LILO and fdisk maintainers.
The problem is : where are they (I tried to send it once, a few month ago, to an address which was given me as W. Almesberger's, but to no avail).
In my fdisk man page I see the following (under Authors):
. v1.0r: SCSI and extfs support added by . v1.1r: Bug fixes and enhancements by Rik Faith, with special thanks to . v1.3: Latest enhancements and bug fixes by A. V. Le Blanc, including the addition of the -s option. v2.0: Disks larger than 2GB are now fully supported, thanks to Remy Card's llseek support.
So it would seem that Rik Faith, Mr. Le Blanc, Michael Bischoff would be good choices.
The address I see for Werner Almesberger is: (from the lilo (8) man page).
If that gets no response than I'd post notes to comp.os.linux.development to see who is maintaining the code.
--Jim
ActiveX for Linux/UnixFrom: Anders Karlsson
Hi, I read an article in the Linux Gazette where the author hadn't found any evidence for the rumors about ActiveX for Unix. By mistake I found a press release from M$ about this.
I believe what I said was that I had heard the same rumor -- but that the search engine at www.microsoft.com couldn't find any reference to Linux at all.
I don't know who (if any) is interested in this, but you can find it on: http://www.microsoft.com/corpinfo/press/1997/mar97/unixpr.htm
Yes. I see. This basically says that the job was farmed out to Software AG (http://www.sagus.com) which has a release schedule at:
DCOM Availability Schedule http://www.sagus.com/Prod-i~1/Net-comp/dcom/dcom-avail.htm
Let's hope that this isn't the beginning of a new M$-invasion, against a new platform or market, our Linux.
Luckily there's not much MS can do about Linux. They can't "buy it out." -- They can pull various stupid stunts (like tossing new values into partition tables, trashing ext2 filesystems, even exerting pressure on hardware manufacturers to develop and maintain proprietary adapters that require Microsoft written drivers). These will just make them less interoperable. IBM tried stunts like this in the early days of the PC cloning.
However I think the cat is out of the bag. All we as a community have to do is clearly continue our own work. When you buy a new computer -- as for Linux pre-installed (even if you plan on re-installing it yourself). If you don't plan to use Windows '95 or NT on it -- demand that it not be included in the price of your system and -- failing that -- VOTE WITH YOUR FEET!
Recently I saw an ad on CNN for Gateway. The ad went on about all the options that were available and encouraged me to call for a custom configured system. Since I'm actually looking at getting a small system for my mother (no joke!) I called and asked if they could pre-install Linux.
Now I will hand it to the sales dude -- he didn't laugh and he didn't stutter. He either knew what I was talking about or covered up for it.
Naturally the answer was: "No. We can't do that."
There are places that can. Two that come to mind are:
(Warning for Lynx users -- both of these sites use frames and neither bothers to put real content in the "noframes" section -- Yech!)
There are several others -- just pick up any copy of Linux Journal to find them.
Granted this is a small niche now. However, it's so much more than any of us back in alt.os.linux (before the comp.os.linux.* hierarchy was established) thought was possible just four years ago.
Even two years ago the thought of buying a system and putting Linux on it -- to send to my MOTHER (literally, NO computer experience) would have been totally absurd. Now it's just a little bit of a challenge.
What's exciting to me is the prospect that Linux may make it mostly irrelevant what hardware platform you choose. Linux for the Alpha, for SPARC, and mkLinux for PowerMacs gives us back choices -- at prices we can dream of.
It's easy to forget about the hardware half of the "Wintel" cartel. However, the hardware platform has had severe design flaws from the beginning. Hopefully we'll see some real innovation in these new hardware platforms. [The introduction of the IBM PC back in '81 caused the "great CP/M shakeout." It also caused me to take a 5 year hiatus from the whole industry -- out of disgust with the poor design of the platform. Even as a high school student I saw these flaws]
-- Jim
Mounting Disks Under RedHat 4.0From: Bruce W. Bigby
Jim Dennis wrote:
The really important question here is why you aren't asking the support team at RedHat (or at least posting to their "bugs@" address). This 'control-panel' is certainly specific to Red Hat's package.
Well, I've tried communicating with RedHat and had problems. I registered and everything and tried to get support via e-mail. Something went wrong, although I followed their instructions, for reporting problems, exactly. At the time, I was at work when I read your web page and decided to give you a try. Thanks for all of the information!
I hope it helped. I too have been unsatisfied with Red Hat's level of support. Not that I expect alot of complex personal attention for a package that only costs $50 -- but I was calling representing the US Postal Service's Data Processing Center -- and I was willing to put up about $50/hr for the support call(s).
Alas they just didn't have the infrastructure in place.
Yggdrasil has a 900 line for support -- and Adam Richter has been doing Commercial Linux longer than just about anyone else (SLS might have been there earlier -- but I haven't heard anything about Soft Landing Systems in years).
Yggdrasil also publishes _The_Linux_Bible_ and has a video cassette tutorial on Linux. Unfortunately I haven't installed a copy of their distribution, Plug and Play Linux, for a couple of years. Slackware and later Red Hat seem to have won the popularity contest in recent years -- and
Unfortunately I've never used Yggdrasil's tech support services. So I can't give a personal recommendation. They do have two pricing plans ($2.95/min. US or $100 (US) for one "guaranteed" issue resolved) and they do mention that the support is available to Linux users regardless of what distribution you're using.
Usually I've managed to bang my head on problems hard enough and long enough that they crack before I do. So I haven't needed to call yet. One would hope that -- with my "reputation" as "The Answer Guy" -- I'd be able to stump them. However Adam Richter has been at this a lot longer than I have -- and was selling Linux distributions before I'd even heard of Linux -- when I was barely starting to play with a used copy of Coherent. So, maybe the next time I have a headache I'll give them a call. I think I'm still entitled to one freebie for that subscription to Plug & Play from a couple of years ago.
Meanwhile, if anyone else has used this service -- or has been using any other dial-in voice support service for Linux -- please let me know. I'll try to collate the opinions and post them in an upcoming issue of LG.
For details look at: http://www.yggdrasil.com/Support/tspolicy.html
[Note: I don't have any affiliation with Yggdrasil or any other Linux vendor -- though several of them are located within a few miles of my home and I do bump into principals for a couple of them at local users groups and "geek" parties]
Another company that offers Linux (and general Unix) support and consulting is Craftworks I've worked with a couple of their consultants before (when I was a full time sys admin and they were providing some on site expertise to handle some overflow). They don't mention their prices up front (which forces me to suspect that they are at least as expensive as I am). I'm also not sure if they are available for short term (1 and 2 hour) "quickshots."
I suppose I should also mention that I'm the proprietor of Starshine Technical Services. My niche is providing support and training for Linux and Unix system's administrators. I also offer off site support contracts (voice, and dial-up or via the Internet using ssh or STEL). Normally I don't "push" my services in my contributions to Linux Gazette -- I just do this to keep me on my toes.
-- Jim
PPP ProblemsFrom: Chris Bradford
I have tried and failed to get a fully working ppp link up with GTE Internet Services. When I start pppd manually after dialing in using MiniCom, it'll start the link, and ifconfig shows that it's up and running. However, when I try to ping any site other than the peer, I get a 'Network Unreachable' error on every single packet that ping tries to send out. I'm using Slackware 3.2 w/ pppd v2.2f on a 486SX w/ 8MB of RAM and a 14.4K bps modem on /dev/cua3.
What's your advice to me?
What does your routing table look like? (Use the command netstat -nr to see that).
Your ppp options file (usually /etc/ppp/options) should have a default route directive in it. That will set the ppp0 link as your default route.
That's usually what "network unreachable" means.
You'll also need to have a proper value in your /etc/resolv.conf. This is the file that your "resolver libraries" use to figure out what DNS server they should ask to translate host/domain names into IP addresses. Basically all applications that do any networking under Unix are linked with the resolver libraries.
-- Jim
Z ProtocolFrom: Gregor Gerstmann
Hi Mr. Jim Dennis,
Thanks for your e-mail remarks in reply to my remarks regarding file transfer with the z protocol in Linux Gazette issue17, April 1997. In the meantime I received an e-mail that may be interesting to you too:
Hello!
I noticed your article in the Linux Gazette about the sz command, and really don't think you need to split up your downloads into smaller chunks.
The sz command uses the ZMODEM protocol, which is built to handle transmission errors. If sz reports a CRC error or a bad packet, it does not mean that the file produced by the download will be tainted. sz automatically retransmits bad packets.
If you have an old serial UART chip ( 8250 ), then you might be getting intermittent serial errors. If the link is unreliable, then sz may spend most of its time tied up in retransmission loops.
In this case, you should use a ZMODEM window to force the sending end to expect an `OK' acknowledgement every few packets.
sz -w1024 Will specify a window of 1024 bytes.
I'm familiar with some of the tweaking that can be done -- and the fact that it is a "sliding window" protocol. However I still maintain that Kermit is more reliable and gets better overall throughput over an unreliable connection.
Also ZModem is designed for use on 8-bit serial lines. Kermit can be used easily over TCP connections and on 7-bit serial connections. You could definitely use the C-Kermit package from Columbia University however. The Kermit implementations from other sources are usually reliable enough -- but slower than molasses compared to the "real" thing.
Video CardsFrom: Pedro Miguel Reis
Hi Jim. I have a simple question to you :) ! How can i put my video card to work under Linux ? Its an Intel Pro-share. I would like to save a jpg pic every 1 or two secs.
Thx for your time.
The Intel ProShare is a video conferencing system. These are normally not called "video cards" in the context of PC's because the phrase "video cards" is taken to refer to one of the cards that drives your video display for normal applications and OS operations (i.e. a VGA card).
There are several framegrabbers that are supported under Linux. However it doesn't appear that the Intel ProShare is supported under any for of Unix. Of course that's just based on a few searches of their web site -- so it's not from a very reliable source on the subject. (I swear, the bigger the company the worse the support information on their web site. You'd think they'd like to trim some of the costs of tech support that their always griping about).
Naturally you should contact their support department to verify this (or be pleasantly surprised by its refutation).
Here's a couple of links I found that are related to video capture using CU-SeeMe (a competing technology to Intel's ProShare):
Basically CU-SeeMe uses "off the shelf" video cams -- like the Connectix QCam (which goes for about $100 in most places). It also uses any of several sound boards.
Unfortunately the simple answer to your question may bd desktop camera.
-- Jim
Linux and Zip DrivesFrom:
Can you tell me if it is possible to set up a Linux system on a Zip disk and where I could find info on doing this? I found a file that
It should be possible. I don't know where you'd find the info, though. I'd start by looking at the Linux HOWTO's collection. There is a HOWTO on Zip Drives with Linux (even the parallel port version is supported).
I'd look at putting DOSLinux on an MS-DOS formatted (FAT) Zip disk. DOSLinux is a very small distribution (about 20Mb installed) which is designed to be installed on a DOS filesystem. It uses LOADLIN.EXE (which I've described in other "Answer Guy" articles) which basically loads a Linux kernel from a DOS prompt -- and kicks DOS out from under itself.
You can find that collection of HOWTO's at: http://sunsite.unc.edu/LDP/HOWTO/ (and various mirrors).
You can also find a copy of DOSLinux at 'sunsite' and most mirrors.
I use DOSLinux on my laptop (an OmniBook 600CT) and my only complaint has been that it wasn't configured to support the power management features of my laptop.
Frankly I'm not even sure if Linux' APM support will work with the Omnibook at all. I've heard that the PCMCIA adapter is basically too weird for them (which is a real bummer to me).
You have to watch out if you get a copy of DOSLinux. The maintainer, Kent Robotti, has been making frequent sometimes daily changes to it (or was a couple of months ago).
describes this process IF you have a pre-existing Linux system to install from. I am running a Win95 system with absolutely no hard drive space available. Thanks for any info.
Are you sure you can't even squeeze twenty or thirty meg? With that you can get DOSLinux installed on your normal hard drive -- which is likely to offer much more satisfactory performance. The ZIP drive is likely to be a bit too slow at loading programs, share libraries and DREADFUL if you do any swapping.
Of course if you boot Linux from a Zip disk (or using the "live filesystem" offered by some CD's) you can mount your DOS (Windows '95) partition(s) and create a swap file there.
Although most people use swap partitions -- Linux will allow you to create swap *files* (see the 'mkswap' and 'swapon(8)' man pages for details).
Note: since you don't have a copy already installed I realize that you don't have the man pages handy -- however you can read those man pages by looking at: http://www.linuxresources.com/man.html
The 'swapon(8)' refers to the man page that's in section 8 (system administration tools) of the system. That's necessary because there's also a man page in section 2 (system calls) which the man command will normally display in precedence to the one you want. So you use a command of the form 'man 8 swapon' to tell the manual system which one you mean. This is unnecessary with most commands since most of the ones you'd be looking for -- most of the time -- would be the "user commands" in section one. Also most of the administrative commands, like mkswap, don't have functions with a conflicting name. This is just one of those quirks of Unix that old hands never think of while it gets novices climbing the walls.
When you use the online man pages at ssc.com (the publisher of the Linux Journal and the Linux Gazette) the form is a little confusing. Just check the "radio button" for "( ) Search for a command" and put "8 swapon" (a digit eight, a space, and the word "swapon") in the text field (blank). Ignore the "Section Index" and the section selector list below that.
Lastly, I'd like to make a comment about running Linux with "absolutely no disk space"
DON'T!
With hard disks as cheap as they are now it doesn't make any sense to try to learn an advanced operating system like Linux without plenty of disk space. Buy a whole hard disk and add it to your system. If you already have two IDE drives -- see if your controller will support four. Most EIDE controllers have two IDE channels -- which allow two IDE drives each on them. If you have a SCSI controller than it seems *very* unlikely that you'd have the whole chain full.
(My old 386 has an old Adaptec 1542C controller on it -- with three hard disks, a magneto optical, a DAT autochanger tape drive, a CD drive and a CD writer. That's full! But, while other people have been buying 486's, then DX2's, then Pentiums, and upgrading their copies of Windows and Office -- I've been filling out my SCSI chain -- so that's a five year accumulation of toys!)
If you really can't afford $200 on a new hard drive -- ask around. You might find a friend with a couple of "small" (200 Mb) drives around that they can't use. I have a couple myself (spare parts drawer).
If you try to run Linux with no disk space you probably won't be satisfied. You can install a base system (no X Windows, no emacs, no kernel sources, no dev. tools, no TeX) in a very limited disk space. That's fine if you know exactly what the system is going to be used for. It's perfect for routers, gateways, and terminal servers -- and I see people putting together a variety of custom "distributions" for these sorts of dedicated tasks. I've even heard that some X Terminals (diskless workstations) use Linux with etherboot patches. In ;login (the magazine for members of USENIX/SAGE -- professional associations of Unix users and Sys Admin's) someone described their use of Linux as a method for distributing software updates to their Win '95 boxes across their networks. Apparently they could squeeze just enough onto a Linux boot floppy to do the trick.
However, I'm guessing that your intent is to learn a new OS. For that you want a more complete installation -- so you can play with things.
-- Jim
Red Hat CD ProblemFrom: Vivek Mukherji
I bought a book on linux titled "Using Linux,Third Edition by Que Inc." It had Redhat CDROM with it, but when i tried to install it, it did not recognize the REDHAT CD though it previously made the boot disk and supp disk from the CD. It gave the following error after asking me for source of media i.e. from which drive or local CDROM or FTP or NFS I am going to install it.The error message was: "That CDROM device does not seem to contain Redhat CD in it "
There seems to be no damage on the CD i.e. no physical damage.I think there must be some other way to install it after all i have paid US$ 60 Dollars for that book. please reply me soon.
yours truly
Vivek Mukherji
When you select "CD-ROM" as your installation medium -- what interface are you having the setup program attempt to use?
When you use the CD to create your boot and supplemental diskettes you are presumably using DOS -- which has its own drivers to access the CD.
There are many sorts of CD-ROM drives:
CD-ROM and tape drive support came a few years after the IDE interface became popular for hard drives. ATAPI is an ad hoc standard between those interfaces and these other types of drives. It is an "applications programming interface" to which the drivers must be written. Typically all support for ATAPI CD-ROM and tape drives must be done in software.
EIDE is a set of enhancements to the IDE spec. The most notable enhancement is the ability to support drives larger than 528Mb (which was the old BIOS limit of 1024 cylinders by 63 sectors by 16 heads). This is usually done via extended ROM's on the controller, or enhanced BIOS ROM's on the motherboard -- or possibly via software drivers (which are OS specific, naturally).
In addition to those to types of CD-ROM drive there are a variety of proprietary interfaces such as the Mitsumi (very popular for a while -- as it was the cheapest for a while), Sony, Wearnes/Aztech, and others.
Linux supports a very wide variety of these interfaces. However -- it's vital to know what you have. You also might need to know "where" it is. That is to say you might need to know I/O port addresses, IRQ's, DMA settings or parameters. You might also need to pass these parameters along to the kernel as it boots.
Another issue is the version of your distribution. Most books are printed in large batches -- so they have a long "shelf life." Most Linux distributions change a couple of times a year. Red Hat, in particular, seems to be putting out a new version every 2 or 3 months. Most of these include significant improvements.
So your money is probably much better spent on the distribution itself rather than trying to get a "bargain" in a book and CD combination. Specifically I recommend buying any book solely on it's merits. I don't approve of CD's full of software included with a book unless the software has been stable for some time.
CD's with sample code, HTML and searchable text copies of the books contents, clip art or fonts related to the book, even large bookmark files of related web sites, custom software by the authors -- those are all excellent ideas; otherwise it's shovelware that adds a buck to the production costs (fifty cents for the CD and another fifty cents for the little glue-on vinyl holder and the additional handling) -- and twenty bucks to the price.
So, another thing to try is a copy of the latest Red Hat (4.2) or Debian or whatever. In any event you really need to know the precise hardware and settings for your machine.
-- Jim
CookiesFrom: Michael Sokolow
Dear Ladies and Gentlemen,
Given the previous discussion about cookies, could someone explain to me (or point out a topic in help, URL, etc.) just what ARE cookies?
Search the Netscape web site.
Here's an independent answer courtesy of "The Answer Guy" (Linux Gazette's nickname for me):
In programming terminology -- specifically in discussions of networking protocols (such as HTTP and X Windows) a "cookie" is an arbitrary data token issued by a server to a client for purposes of maintaining state or providing identification.
Specifically "Netscape HTTP Cookies" are an extension to the HTTP protocol (implemented by Netscape and proposed to the IETF and the W3 Consortium for incorporation into the related standards specifications).
HTTP is a "stateless" and protocol. When your browser initiates a connection and requests a document, binary or header the server has no way of distinguishing your request from any other request from your host (it doesn't know if you're coming from a single-user workstation, or a multi-user Unix (or VMS, MVS, MPE, or whatever) host -- or the IP address that it sees as the source for this request is some sort of proxy host or gateway (such as those run by CompuServe and AOL).
Netscape cookies are an attempt to add and maintain state between your browser and one or more servers. Basically on your initial connection to a "cookie generating" site your browser is asked for a relevant cookie -- since this is your initial connection there isn't one -- so the server prefers one to your browser (which will accept it unless it's not capable of them, or some option has been enabled to prevent it or prompt you or something like that). From then on all other parts of that site (and possibly other hosts in that domain) can request your cookie and the site's administrators can sort of track your access and progress through the site.
The main advantage to the site is for gathering marketing statistics. They can track which versions of a web page lead to increased traffic to linked pages and they can get some idea how many new and repeat visits they're getting. (Like most marketing efforts at statistics there are major flaws with the model -- but the results are valid enough for marketdroids).
There are several disadvantages -- including significant privacy concerns. There are several tools available to limit the retention and use of cookies by your browser (even if you're using Netscape Navigator). PGP Inc (the cryptography company) has a link on their site to one called "cookie cutter" (or something like that).
About the only advantage to some users is that some sites *might* use cookies to help you skip parts of the site that you've already seen or *might* allow you to avoid filling in forms that you've already filled out.
Personally I think cookies are a poorly chosen way to do this -- client-side certificates (a feature of SSL v. 3.x) is a much cleaner method (it allows the user to get an maintain cryptographically strong "certificates" which can be presented to specific servers on demand -- this exchange of certificates involves cryptographic authentication in both directions -- so your browser knows it isn't authenticating to some bogus imposter of a server -- and the server knows that your certificate isn't forged.
SSL client certificates allow you to establish accounts at a web site and securely interact with that site. Cookies can't do that. In addition many people have a vague notion that "cookies" where "snuck in" under them -- so they have a well-deserved "bad press."
-- Jim
New Hard DiscFrom: A Stephen Morse
Dear Mr Dennis:
I currently own an IBM 560 with a one gig hard disc which has both a win95 partition and a 200m Linux partition running version 2.0. We plan to upgrade today to a 2gig
Is this one of their "ThinkPad" laptops?
hard disk which accepts its data from the old disc through the PCMICA ports using a special piece of hardware. I believe the drive is called Extreme Drive. We also have available versions 4.1 and 4.2 of Linux on floppies (by the way 2.0 = 4.0 above). So far we've not been able to get any advice on how to proceed.
"...using a special piece of hardware."
I love that term "special." Sometimes you have to say it with the right inflection SPEC-I-AL! to really appreciate it.
Any suggestions. We are not super strong with Linux etc.
I think the question is:
How do I backup my current drive and restore it to the new drive?
(with the implication that you'd like to use this "special" device and just "copy" everything across).
There are several ways of backing up and restoring a Linux system. If you have an Ethernet connection to a system with lots of disk space -- or to a system with a tape drive you can do interesting things of the form:
dump -0f - | rsh $othersystem "dd of=$path_or_device ..."
If you can borrow or purchase a PCMCIA SCSI controller that Linux supports on this system you can hook up an external hard drive or tape unit and use that.
Those are the most straightforward methods for getting *everything* across.
Another approach is to identify just your data (maybe you keep it all under your /home/ and /usr/local/ directory trees -- or maybe you *should*). Now you get your new disk, install it, get some upgrade of your favorite Linux distribution (I hear the new Debian 1.3 is pretty good), install and configure that and -- finally -- just restore the selected portions of your data that you want.
If you're concerned about the potential loss of data or down time from any of these methods you might also consider renting a system (desktop or laptop) for a week to use while you're straightening things out on your main system. This is advice to consider any time you're doing a major hardware upgrade to an "important" system.
Interesting question!
Do any of the computer rental services offer Linux systems?
(PCR, Bit-by-Bit -- who else is in that business?)
-- Jim
Random CrashesFrom: sloth
hi. whenever i try to install linux (so far i have tried redhat, Slackware and Debian) the install program crashes at random times. I have tried removing all unnecessary hardware, ie sound cards etc, but it doesn't seem to make a difference. I have a Intel p150mhz, triton VX main board, s3virge graphics card, 16mb ram and a 2.0gb quantum harddisk. Any help would be MUCH appreciated! cheers, sloth...
Have you had your memory thoroughly tested?
I would take out your memory (presumably they're SIMM's) and bring them into to a good repair shop for testing. I DON'T recommend software diagnostics for this (like AMIDIAGS, Norton's NDIAGS, "System Sleuth" etc).
Do you run any other 32-bit software on this system? (Win '95 and Windows 3.x don't count)
Can you install and run NT, Netware, or FreeBSD?
I've seen motherboards that just wouldn't handle any true 32-bit OS for sustained use (presumably buggy chipsets) -- that's why Novell and Microsoft have these "compatibility" lists of motherboards.
Have you tried taking out the fancy video card and putting in a simple VGA (no frills -- Paradise chipset)?
Most of the Linux install scripts and programs (different for each distribution) just use text mode. Therefore it's very unlikely that the video card *type* is a problem. However if your particular card has a defect it could be something that only affects your system under Linux or some other OS'. It's a long shot, and some EE (electronics engineer) might tell me it's impossible -- but I'd try it anyway.
(I keep a couple of spare old VGA cards and even an old Hercules -- monochrome graphics -- card around for just these sorts of testing).
What sort of hard disk controller are you using? (IDE? SCSI?)
Some IDE controllers have buggy chipsets (some of them are even supported by compile time options in the Linux kernel). However, IDE controllers are cheap -- so keeping an extra around for testing is a very small investment.
SCSI host adapters are somewhat touchier and more expensive. Some of them are nominally supported by Linux (and other OS') but aren't worth keeping in your system. For example the Adaptec 1542B was a piece of junk. At the same time I use Adaptec 1542C and 1542CF and the various 2940's without hesitation.
RAM is the most likely culprit. The motherboard chipset is another possibility. A defective video card or a buggy HD controller are next in line.
It's possible that you're system has some sort of bizarre "top memory" which requires an address range exclusion or that you need to "reserve" some I/O ports so Linux won't use them or probe into them for hardware. You could spend a career trying different "stripped down" kernels on boot floppies and learning all the idiosyncrasies of your hardware. However -- it's probably more profitable in the long run to replace any hardware that's causing trouble.
The advantage of PC hardware is that it's cheap and widely available. It's curse is that it's often *cheap* and the specs are *widely* interpreted. Now that Linux is becoming available on some other hardware platforms -- and especially now that we're seeing "clones" of SPARC, Alpha, and PowerPC systems for rates that some of us can afford -- we might see some advantages from stepping away from the hardware half of the WIntel cartel.
-- Jim
gcc and Slackware QuestionFrom: Steven Smith
GNU's gcc is part of the slackware package that I have loaded on my system. I can and have compiled and linked C code.
I can compile the standard C++ code below (if I haven't miss entered the code but for some reason the C++ libraries will not link correctly (ie. i get and error):
#includ <iostream.h>
I think you mean
#include ...
main()
{
cout << "hello world\n";
}
Poor form. Unix programs should be
int main ( int argc, char * argv[] )
... or at least:
void main () ...
----------------
gcc -c program_name.C <- no errors
gcc program_name.C <- errors
Do you know what might be missing?
Your error messages.
Here's a way to capture sessions when you're trying to write messages to the , to me or to the ,or any of the appropriate news groups:
Get to a shell prompt. Issue the command: script ~/problem.log Run your test (demonstration of the problem). Back at the shell prompt, type Ctrl-D or issue the exit command. Edit the ~/problem.log file (take all the weird escape sequences out).
An easier way is to use emacs' "shell-mode" -- just start emacs and use the M-x shell-mode command. This creates a shell buffer (a sub task in emacs) which allows you to run tty style programs (no full screen "curses" stuff). The output from these shell commands will appear in this buffer and you can use normal emacs cursor, scrolling, cut, and paste operations to work with that output. For example I pasted your program into a new buffer, saved it, "fixed" a couple of minor things, switched to my shell mode buffer (I usually keep one handy) and ran the following sequence:
[jimd@antares lgaz]$ ls
hello.C
[jimd@antares lgaz]$ cat hello.C
#include <iostream.h>
int main( int argc, char * argv[] ) {
cout << "hello world\n";
return(0);
}
[jimd@antares lgaz]$ make hello
g++ hello.C -o hello
[jimd@antares lgaz]$ ./hello
hello world
[jimd@antares lgaz]$
... which I then simply pasted into this buffer.
Note that I use the make command here. A nice feature of 'make' (at least the GNU make) is that it can make some guess about what you mean even if you don't supply it with a Makefile. So my command make hello forces make to look for a .c, .C or .cpp file to compile and link. If it sees a .o file it will try to link it with cc -- but for a C++ file you need to link it with g++.
A nice side effect of using make this way is that I don't have to specify the -o (output name) and I don't end up with a file named a.out. It "makes" a program named hello.
So the source of your problem is probably that you are compiling your program with gcc in a way that confuses it -- and tries to link it as a C program rather than a C++ program. If you call gcc under the link 'g++' (just another name for it) you'll see the whole think work. The compiler pays attention to how you called it (the value of its argv[0]) and makes assumptions based on that.
Of course I can't verify that the errors I got were the same as the ones that you see -- since you didn't capture them into your message. In any event using make hello works -- using g++ hello.C works -- using gcc hello.C doesn't link properly and complains about unreferenced stuff and using gcc or g++ with the -c gives me an object file (hello.o) which is, for our purposes, useless.
A better venue to ask questions about compiling under Linux might be the Linux programmers list (as I mentioned earlier) or in any of several comp.lang.c and comp.lang.c++ newsgroups (since there is nothing Linux specific about this).
If you consider it a bug that gcc recognizes the capital C for C++ when generating .o files and doesn't automagically link with the appropriate libraries in the next pass -- take it up with the participants of the gnu.gcc.* or the gnu.g++.* newsgroups. (There's probably a very good reason for this behaviour -- though I confess that I don't see it).
-- Jim
LILOTo: Toby Riley
James,
I have been reading your page with great interest but I can't find anything about removing LILO and restoring My MBR. Unfortunately I have to de-install Linux for a while. I have tried running lilo -u and lilo -U and when the PC reboots I just get LI and the system hangs.
Personally I've never heard of a -u switch to lilo.
Normally you have to replace your lilo MBR with some other valid MBR. Most people who are disabling Linux on a system are restoring access to an existing set of DOS partitions -- so using the DOS MBR is in order.
To do that -- boot from a DOS floppy -- and run FDISK /MBR This should exit silently (no error and no report of success). The /MBR switch was added, undocumented, to version 5.0 of MS-DOS. It won't work with previous versions.
I can boot Linux off a floppy and the re-run LILO which adds my boot options and restore my system to a usable state. But I can't get rid of it and restore the Win95 boot up.
Under the hood Win '95 is MS-DOS 7.0 -- just run FDISK /MBR.
We eagerly await your return to the land of Linux.
-- Jim
Printing ProblemsFrom: RHS Linux User
hello answer guy!
Problem: Printing text / postscript documents.
Printing graphics (using xv) works fine, after having my printcap file set up for me, using apsfilter. I own a kyocera f-3010 and this printer can emulate an HP LaserJet Ser II. However, printing documents is a completely different story. Trying to print from, say, Netscape or LyX gets a printout of two or three "step ladder" lines, the output usually being something like "/invalid font in findfont . cannot find font Roman ... etc". Looks like it is not finding the appropriate ghostscript fonts. Is there any way to ensure that ghostscript can recognize my fonts (using xfontsel shows all my installed fonts)? Would you know how to rectify this problem?
Like X Windows, printing is a great mystery to me. I managed to get mine working -- including TeX with dvips (on my DeskJet 500C) -- but I still don't know quite how.
xv works and Netscape and LyX don't. Can you print a .dvi file using dvips? Can you print a Postscript file using lpr? How about mpage? Does that work?
The stairstep effect is common when raw Unix text is going to a printer that's expecting MS-DOS CRLF's (carriage return, linefeed pairs). That makes it sound as though the other applications are bypassing the filter in your /etc/printcap file (or that xv is somehow invoking the write filter before passing the directly to the printer).
Thanks a million for your help, this is something that has been bothering me for a while now.
Yeah. I let printing bother me for about a year before I finally forced it to print something other than raw (MS-DOS style) text.
You have gone through the Printing-HOWTO's haven't you?
-- Jim
Linux Disk SupportFrom: Andrew Ng
Dear Sir,
I have a question to ask: Does Linux support disks with density 2048bytes/sector?
Linux currently doesn't support normal disk with large block sizes. (CD-ROM's have large block sizes -- but this is a special case in the code).
It is likely that support for larger block sizes will eventually be added to the kernel -- but I don't think it will be in before 2.2 (not that I actually have an inside track on if or when anything is going to happen in kernel development land -- that's just my guess).
I have bought a Fujitsu MO drive which support up to 640MB MO disks with density 2048bytes/sector. The Slackware Linux system does not support access to disks with this density. Windows 95 and NT support this density and work very well. Is there any version of Linux which support 2048bytes/sector? If not, is there any project working on that?
Someone from Fujitsu's support team called me back on this (as I'd copied an earlier message to their webmaster).
The report was that the smaller 540Mb MO media are supported with no problem -- but that the high density media with the large block sizes weren't supported. If I recall correctly he said that this doesn't work for any of the other versions of Unix that Fujitsu knows of (with their drive).
-- Jim
Renaming ProblemsFrom: Sean McCleary
Anyhow, here's my problem:
I recently renamed my system in my /etc/HOSTNAME file. Ever since I made that change, my system's telnet daemon has stopped allowing incoming connects from ANYWHERE. I was told this has to do with my recent system-renaming, but the man who I was talking to about it never told me WHY or how to fix it.
I've checked my /etc/hosts.allow and /etc/hosts.deny.
These two files control the behavior of tcpd (the TCP Wrappers program by Wietse Venema).
You might also want to look at your /etc/hosts file. This file is used by most system resolver libraries in preference to DNS.
The resolver libraries are the code that allows client programs on your system to translate domain/host names into IP addresses. There are several schemes for doing this -- which can be set in different priorities for each host.
The oldest method for performing this resolution was a simple lookup in the local /etc/hosts file (there was also an /etc/networks file back then -- you don't see them very often now). This is still common for small networks (less than about 25 systems).
The most widely used method is DNS (also know as BIND -- Berkeley Internet Naming Daemon -- a.k.a. 'named'). Actually DNS is the protocol and BIND is the commonly available server software.
Another fairly widespread naming service is NIS and its causing NIS+. These were both created by Sun Microsystems and published as open specifications. This system was originally known as "Yellow Pages" -- and many of the commands for managing the service still have the prefix "yp" (i.e. 'ypcat'). However a company (British Telecom if I recall correctly) objected to the trademark infringement and Sun was forced to change the designation.
NIS and NIS+ are designed to distribute more than host and network name resolutions -- they are primarily used to manage accounts across whole domains (networks) of hosts. This is especially important among systems that are using NFS since that usually requires that you maintain synchronized UID across the enterprise. (The normal NFS behavior is to grant file access based on the effective UID of the user on the client system -- this can be overwritten in a cumbersome fashion -- but most sites simply synchronize the UID's -- usually via NIS or by using rdist and distributing whole /etc/passwd files).
Under Linux there is a file named /etc/host.conf (note: SINGULAR "host"). This sets the priorities of the resolver libraries -- which is typically something like:
order files bind nisplus nis
multi on
(look in the /etc/hosts and /etc/networks first -- then try DNS -- then NIS+ and finally NIS -- try multiple resolutions).
Why is this happening, Answer Man?
I don't know. Did you look at a tail /var/log/messages for clues? Are you sure that this is a problem with your host's name? Did you change to shadow passwords around the same time?
One way to get more clues about any failure you get from any service in the inetd.conf file is to replace the service's entry temporarily with a command like:
## telnet stream tcp nowait root /usr/sbin/tcpd in.telnetd telnet stream tcp nowait root /usr/sbin/tcpd /usr/sbin/strace \ -o /root/tmp/telnet.strace /usr/sbin/in.telnetdHere I've commented out the old telnetd line and put in one that keeps a system call trace file. Looking at this file can give some clues about what the program was trying to do up until it disconnected you.
I'll grant that you need to know something about programming to make any use of this file. However you probably don't need to know as much as you'd think. That start to make a little sense after you run a few dozen of them -- particularly if you have a "working" and a "broken" configuration to run your tests with.
-- Jim
X Locks MonitorFrom: Jon Jacob
I am trying to configure X. I have a Config file set to the SVGA generic using the XF86Config.eg file that comes with the Slackware96 distribution.
I have a Sony Multiscan15sf with a ATI mach64 PCI video care with 1 meg of VRAM. When I run startx, the monitor locks so that it turns to black but it still is getting a signal from the PC because the PowerSaving light stays green.
I tried fiddling with the Config file with no change. I ran the startx to redirect to an out file to see the error message, but I just get the same file I got when I ran x -probeonly.
I could not find a drive for an ATI Mach64 PCI card that matches mine. Do I need one? If so, where would I get it? Can I use some generic driver?
Also, Ramdoc was shown by the probe to be "unknown" so I left it commented out in the Config file. Could this be the problem?
I am very frustrate after hours and hours of attempts. Please help!
I keep trying to tell people: I barely use X. X Windows configuration is still a mysterious "black art" to me that requires that I have the system in front of me to do my hand waving in person.
I think you should search the X Windows HOWTO file for the strings "ATI" an "Mach." I'm pretty sure you need a special server for the Mach 64's and I wouldn't be at all surprised if it was one of those deviants that doesn't work with a generic SVGA driver.
The first time I ever got X running I resorted to IRC (Internet Relay Chat) -- where I joined the #Linux channel and hung out for awhile. After watching the usual banter for about 20 minutes and adding a few (hopefully intelligent) comments to the discussions at hand I timidly asked for some help. Some kind soul (I don't remember the nickname) asked for some info -- show me how to do a /dcc (direction communications connection?) to send the file to him -- edited my XConfig file and sent it back.
One of the beauties of Linux is that I was able to test a couple of revisions of this file while maintaining my connection. Naturally, I glanced over the file before using it. If you decide to take this approach I recommend that you avoid any binaries or source code that you don't understand that someone offers to xfer to you. You will be running this as 'root' on your system.
A config file with which you are moderately familiar is a bit safer -- though you could always end up with some weird trojan in that, too.
This is not to suggest that IRC has a higher percentage of crackers and "black hats" than anywhere else on the net -- just trying to emphasize that you have no way of identifying who you were working with -- and all it takes is one.
Another approach you might try is to call ATI and let them know what you want. As more of us use Linux and demand support for it the various hardware companies will have their choices -- meet market demands or lose marketshare.
If you decide to take this to the news groups be sure to go for comp.os.linux.x -- rather than one of the more general newsgroups. It is a little frustrating that so many X questions end up in the various other Linux news groups -- X Windows for Linux is no different than X Windows for any other x86 Unix. However I've never seen an XFree86 newsgroup so...
-- Jim
Using JDK 1.1 for Solarix x86 on LinuxFrom: Romeo Chua
Hi! I would like to know if I can use the JDK 1.1.2 for Solaris x86 on Linux. Does the iBCS2 module support Solaris x86 applications?
Last I heard a native JDK was already available for Linux (although that might be 1.1.1).
I have no idea whether SunSoft has maintained any compliance to iBCS in the Java stuff for Solaris.
-- Jim
Colormap QuestionFrom: Kevin T. Nemec
Dear Answer Guy,
I was wondering if it is possible to force a program to use its own colormap externally. That is, can you force a program without a built in option to use its own colormap to do so in some other way. I don't mind the "flashing" in some applications as long as I can see all the colors.
Kevin Nemec
I've heard that xnest can be used to run one X session inside of another. I don't know if this would help. I've used XFree86's support for multiple virtual consoles to run two X Windows sessions concurrently (using {Ctrl}+{Alt}+{Fx} to switch between them, of course). These can be run with different settings (such as 8bpp on one session and 16pbb on the other.
Other than that I have no idea. I keep trying to tell people I'm a *Linux* guy -- NOT an XFree86 guy. I run X Windows to do the occasional XPaint or XFig drawing, to run Netscape on sites that are just too ugly to tolerate in Lynx, and (recently) to play with xdvi and ghostview (to preview my TeX and PostScript pages).
So, anyone out there that would like an XFree86 Answers Column in Linux Gazette (or anywhere else preferably under LDP GPL) has my utmost support. (Although our esteemed editor, Marjorie Richardson will certainly make the decisions).
-- Jim
More on LILOFrom: Paul L Daniels
With respect to a question that was in "The Answers Guy" re LILO only presenting "LI" on the screen then _hanging_.
I found that problem too... the problem (at least for me) was that I was including a DOS partition in the LILO.conf file. After removing the partition manually, running liloconfig and reinstalling from current lilo image, everything worked.
If you were including a DOS partition in your lilo.conf file with some syntactic errors (making it look like a Linux partition perhaps) or if your previous edit of the file had not be followed by run /sbin/lilo (the "compiler" for the /etc/lilo.conf file) -- I would expect you to have problems.
However it is quite common to include one or several DOS partitions in a lilo.conf file. That is the major purpose of the LILO package -- to provide multiple boot capabilities.
If this is all babble and drivel, then ignore it, I wasn't sure who to post to.
I suspect that there was something else involved in the "stanza" (clause, group of lines) that you removed from your conf file. Since you've solved the problem it sounds like little would be gained from attempts to recreate it -- or to guess at what that had been.
-- Jim
95 GUIFrom: Sean
Sorry if I am one of hundreds w/ this kinda question./....but try to answer if you have time..
So I had linux loaded up and working fine was even able to make my dos/95 partition work ok too. So then I actually loaded the 95 gui {it had just been a sys c: to get a bootable dos/95 since I didn't have the 95 files for the gui at the time}
So now all I can get is 95...I tried the primitive fdisk thing thats part of the do you want to install linux again deal w/ the two disks also tried making different partitions active w/ fdisk as well...but no workie workie. I can boot w/ the two disks that are part of the linux install use the rescue option and then mount the hd linux partition to a directory of my choice and if I try to run lilo from their {since its not in /sbin/lilo on the floppies} it moans about lilo.conf not around and /boot/boot.b not present and such sooo I try to recreate that structure on the root {ramdisk:?} or floppy or whatever I am running everything from...run out of diskspace trying to copy hda files from now mounted hd to /dev of ram/floppy. So I'm stuck...Any ideas? I have read all relevant faq's/scanned every apparently related how-to's etc... to no avail...maybe its like you said on your page; maybe I'm not really running a "boot" floppy... help if ya can, My lilo.conf was reliably letting me into command line dos/95 and linux/xwindows etc.. system is an IBM thinkpad 760el if that's relevant.
The short story is that you don't know how to run /sbin/lilo.conf from a boot floppy (rescue situation).
There are two methods. One is to use the chroot command:
Basically after you boot you mount your root file system (and your usr if you have that separate) -- something like so:
mount /dev/sda5 /mnt/
mount /dev/sdb1 /mnt/usr
(Here I'm using the example of an extended partition on the first SCSI drive for my normal root partition and the first partition on my second SCSI drive as my usual usr partition -- change those as necessary).
You can (naturally) create a different directory other than /mnt/ or under /mnt and mount your filesystem under that.
Now you cd to that:
cd /mnt/And run the chroot command -- which takes two parameters: where to make the new root of your session's filesystem and what program to run in that "jail"
chroot /mnt/ /mnt/bin/bash
Here we're running the copy of bash that's under our chroot environment. Thus this session, and all processes started by it now see /mnt as /.
This was the original use of the chroot call -- to allow one to work with a subset of your filesystem *as though* it were the whole thing (handy for developers and doing certain types of testing and debugging -- without risking changes to the whole system).
Now should be able to vi /etc/lilo.conf and run /sbin/lilo to "compile" that into a proper boot block and set of mappings. (note the "/etc/" and "/sbin/" will be really /mnt/etc and /mnt/sbin -- to the system and to any other processes -- but they will *look like* /etc/ and /sbin/ to you).
The other approach is to create a proper (though temporary) lilo.conf (any path to it is fine) and edit in the paths that apply to your boot context. Then you run /sbin/lilo with the -C file to point it at a non-default lilo.conf (which can be named anything you like at that point.
The trick here is to edit the paths in properly. Here's the lilo.conf for my system (antares.starshine.org):
boot=/dev/hda
map=/boot/map
install=/boot/boot.b
prompt
timeout=50
other=/dev/hda1
label=dos
table=/dev/hda
image=/vmlinuz
label=linux
root=/dev/sda5
read-only
Here's how I have to edit it to run lilo -C when I'm booted from floppy and have mounted my root and usr as I described above (on /mnt and /mnt/usr respectively):
boot=/dev/hda
map=/mnt/boot/map # current (emerg) path to map
install=/mnt/boot/boot.b # current (emerg) path to /boot
prompt
timeout=50
other=/dev/hda1
label=dos
table=/dev/hda
image=/mnt/vmlinuz # path to my kernel
label=linux
root=/dev/sda5
read-only
Note that I've added comments to the end of each line that I changed. (I think I got them all write -- I don't feel like rebooting to test this for you). The specifics aren't as important as the idea:
The lilo program (/sbin/lilo) "compiles" a boot block from information in a configuration file -- which defaults to /etc/lilo.conf.
References to directories and file in the .conf file must be relative to the situation *when the /sbin/lilo is run*. References to devices and partitions typically don't change in this situation.
I hope that helps. It is admittedly one of the most confusing aspect of Linux to Unix newbies and professionals alike. In some ways I prefer FreeBSD's boot loader (the interactive and visual debug modes are neat -- you can disable various drivers and view/tweak various kernel settings during the boot). In other ways I prefer LOADLIN (which can load Linux or FreeBSD kernels from a DOS command prompt or from a DOS CONFIG.SYS file). In yet other ways I like the OpenBoot (forth interpreter and system debugger) used by SPARC's.
I would like to see PC's move to the OpenBoot standard -- it's SUPPOSED to be part of the PCI spec. Basically this works by replace the processor specific machine code instructions in device ROM's (for video cards and other adapters) with FCode (byte compiled forth). The system (mother) board then only has to implement a forth interpreter (between 8 and 32K of footprint -- much smaller than existing BIOS chips).
The advantage is that it allows your adapters to be used on systems regardless of the processor. Forth is a very efficient language -- as close to machine language as an interpreter can get -- and closer than many assemblers (some of which generate stray code).
Too bad there are no PC manufacturers who understand this YET!
Letter of ThanksFrom: Sean
Thank you from the bottom of my heart for your informative and very useful email. It took about 50 seconds using the chroot command {see I learned something new today :-) } I am back up...worked like a charm... I'll try not to bother you in the future but if I ever need to blow the horn at time of utmost need... It's pretty cool when stuff works, what is frustrating as heck is when you can't find the answers, I really did try reading the faq's/how to's and so on... You are right about the email coherency, need to work on that, guess I figured to a hack like yourself it would make sense {all the stuff that I had tried} and I wasn't sure you would actually write back.}
I'm doing this from minicom so everything workie workie :-)
When you have time; why did another friend {not in your league apparently} suggest: linux root=/dev/hda2 ro from the boot command? Supposedly it would boot from partition hda2 {linux native} at that point no such luck still went from floppy.
thanks again,
Sean
ST01/02 SCSI CardFrom: John Messina
My dad just gave me his old 386 machine. It's not much, but I wanted to start experimenting with it and to try to use it as a firewall. I upgraded it to 8MB of RAM and dropped in an ISA Ethernet card - just the bare minimum. I'm attempting to install RedHat 4.1 onto this machine. My main machine is already up and running with COL Standard and since the 386 has no CD-ROM, I attempted to do an NFS install. he NFS part of the install works perfectly (nameserver, exports, etc. on my main machine is configured correctly and autoprobe can find the 386's ethernet card). The problem occurs when the install starts to look for the 386's SCSI card. The 386 has a Seagate ST01/02 SCSI card with one hard drive attached. The ST01/02 is supported by the install, but autoprobe cannot find the card and I've tried all of the combinations for the parameters that are listed - checked the RedHat, CND, and COL manuals. No IRQ/Base address combination that I've tried works. I've looked at the board itself, but can't tell how it's set up. I guess my question comes down to the following:
Is there a way during the install to find out what the IRQ/Base address for this board is? Or, since the machine will successfully boot to DOS/Win3.1, is there a way to determine these settings from the DOS/Windows environment?
There are a variety of "diagnostics" utilities for DOS -- MSD (Microsoft) comes with some recent versions of DOS and Windows, NDIAGS comes with recent versions of the Norton Utilities, American Megratrends used to sell the AMIDIAGS, and there used to be some others called Checkit! and System Sleuth. There are also a large number of DOS shareware and freeware programs which perform different subsets of the job.
Another program that might list the information you're looking for is Quarterdeck's "Manifest" which used to be included with QEMM since about version 7 or 6 and with DESQview/386 (one of my all-time favorite DOS programs -- with features I still miss in Linux!).
The system I'm typing this on is an old home built 386. It is the main server for the house (the clients are Pentia and 486's -- mostly laptops). So you don't have to "apologize" about the age of your equipment. One of the real virtues of Linux is that it breathes new life into old 386's that have been abandoned by the major software vendors.
One approach to consider it to find a good SCSI card. I realize that you'll spend more on that than you did on the computer -- but it may be worth it nonetheless. Over the years I've upgraded this system (antares) from 4Mb of RAM to 32Mb and added: Adaptec 1452C controller, one internal 2Gb SCSI, and a 538Mb internal, a 300Mb magneto optical drive, a 4mm DAT autochanger, an 8x CDROM, a Ricoh CD burner/recorder, and an external 2Gb drive (that fills out the SCSI chain -- with additional drives including a Zip on the shelf) upgraded the old 200Mb IDE hard drive to a pair of 400 Mb IDE's, upgraded the I/O and IDE controller to one with four serial ports (one modem, one mouse, two terminals -- one in the living room the other in the office), and a 2Mb STB Nitro video card.
My point is that you can take some of the money you save and invest in additional hardware. You just want to ensure that the peripherals and expansions will be useful in your future systems. (At this point memory is changing enough that you don't want to invest much in RAM for your 386 -- you probably won't be able to use it in any future systems) -- bumping it up to 16Mb is probably a good idea -- more only if it's offered to you for REAL cheap.
Other than than I'd do an Alta-Vista search (at Yahoo!) for Seagate ST01/02 (ST01, ST02, ST0). My one experience with the ST01 is that it was a very low quality SCSI card and not suitable for serious use. I'd also search the "forsale" newsgroups and ads for a used BusLogic (you might find one for $10 to $25 bucks -- don't pay more than $50 for a used one -- low end new cards can be had for $60).
-- Jim
Booting LinuxFrom: Vaughn (Manta Ray) Jardine
I Use a multiconfig to boot either to Dos, Win95, or Linux (Redhat 4.1). I use loadlin from the autoexec.bat to load the linux kernel, however I recently accidently deleted the dir with loadlin and the vmlinuz.
Ooops! I hate it when that happens!
I made a boot disk on installation so I use that to get to Linux. I copied the vmlinuz from the /boot dir and put it on my Dos partition. Now I don't have the original loadlin so I took one from a redhat 4.2 site on the net. It still won't boot. It starts and halfway through bootup it stops.
Do I have to get the loadlin that came with redhat 4.1? What am I doing wrong. It boots fine off the boot disk.
Vaughn
I'd want to find out why the LOADLIN is failing. The old version of LOADLIN that I'm used to did require that you create a map of the "real BIOS vectors" -- which is done by allowing REALBIOS.EXE to create a boot disk, booting off of that, and then re-running REALBIOS.EXE.
This file would be a "hidden + system" file in C:\REALBIOS.INT
The idea of this file is to allow LOADLIN to "unhook" all of the software that's redirected BIOS interrupts (trap vectors -- sort of like a table of pointers hardware event signal handlers) to their own code. To do this you must have a map of where each interrupt was pointed before any software hooked into it (thus the boot disk). This boot disk doesn't boot any OS -- it just runs a very short block of code to capture the table and save it to floppy -- and displays some instructions.
You may have to re-run REALBIOS.EXE (generate a new BIOS map) any time you change your hardware. This is particularly true when changing video cards or adding removing or changing a SCSI adapter.
Obviously the version of LOADLIN that's used by Red Hat's "turbo Linux" and by the CD based installed program of other Linux distributions doesn't require this -- though I don't know quite how they get around it.
So, try installing the rest of the LOADLIN package and running REALBIOS.EXE. Then make sure you are booting into "safe" DOS mode under Win '95. I'd also consider putting a block (like a lilo.conf stanza) in your CONFIG.SYS which invokes LOADLIN.EXE via your SHELL= directive. That block should have any DEVICE= or INSTALL= directives except those that are needed to see the device where your LOADLIN.EXE and kernel image file are located. This should ensure that you aren't loading conflicting drivers. There are details about this in the LOADLIN documentation.
-- Jim
Kernel Panics on root fsFrom: Ken
Hi... I'm having some trouble, and maybe you could help??
I recently went from kernel 2.0.27 to 2.0.3. Of course, =) I used Red Hat's RPM system (I have PowerTools 4.1) and upgraded. After the config, compile (zImage), and modules stuff, I changed LiLo's config, to have old be my backed up kernel of 2.0.27, and linux be the new one. Then, I did a zlilo, and everything ran smoothly.
I presume you mean that you installed the 2.0.30 sources and that you did a make zlilo (after your make config; make dep; and make clean)
But now, one the new kernel, after it finds my CD-ROM drive, it won't mount my root fs. It gives me a kernel panic, and says unable to mount root fs, then gives me the address 3:41. What's going on??
I've tried recompiling and remaking lilo many times. (oh yeah... I didn't forget dep or clean either) Nothing works. I'm using the extended 2 fs, and it's built right in the kernel...
Did you do a 'make modules' and 'make modules_install'?
If you do a 'diff' between /usr/src/linux/.config and /usr/src/linux-2.0.27/.config what you you see?
Are you sure you need features from the 2.0.30 release? You may want to stick with 2.0.29 until a 2.0.31 or 32 goes out. I know of at least one problem that's forced my to revert for one of my customers*.
It has always been the case with Linux and with other systems that you should avoid upgrading unless you know exactly what problem you're trying to solve and have some understanding of the risks your are taking. That's why it's so important to make backups prior to upgrades and new software installations. I will note that my experience with Linux and FreeBSD has been vastly less traumatic in these regards than the years of DOS and Windows experience I gained before I taught myself Unix.
* (using the -r "redirect" switch of the ipfwadm command to redirect activity on one socket to another works through 2.0.29 and dies in 2.0.30 -- and gets fixed again in a "pre31" that one of my associates provided to me).
Here's my lilo config file...
...[ellided]...
That looks fine.
I suspect there's some difference between your kernel configurations that's at fault here. Run diff on them (the files are named .config in the toplevel source directory). or pull up the 'make menuconfig' for each and place them "side-by-side" (using X or on different VC's).
Hint: You can edit /usr/src/linux/scripts/Menuconfig and set the single_menu_mode=TRUE (read the comments in the file) before you do your make menuconfig -- and you'll save a lot of keystrokes.
Maybe you need one of those IDE chipset boxes checked.
My hard drive that boots is hda, and my Linux drive is hdb. I took out read-only a while ago, to try to solve the problem. It made no difference. It'd be great if you could help me out a little. Thanks, Ken...
In issue 18, I described how to avoid certain security risks when removing files from your /tmp directory. I have received some letters as feedback, and I'll summarize the issues here. Some people said they didn't need the extra security. Well, they're free not to use my script.
Michael Veksler <[email protected]> told me he was worried about the use of the access time to determine the file's age. His main concern was that files could be ``accidently'' touched by
find ... | xargs grep ...constructions. Personally, I don't have this problem, as I tend to restrict the domain of my find sweeps.
As I said in my first article, it's a personal taste. I frequently unpack archives in my /tmp hierarchy. And I want to be certain the files will stay there until I don't need them anymore.
To me, 3 days after last looking at the file seems a reasonable delay for that.
But recently, I started using afio for transporting files that won't fit on one floppy. And afio Remembers the access time during archiving, and also sets this date while unpacking. This could limit the lifespan of my files if I don't look at them immediately. (As a sidenote, zip also sets the access time.)
Obviously, there is one other possibility I neglected: using ctime (inode change time). It is not possible to set this to an arbitrary value, and it doesn't change as easily as the access time.
Perl has a rather large memory footprint, and is not available on every site. Therefore, Francois Wautier < suggested:
cp -p /bin/rm-static /usr/bin/find-static /tmp
chroot /tmp /find-static ... -exec /rm-static {} \;
rm /tmp/rm-static /tmp/find-static
rm-static and find-static are statically compiled versions of rm and find, respectively. The -p flag ensures the resulting binary is owned by root, closing one security risk. (A user might have created her own /tmp/rm-static with the intend of changing the binary.)
This gives rise to a new set of race conditions, although they aren't as easy to exploit as the
find ... | xargs rmsecurity hole described in my first article.
In general, I would advise against executing arbitrary files with root permissions, especially if they are residing in a publicly writeable directory (like /tmp). (It is also related to the reason why `.' should never be in root's path.
This leads me to a real security risk:
(This one I found myself.)
I recently upgraded to perl 5.004. After the upgrade, I noticed my cleantmp script started emitting warnings about not finding the pwd program.
I looked into the perl module code, and it uses pwd to determine the current directory.
The script itself doesn't have problems with the missing binary, as I'm using absolute paths everywhere. But it opens a huge security hole: An executable called pwd in the right place in the /tmp tree can give a user a process executing with root permissions.
In this case, the chroot decreases security, instead of increasing it.
For this reason, I have decided to remove the chroot from the script entirely. That way, I can be sure only trusted binaries are executed.
In the first version of my script, I demonstrated how to exclude some files from being deleted. I obviously forgot one thing: a user could create files or directories with the same names, and they would never be deleted.
The solution is easy: test the owner of the file, and if it isn't root, just delete the file.
Here is a link to the new script. Comments are welcome.
It started out pretty simple. I was on a my client's webserver, simply paging through routine entries, when I came on the following entries (IP addresses have been changed to protect the guilty):
May 2 23:25:09 bankweb ps[12613]: connect from 128.128.128.128 May 2 23:25:09 bankweb netstat[12614]: connect from 128.128.128.128 May 2 23:25:10 bankweb wu.ftpd[12616]: connect from 128.128.128.128 May 2 23:25:10 bankweb in.telnetd[12617]: connect from 128.128.128.128 May 2 23:25:15 bankweb in.fingerd[12619]: connect from 128.128.128.128 May 2 23:25:16 bankweb in.pop3d[12620]: connect from 128.128.128.128 May 2 23:25:17 bankweb in.nntpd[12622]: connect from 128.128.128.128 May 2 23:25:17 bankweb nntpd[12622]: 128.128.128.128 connect May 2 23:25:17 bankweb nntpd[12622]: 128.128.128.128 refused connection May 2 23:26:55 bankweb wu.ftpd[12624]: connect from 128.128.128.128 May 2 23:28:03 bankweb ftpd[12624]: FTP session closed May 2 23:28:19 bankweb in.telnetd[12632]: connect from 128.128.128.128 May 2 23:28:44 bankweb login: 2 LOGIN FAILURES FROM 128.128.128.128, guest May 2 23:29:12 bankweb ps[12634]: connect from 128.128.128.128 May 2 23:31:20 bankweb ps[12637]: connect from 128.128.128.128 May 2 23:32:25 bankweb netstat[12638]: connect from 128.128.128.128 May 2 23:34:21 bankweb in.fingerd[12641]: connect from 128.128.128.128 May 2 23:35:54 bankweb in.rlogind[12644]: connect from 128.128.128.128 May 2 23:35:54 bankweb in.rshd[12645]: connect from 128.128.128.128 May 2 23:35:54 bankweb rshd[12645]: Connection from 128.128.128.128 on illegal port May 2 23:36:56 bankweb in.telnetd[12647]: connect from 128.128.128.128 May 2 23:37:11 bankweb login: 2 LOGIN FAILURES FROM 128.128.128.128, root
Uh-oh. For a couple of minutes, someone was definitely rattling my client's locks, looking for a way in. As a system administrator, what do you do now?? How do you find out if the intruder managed to actually get in? Did he *do* anything to your system? How do you make sure he doesn't get back in?
In this article, I'll make a few suggestions about a few basic steps that can be taken and some of the specialized tools that can help keep your system secure.
The first thing you want to check for is the possibility that the intruder is still logged on. A quick way to check this is 'w' or 'who' commands--look for someone logged from a remote machine. The thing to remember about these commands is that they work by reading a file ('utmp', typically found in /var/adm) that keeps track of who is logged in. If the intruder has broken into the root account, then he can change that file to make it look like he's not there.
Two good ways of finding such phantom users are to use the ps and netstat programs. Since these query kernel data structures rather than files, they are harder to spoof. Using ps, look for shells and programs that aren't associated with a legitimate user. Netstat is a lesser-used utility used to display the network status. If it is not in the normal system directories, look in /sbin or /usr/sbin. By default netstat displays active Internet connections. Again, look for connections to suspicious sites.
In the worst case, the intruder is lurking around in your system. If the intruder has managed to break into the root account, he will be able to remove all your files with a quick rm -rf /. Fortunately, such toe-to-toe combat with intruders is rare.
The best solution to an intruder on your system is to immediately disconnect the Ethernet cable. Without giving him any warning, this puts a stop to whatever he is doing and isolates your computer, preventing further damage. Furthermore, it will appear to him that the network has failed-- which is in fact what has happened.
Unfortunately, you (or no one you can contact) may not have physical access to the machine when this happens. The second best thing to do about an intruder involves a judgment call. You can A) let him alone and hope he doesn't destroy the system and assess the damage later, B) talk to him using 'talk' or C) kick him off and hope he can't get back in.
If you decide to kick him off, you of course need to be root. Simply rebooting the system isn't a good idea, since the system will come back up and the intruder will probably be able to re-enter and will know that someone is onto him. The usual way of kicking someone off is to run a kill -9 command on their telnetd or rshd processes. These processes act as glue connecting the network to the intruder's shell. An equally valid method is to kill their shells. Either way, the intruder will see the message "Connection closed by foreign host" and will know that something is up.
The right way to do this is to remember that kill -9 will accept multiple process ids, and you want to blindside him. After you've used 'ps' to find *all* of his process ids, include the process id of the 'inetd' process. Inetd is sometimes referred to as the "Internet super-server"-- all it does is watch for incoming network connections and makes sure they are connected to the right handler. By killing inetd, you prevent new connections from being accepted, be they telnet, ftp, finger or whatever. Of course, if he's root, he can do this to you.
The real danger posed by an intruder is that once in, he can make it easy for himself to get back in, though you may close the hole he originally came through. The way this has to be done is by modifying the filesystem in some manner (with Linux, he could easily compile you a new kernel, but the kernel is ultimately stored in the filesystem).
The freeware program tripwire is used to detect modified system files. The idea is that tripwire records the size, date and a quantity called a "one way hash function". The idea is to take the data of the file and compute a fairly large random number. If the file changes, a different hash value results. The "one way" part means that it is "difficult" to make a small change to file and still come up with the same hash value. Of course, if the database of hash values is stored on the hard disk and the cracker finds it, he can just update the database... which is why you want to keep the database on a floppy.
The find program is extremely useful for finding suspicious looking files that the intruder has left laying around. Use find to look for recently-modified files in the /lib, /usr and /etc hierarchies, keeping in mind that it is possible to change the timestamps.
An easy situation occurs when you have installed a system via CDROM. Since the CDROM cannot be modified, you can compare what is on the CD with what is on the hard disk. Something like:
find /bin -exec cmp {} /CDROM/dist/{}Another thing to check for is:
find / -perm +6000 -print
Note that the -perm option is specific to GNU find-- other systems may have different syntax. What you're looking for are suspicious files. A great way to learn Unix is to simply go through the system files and figure out what each one does.
Perhaps the best way to sleep easier at night is to simply reinstall the operating system and all of the utilities after a breakin. This operation is much easier under Linux than most other Unixes and goes a long way toward giving you peace of mind about any time-bombs left behind. Besides, you were meaning to upgrade anyway, weren't you?
By default, most Linux systems come with tcp wrappers automatically installed. This program intercepts the initial service requests from remote machines and logs them in the system logs. The wrappers can be configured to reject or allow access from listed sites.
In the attempted bankweb breakin, the wrappers let me know that there had been an attempt in the first place. From the listings, you can see that by default several services were enable during the installation that really shouldn't be running. The ps service let the intruder see processes running on our machine-- and gain account names. netstat let him see the machine's active network connections. The first step was to disable those two "services" by commenting out their lines in /etc/inetd.conf and resetting inetd.
Step number two was to track the cracker back to his network provider. Fingering and telnetting to the IP number produced a refused connection, implying that the machine in question was probably not a Unix machine. Telnetting to port 137, the windows name service port was accepted, implying that the machine was a windows box. It was quite possible that the machine I was looking at was not the intruder's machine-- if the intruder was dialed in via ppp, then the IP number could have simply been reassigned to the machine that I was probing.
A lookup using whois with the first three parts of the IP number produced the provider's name but not an email address to send a complaint to. Using the traceroute program gave some intermediate addresses that I used to find the intruder's provider. The next-to-last address in the route to the intruder refused connections, but trying to telnet into the second-to-last produced a shocking result-- the address turned out to be a completely unprotected router. Not only were current network statistics displayed and updated, but "Configure" was a prominent menu item...
I logged in to a workstation cluster at school late one Saturday night to check the progress of one of my jobs. I was quite surprised to find 'root' logged in running a couple of shells and a chess demo from the local X-windows console. I chose to leave the intruder alone since I was unable to do much-- the recent installation of NIS had been botched and left me unable to change the cluster's root password.
I called the police after he shut down the system, since we've had a few computer thefts. I did have to do some fancy explaining to the dispatcher on why I thought a theft was taking place from several miles away. It turned out that the intruder was an idiot who didn't know the difference between shutting the system down and logging out.
He had acquired the password by watching one of the faculty miss the "enter" key while logging in as root-- the password was echoed right after "root". Coincidentally, I had acquired the cluster's root password in the same way, only I found it by seeing the log entry login failed for rootrs314m. The moral is change the password if someone sees it, or if it has accidentally gone into the system logs.
One day, on a machine I used as well as administered, I received a very strange letter that had been originally addressed to root-- I had forwarded root's mail to myself. The letter appeared to be (and in fact was) a command that was supposed to mail our password file to an address at an ivy-league university on the east coast. Old versions of the 'sendmail' program had a mode that allowed commands to be sent in letters to facilitate debugging. When the program was distributed, this "feature" was not disabled. Fortunately, the vendor for the workstation (not a Linux box) had closed that hole.
The next step was to contact the source of the attacks. I have found that the proper attitude is to be polite, and inform the administrators that you are having a problem with one of their users, then show them everything you have... and hope that the person you've contacted isn't the one who is launching the attacks. The address turned out to be on a completely insecure mail server, ending the hunt, but we at least made the right people aware of the problem.
That machine suffered several additional attacks over the next couple of months. The reason was that one of my users, who happened to be Russian, had a bunch of less-than-reputable "friends" back home who wanted impress him by breaking into his machine. At a group meeting, I mentioned these attacks, and half-suggested we all kick in twenty dollars, send the total to Moscow, and have a few legs broken. The other Russian, in our group, a very mild-mannered man, said "Break their legs?? Break their heads!". Watch out for those Russians...
I received an email notifying me that the machine in War Story #3 was being used as a base for attacking other machines. I forwarded root's mail to myself by putting my email in a file named .forward in root's home directory. If you administer a workstation, you want to do something like this, because the root account is typically rarely used and you want to know about this sort of thing the moment it happens.
As it turned out, the people complaining had waited too long for us to figure out who had been on the machine when the attacks took place. The logs on that machine were rotated every two weeks. Since the prime suspect had graduated, we chose to close his account along with all the other accounts that had never been deleted. Examining the suspect's files, we did find tools for breaking in to a variety of systems as well as a utmp editor for hiding his tracks. The root password was changed at the same time.
So, in conclusion, if you find out that *your* machine is under attack, stay calm, do it quick, do it first and keep your backups handy.
Check out Bill Cheswick's classic "Evening with Berferd" paper. ftp://cert.org/pub/papers/Bill_Cheswick_berferd.ps Andy Vaught [email protected]
 |
|
 |
muse:
|

In this months column I'll also be covering:
 |
I ran across this in the GIMP Developers mailing list. Unfortunately, I forgot to save the attribution. My apologies to the original poster of the message.
I've been reading some of the W3 specs recently, and I've come across some good stuff. I'm impressed - until recently it seemed like the W3 either wouldn't or couldn't get their act together, but now they seem to be putting out genuinely useful specifications. |
xfont3dThis program is a graphical interface to Font3D(http://www-personal.ksu.edu/ ~squid/font3d.html), and requires the XForms library (http://bragg.phys.uwm.edu/xforms). The interface was developed with Font3D v1.6. Font3D generates geometry (model) files for 3D text in a variety of output formats (POV, RIB, etc.) from True Type font files. I designed xfont3d to be used as a tool mainly for POV-Ray. The built-in POV-Ray pre viewer allows you to render a sample of the font generated by Font3D. However, xfont3d supports all the output options of Font3D - you just won't be able to preview it directly from xfont3d. You can view an image of the interface and get the source code from http://cspar.uah.edu/~mallozzir I wrote the thing in about three days, so by that time I was sick of it, and hence it has not really undergone much testing Please send any bug reports or comments to Dr. Robert S. Mallozzi |
GCLGCL (Graphics Command Language) is an interpreting language that is based on the data plotting library DISLIN. Version 2.2 of GCL is now released.About 400 plotting and parameter setting routines of DISLIN can be called from GCL for displaying data as curves, bar graphs, pie charts, 3D-colour plots, surfaces, contours and maps. Several output formats are supported such as X11, PostScript, CGM, HPGL, TIFF and Prescribe. Some quickplots are also added to GCL that can display data with one command. Similar to programming languages such as Fortran and C, high-level language elements can be used within GCL. These are variables, operators, array operations, loops, if and switch statements, user-defined subroutines and functions, and file I/O routines. GCL is free available for the operating systems MS-DOS, Windows 95, VMS, Linux, AIX, Digital UNIX, HP-UX and SunOS. FTP sites: ftp://ftp.gwdg.de/pub/grafik/dislin Home Page: http://www.mpae.gwdg.de/dislin/dislin.htm |
|||||||
ImageMagick 3.8.8The newest version of the binary distribution of ImageMagick, version 3.8.8, has been uploaded to Sunsite.. You can also get it from its primary site at ftp.wizards.dupont.com /pub/ImageMagick/linux.ImageMagick (TM), version 3.8.8, is a package for display and interactive manipulation of images for the X Window System. ImageMagick performs, also as command line programs, among others these functions:
|
|
|||||||
Axis uses OpenGL on SGI and Win 95/NT, and Mesa on the remaining platforms. The 3dfx accelerated version utilizes the Mesa Voodoo libraries. The Linux version currently has the best coloring/shading; the different OpenGL implementations have quirks that we haven't sorted out yet.
The rendering engine uses a simple stack machine interpreter, and processes a language that has similarities to Lisp, Forth, and Adobe's PostScript. The interpreter is multi-threaded, so objects in the 3D environment can have private namespaces. We are working on a programming manual for the language.
It is also network-ready; you can talk directly to the rendering engine with a TCP/IP connection. The distribution includes source code for an example TclTk program which utilizes the network connection (this is the tool we used to position models within the 3D environment). We will be releasing more complex modelers shortly.
The rendering engine and language interpreter will be the base for our multi-user shared environment application, which we plan to release near the end of July. Environments, and information about positions of other users, will be downloaded via TCP/IP; if you choose to customize your avatar, code for that can be uploaded.
Enjoy, and let me know if you have questions.
Patrick H. Madden
or
when we get our mail server sorted out.....
|
EPSON Scanner DriverEPSCAN is a scanner driver for EPSON ES-1200C/GT-9000 scanners. It includes a driver and a nice X frontend. It allows previewing, and selecting a region of an image to be scanned, as well as changing scanner settings. It only supports scanners attached to a SCSI port, not to the parallel port. The driver should support any of the ES-{300-800}C / GT-{1000-6500}.EPSCAN is available from: The rpm version will probably be moved, if it hasn't already, to The sunsite version will probably be moved to Adam P. Jenkins Requirements:
|
||||||||
Iv2Pov/IV2RayCow House Productions is pleased to announce the release of Iv2POV. Iv2POV is a translator / converter for Inventor 2.0 / VRML 1.0 files to POVRAY, the popular raytracing program. Both source code and an Irix 5.3 executable are available (free!) atWhile you are at www.cowhouse.com - feel free to take a look around, download some samples, and otherwise exerciseyour browser. |
|||||||||
...there is a very nifty morphing tool, called xmrm, available at http://www.cg.tuwien.ac.at/research/ca/mrm/index.html. I played with this a little and it has one of the most professional looking interfaces I've seen in awhile. Its relatively easy to use, at least if you follow the one example morph it provides.
...there is a Web site devoted to explaining how to make MPEG movies? Take a look at http://www.arc.umn.edu/ GVL/Software/mpeg.html to find out more.
A: Well, I don't know of any tools that can take a set of TGA files and directly turn them into an animation on Linux systems. I'm not that familiar with animations yet, but here is what I do know.
First, you have two types of animations you can create (with freely available tools) from a set of raster images: MPEG or an animated GIF. The latter requires the images to be in GIF format (GIF89a, actually). There are two tools for taking the GIF files and turning them into an animation: WhilrGIF and MultiGIF. Both are command line tools and both are fairly easy to use. I like MultiGIF a little more simply because it can create smaller animation using sprites (small images that can overlay the previous image). Understanding how to do this is a little tricky, but not that tough. WhirlGIF simply concatenates the set of GIFs together into an animated sequence. Playing an animated GIF can only be done by Web browsers, although I only know for certain that both Netscape and MSIE support this format. To my knowledge (someone correct me if I'm wrong) there are no "animated GIF players" for Linux.
MPEG is an animation format that I've just started to experiment with. There is only one command line tool that I'm aware of for creating the animations - mpeg_encode - but there are quite a few tools for viewing them (xanim, MpegTV, mpeg_play, etc). Creating the animation is done by setting up a text file with the configuration information needed by mpeg_encode. It then reads the configuration file, determines what sort of processing is to be done and takes the input files and creates the MPEG output file. The configuration can be fairly sophisticated, but I found the default template worked fairly well with only a few minor modifications. One of those modifications was to tell mpeg_encode what other tool to use to convert the input files, which were in TIFF format (rendered from BMRT), into a format that mpeg_encode could handle. Fortunately, mpeg_encode handles two fairly common formats: JPEG and PPM/PNM (it actually supports a couple of others, but these two will be readily recognizable to most users). I used the NetPBM tool tifftopnm. The TIFF files are converted on the fly by mpeg_encode as long as you tell it what converter to use.
There is another format called FLI which has an encoder. My understanding is that this format is slowly dying as MPEG gains popularity.
So now that you know what formats you need to put the animation in you might wonder how to get the TGA files into the formats you need. Thats a common question when dealing with both 2D and 3D images, in both animated and static formats. The answer: get either the NetPBM tools. ImageMagick, or ImageAlchemy (the latter being a more sophisticated commercial product). Any of these are valuable tools for your arsenal of image processing since they all perform the often needed task of converting from one format to another. NetPBM is what I currently use, although I don't believe it has a tool for converting JPEG images to other formats (there is an add-on package for NetPBM that handles this, but I don't think the NetPBM package itself has JPEG conversion tools - I could be wrong, its been awhile since I downloaded the package).
So, to summarize how to get your TGA files into an animation:
 |
Reagen Ward wrote:
I come from the world of PHIGS for visualization, and thus can't stand VRML as a supposed data format. I'd love to hear your opinions on why it's not ready for personal use.
Originally I had objected to it due to bandwidth issues. I've learned since then that this may not be as big a limitation as I once thought since VRML provides a language which can be passed between client and server and doesn't (to my knowledge - which admittedly is still somewhat limited) require the actual images to be passed. PHIGS could probably be done this way too, but PHIGS needs a "PHIGS for Dummies" layer slapped on top to make it a little more user friendly.
However, the real limitation right now is processing power. Even if you pass only descriptions of the objects to render, the end system still has to be fast enough to render them from the point of view of the user. This is very CPU intensive. The average user doesn't have this kind of processing power (have you seen the new WebTV boxes? They are even slower and
dumber than the average 2 year old PC). This processing could be moved off CPU into some adapter card (maybe a VRML-ready display card), but such technology isn't available yet so its cost would still be (for some time) out of the reach of the average home.
Now its not unlikely to see VRML in some environs: kiosks in stores or malls (real ones, not Internet Malls) come to mind or any kind of public facility that provides information to users to be browsed at their own pace. These places will have limited point-of-view (like point-of-sale) locations on a local network so bandwidth is not a problem, nor is server capacity (its known pretty much ahead of time how much activity they're likely to have). The point-of-view boxes can be as powerful as the mall can afford. VRML provides a reasonable return-on-investment for these situations.
But the big money, and money (income, that is) is what drives acceptance, only comes when you can move the technology into the home. Thats what WebTV's are all about - computers for the common man at toaster prices. VRML requires too much processing for the average home, so its not likely to be a big technology for at least 2-5 years. It depends on if Intel/Sun/HP/etc can find a way to make money producing VRML-toasters.
Hows that?
|
|
|||||||||||||||||||||||||
Image AlchemyOne of the most common tasks graphic artists will face is converting stock images from CDs and other resources from their original format to one that can be used by their particular software or medium (such as for use on the Web). There are actually a plethora of tools for doing this conversion. xv will convert between a limited set of formats, but does handle most of the most common formats. The NetPBM tools handle a huge number of formats using a very large set of command-line programs. And ImageMagick has both command line and X-based interfaces for converting images. Each of these has advantages and users will want to play with each to find one that suits their needs.Another solution for image conversion and manipulation comes from Handmade Software in their Image Alchemy package. This is a commercial package that features support for over 60 different image file formats using a command line interface. A graphical interface is available for Sun systems using OpenLook and there may now be a Motif version as well, however these do not appear to be available for Linux yet. Getting the software requires that you simply download the Linux binary package from the download page of Handmade's Web site. There is a demo package available for free, but the retail version requires a username and password that can be obtained from their sales department. The package I have, which I got from Hap Nesbitt at Handmade Software, contains two binaries: alchemy and alchfont. The former is the graphics conversion package. The latter is a font manager, although I'm not really clear on how to use it. The documentation, 330+ pages in a PDF file, didn't contain any references to it. Since I wasn't expecting this tool I didn't spend any time looking for info on it at the Handmade Software Web site. The manual is available for download from their Web site. Its quite large (something you'd expect from commercial software and something that is seriously lacking in many freeware packages) but it covers all the versions of the software, including 2 chapters (out of 8) and 1 appendix (out of 11) on the DOS/Windows Graphical interface. Along with the manual you can get runtime help by using the -help command line option. The runtime help is broken into several categories, each with its own command line option. The basic usage takes the following form: Unlike NetPBM the images don't have to be converted to an interim format before the final image is produced. NetPBM used the interim format to do its image manipulation, such as scaling or quantizing the colors in the image. Image Alchemy can do this in one step using various options. Speaking of options, the Image Alchemy manual breaks the available options into 4 categories:
|
|
||||||||||||||||||||||||
 |
|
Linux Graphics mini-Howto Unix Graphics Utilities Linux Multimedia Page Some of the Mailing Lists and Newsgroups I keep an eye on and where I get alot of the information in this column: The Gimp User and Gimp Developer Mailing Lists. |
 |
No Muse next month (September). I'll be at SIGGRAPH and otherwise busy throughout August and just won't have time for it. But I'll be back in October, probably with lots of goodies from SIGGRAPH (or at least I hope I am!).
More...
|
 |
| © 1997 by |
The GNU Revision Control System is generally considered a tool for software development, but it is also useful for tracking revisions of text documents. This article explains how to include and format RCS keywords in LaTeX documents, and how to track document revisions using these keywords.
Most discussions of the GNU Revision Control System occur in the context of tracking source code revisions. But RCS can track revisions of any type of file, text or binary, provided that the diff utilities which generate RCS change files can handle binary data.
RCS seems ready-made for working with LaTeX input files. The pre-defined keyword identifiers built in to RCS are easy to format and print. They provide ready information that can include the document's author, its revision, filename, and, revision log entry. RCS also provides facilities for user-defined identifiers.
RCS is commonly included with the development software of Linux distributions. The latest source code version of RCS is available from ftp://prep.ai.mit.edu/pub/gnu and its mirror sites.
The ident(1) manual page has a list of the standard RCS keywords that are generated when documents are checked out by RCS. They include:
These keywords are included verbatim in documents. They are expanded when the document is checked out with co(1).
One consideration that needs to be taken into account is that the keywords' dollar signs are interpreted by LaTeX (and TeX) as starting and ending math-mode typesetting. LaTeX and TeX will not generate an error when it encounters the dollar signs. However, because LaTeX and TeX typeset equations differently than normal text, the results can be unpredictable.
For example, including the $Id: issue20.html,v 1.1.1.1 1997/09/14 15:01:51 schwarz Exp $ string at the top of the odd pages the commands
\pagestyle{myheadings}
\markright{$Id: issue20.html,v 1.1.1.1 1997/09/14 15:01:51 schwarz Exp $}
results in the expanded RCS $Id: issue20.html,v 1.1.1.1 1997/09/14 15:01:51 schwarz Exp $ string to be printed at the top of the pages, but some of the keywords run together because of the way TeX formats the string. An alternative is to use the keywords of the individual identifiers, and separating them with the appropriate command. Here, the TeX command \hfil inserts the necessary space when the keyword strings are typeset in the running head.
\pagestyle{myheadings}
\markright{$Date: 1997/09/14 15:01:51 $\hfil$RCSfile: issue20.html,v $\hfil$Revision: 1.1.1.1 $}
The string given to the \markright command will be typeset with the date in the upper left of the page, the filename centered, and the revision number at the top right.
The \markright command is all that's needed for printing on one side of a sheet. For printing on both sides of the page, use the \markboth command.
\pagestyle{myheadings}
\markboth{$Date: 1997/09/14 15:01:51 $\hfil$RCSfile: issue20.html,v $\hfil$Revision: 1.1.1.1 $}{\thepage}
The first argument to \markboth prints the RCS information at the tops of the left-hand pages and the page number at the top of the right-hand pages. The identifier \thepage is a standard LaTeX variable which prints the page number.
The RCS log message can be placed anywhere in a document that the $Log: issue20.html,v $ Revision 1.1.1.1 1997/09/14 15:01:51 schwarz Imported files keyword can be inserted. For example, to place a (short!) log message in the margin at the beginning of a document, put the command \marginpar{$Log: issue20.html,v $ \marginpar{Revision 1.1.1.1 1997/09/14 15:01:51 schwarz \marginpar{Imported files \marginpar{} immediately after the \begin{document} command, or after the \maketile command if the document has a title page and you'd rather have the RCS log text annotating the body text of the document.
The RCS information can be included in the documents footer by using the fancyhdr package, which is available from any TeX archive site.
If you want to include the $Date: 1997/09/14 15:01:51 $ and $Revision: 1.1.1.1 $ keywords at the bottom of a page, you could include
\usepackage{fancyhdr}
\fancypagestyle{rcsfooters}{%
\fancyhf{}
\fancyhead[C]{thepage}
\fancyfoot[L]{$Date: 1997/09/14 15:01:51 $}
\fancyfoot[R]{$Revision: 1.1.1.1 $}
in the document preamble; that is, before the \begin{document} command. At the point you want the RCS data to be typeset, insert the commands
\thispagestyle{rcsfooters}
\pagestyle{rcsfooters}
ident(1) also searches files for RCS keywords. Typing the command ident term-paper.tex for example, will print a list of the keywords and their values to standard output. It's a simple matter of typing ident *tex | grep "fred" - to search for the documents which were last checked out by user fred.
For further information, consult the manual pages of the various programs in the RCS package, and the rcsintro(1) manual page for an introduction to the RCS system.
Jim Dennis, "The Answer Guy" columnist for Linux Gazette interviewed Sameer Parekh for us. Sameer Parekh is the founder of C2Net Software Inc., http://www.c2.net, the company that imports the Stronghold web server. Stronghold has added fully licensed commercial SSL support and other features to the popular Apache web server.
Jim: So how many platforms have you ported Stronghold to?
Sameer: We support almost 20 different forms of Unix.
Jim: Obviously Linux is one of them. Do you require a 2.x kernel?
Sameer: No. We support both the ELF and the a.out libraries. It works with 1.2 and 2.0, although we generally recommend using the latest stable kernel.
Jim: Which version, or implementation, do you think is your biggest volume seller? They're all priced the same right?
Sameer: Yeah, they're all priced the same. I think actually Linux is our number one seller. Then, second to that, we have Solaris and Irix. I haven't ... I really should do the numbers. I haven't done those because we don't sell on a "per platform basis." We just sell a Stronghold license, and they can use it on whatever platform they like.
Jim: Now you've got separate numbers for when people have gotten a evaluation copy and when they've licensed it. About how many evaluation copies are being downloaded every month?
Sameer: I couldn't tell you precise numbers ...
Jim: Just a ball park... are we talking about 100 per week, a 1000 per week ...
Sameer: On the order of 20 to 30 a day so that would come about to a couple hundred per week or about 1000 per month.
Netcraft shows that we have an installed base of about 20,000 on the public Internet. But that includes the virtual hosts as well so it's not 20,000 actual hosts, it's the number of domains served by a Stronghold server. It's a sort of deceiving number because they're only checking the non-SSL sites and a lot of people run Apache on their unencrypted server and Stronghold on the encrypted server. Many run Stronghold on both as well.
Obviously since we have 20,000 unencrypted sites but there's probably a higher number of people running Stronghold just on the encrypting port of their site.
Netcraft did a different survey of SSL servers where we came in second. That is, for servers in general we came out second among commercial Unix servers and fourth in commercial overall.
Jim: The Netcraft surveys that you've been referring to, is there a link to those somewhere on your web pages?
Sameer: Well, it's at www.netcraft.com. I think the surveys are on our site as well. I'm pretty proud of our Netcraft ratings so we mention that pretty prominently.
Jim: What can you tell me about C2Net as an organization? I know you used to be Community Connexions ...
Sameer: Yes, we started as an Internet provider, and a privacy provider -- protecting people's privacy on the Net. People could get anonymous accounts, they could set up anonymous web pages. We were strong supporters of the re-mailer network, we set up the anonymizer which lets people browse the net anonymously through our proxy.
That was going reasonably O.K. I was running it more as a hobby in my spare time while I was a student at Berkeley. Then I left school to start contracting at SGI down in the South Bay1.
At the end of last year we came out with Stronghold, though it wasn't called that at first. It was called "Apache-SSL U.S." and that started going really well. It became clear that we'd do a lot better selling cryptography products then w'd do at selling privacy services.
The privacy services was going O.K. but it wasn't enough to become a day job... it wasn't enough to get an office... it wasn't enough to hire people... it was pretty much a one man operation out of my house when it was just a privacy business.
So, as it was obvious that we could do a lot better by selling and deploying cryptography, we moved our focus away from the privacy services and changed our name to c2.net to reflect that change in focus and to concentrate primarily on deploying strong cryptography worldwide. So, as of a few months back, we officially had the name changed to C2Net Software Inc.
Jim: And you moved your customers over to Dave Sharnoff's idiom.com?
Sameer: ... we moved our dial-up customers over to idiom back, some time ago like, last April or so--but we were still supporting the privacy services until late last year when we move all of our web hosting and anonymous account holders to Cyberpass which is down in San Diego and is run by a cypherpunk2 who is very active in privacy and in the re-mailer network.
Jim: You mentioned that you do cryptography as your business and you just mentioned the "cypherpunks" which is where you and I first met--probably at one of the meetings on the Stanford Campus in Palo Alto. It that where you find most of your employees?
Sameer: I get most of my employees from there and from people I know at school and through other personal contacts and existing employee referrals. So I think that, of the eleven employees I have, about half of those I know through cypherpunks. We a pretty cypherpunks oriented company.
We're really the only company that's willing to deal with the fact that what the US government is trying to do with their export restrictions goes beyond just impeding or restricting export--but to create a chilling effect so that companies inside the US cripple their cryptography even for their domestic products. So we're one of the few, maybe the only company in the U.S., that's standing up to this ... that isn't willing to back down in the face of this chilling effect.
I think a lot of my motivation is related to my involvement with the cypherpunks and being involved during all the controversy surrounding the clipper chip when that was first proposed.
All of our development happens overseas so that we can do cryptography worldwide and the international versions of our products don't have to be crippled to 40-bit keys that can be broken in three and a half hours.
Jim: So your approach is similar to what Jon Gilmore and Hugh Daniels are doing with the Free S/WAN project--keeping the developers on the other end and you're providing the quality assurance on this side...
Sameer: Well, we're providing mostly the marketing, actually, and the sales. We do a little bit of QA but that's too close to the export issue. We also do the documentation--that's all written in the U.S.
The main benefit of having a U.S. office is the marketing and sales even though all of the development has to happen overseas, all the protocols and the standardization efforts, all that new stuff is all in the U.S. Stronghold conforms to protocols developed and published by Netscape, the W3 consortium and the IETF--among others.
Jim: Now, there's something I'm curious about. You've combined Apache and SSLeay which is Eric A. Young's SSL3 implementation--and those are what you've integrated in Stronghold. Then you got a license from RSA so you could include their public key libraries. So how did you approach the Apache organization with the idea for a commercial version of their free package? What kinds of licensing...
Sameer: Well, Apache is free under the Berkeley style license as opposed to the GPL which means that, if I wanted to, I didn't have to have any relationship with the Apache group. It's possible to just take Apache and, according to their license, leave in the appropriate copyright notices and just start selling a product.
But that would be kind of rude I think. I'd been involved in the group already before having any intention of changing the focus of my business. I saw a need for an SSL version of Apache that would be available within the U.S. So I started working on it and found SSLeay and I found Ben Laurie's Apache-SSL patches, which he'd done in the UK, and I integrated all of that for limited distribution within the U.S.
So I had joined the Apache group for that. I already new many of the Bay Area members socially. I became a contributor--though not as big as the people who do large chunks of the code but I do testing and help with the documentation. I have a tech writer who's a full-time employee of C2Net who does documentation that she contributes back to the Apache group.
I originally joined in an effort to support the group because I think that free software is a great thing. As the product has started doing well I think that our connection to the Apache group has been mutually beneficial. Any bug reports we get from our customers go back to them, any bugs we find, we fix and donate back. A large number of the features we've added we've also donated back. Naturally we haven't donated *all* the features since we need to maintain some proprietary value because we need to make some money as well.
Jim: Did you talk to Eric Young?
Sameer: Yes. We're in close contact with Eric. We work really well with him.
Jim: I'm not familiar with his licensing...
Sameer: Yes, both his and Ben Laurie's are very Berkeley style licenses. They are free software for commercial and non-commercial use--you just have to give credit. So in our marketing materials, documentation, and on our web pages it says "this product contains software written by Eric Young, and by the Apache Group" ... that sort of thing.
Jim: So what do you think about the GPL vs. Berkeley issue. I know this is an ongoing bone of contention between the FreeBSD and Linux camps.
Sameer: I'm generally in favor of Berkeley over GPL because I think that free software is best done in a variety of different contexts. In particular with the crypto environment, it's impossible to do completely free software inside the U.S., if it involve any public key techniques, because of the patents4.
So for doing crypto inside the U.S., because of the intellectual property issues and the patent environment, it's impossible to release products under GPL. I think that the fewer restrictions we place on our software the more people will use it.
The reason I would write free software is so that people will use it. If you put complex restrictions on your software saying that you can't sell any derivatives of it unless.... you create a lot of worry.
Perhaps the motivations of the people writing GPL software are not just to make it widely used. That's valid. But it doesn't match my personal motivations for releasing free software. It's clear that it should be properly credited and have some controls. I don't think things should be released to the public domain.
Well, I do see a lot of debate about that question--particularly on the FreeBSD mailing list. I suspect the debate and flame wars on that will go on forever.
Jim: So, how many people have you got working here?
Sameer: We have nine people here in the U.S. and two people abroad and then we have a couple of contractors. That comes out to about 14 or so.
Jim: And where are your international programmers?
Sameer: We don't say. We don't want the U.S. government and others to know which country they're in. They might then put pressure on that country to add export restrictions to their laws.
This administration has appointed a person, David Aaron, whose sole job is to convince other countries to adopt similar restrictions to ours--so that our strategy won't continue to work. Obviously if all other countries had similar export restrictions than doing development in any given one would only allow sales in that locale. That would be pointless in a global economy.
So they have this guy, David Aaron, who effectively harasses and bullies other countries into adopting restrictions for US interests. We want to ensure that he can't target the country where we are doing our development.
Jim: And no one from our government's asked? Have you had any official contact yet?
Sameer: No. Not yet.
Jim: Do you know of other companies that have?
Sameer: I've heard a lot of rumors from companies who've had visits from the NSA saying "what you're doing is wrong, you should stop it or it will do bad things to the rest of your business."
They can't do that to me because I have no other business. We do cryptography and we're at odds with export restrictions on intellectual property.
Jim: So, would you see that as your edge against Microsoft, Netscape and Sun -- that they would have other aspects of their business that might get severely hampered by the fight against cryptography export restrictions.
Sameer: Well. It's not worth it to them. It doesn't make good business sense for them. At the same time it is a business necessity for us. So any company that doesn't want to fight this battle can offload that onto us. They can license our software--and their offshore distribution agents can also license our software and they don't have to do any development. They don't have to put their business at risk over questions of cryptography technologies.
Jim: I see. Speaking of other cryptographers, I hear that Phil Zimmerman just moved to the Bay Area to found PGP Inc. Do you have any contact with him?
Sameer: No. We don't currently have any professional contact with them.
Jim: I'm confused about what happened there. Phil licensed the commercial rights to PGP to a company called ViaCrypt ...
Sameer: ... then he bought ViaCrypt--actually their parent company.
Jim: That's what I thought I'd read. So what other products are you working on?
Sameer: Well we have our "Safe Passage" web proxy. This does full strength SSL for web browsers world wide. It's currently in beta and is available at our U.K. site.
That provides a locally hosted proxy to provide full strength cryptographic capabilities to the international versions of Netscape and Microsoft browsers. As you know those are limited to 40-bit crypto when sold outside of the U.S.--denying them access to sites that require the domestically available stronger keys.
Basically Safe Passage allows a user's browser to talk 40 bit to the proxy on their system which, in turn talks to hosts out on the web. It runs under Windows.
Jim: So what do you think of the Free S/WAN project5
Sameer: I think it's a good thing. We need to provide IP level encryption in addition to the applications specific security provided by programs like Stronghold or PGP. With regards to our product line, we haven't evaluated how that might fit into our strategy. So I don't have any comment from a business perspective.
However I think, from a more personal point of view, that producing a freely available implementation of IP level encryption is a great thing. We want this deployed so that all of the Internet traffic is encrypted and especially so it's authenticated.
Jim: Getting back to Stronghold as a "commercially supported Apache Server" and leaving aside it's support for SSL and commerce... are there any companies offering just that--just a commercially packaged Apache?
Sameer: There are companies that offer Apache support services--but there aren't any that sell a supported package--where you'd get a shrink-wrapped box, with binaries, and pre-printed documentation, or anything like that. So these companies just offer the service. We offer a product--which includes e-mail support, of course.
Cygnus was doing some Apache support as well but I believe they may have dropped that. Then there was a company in South Africa, Thawte, which had a product called Sioux. We ended up buying that out and integrating its features with Stronghold's.
Sioux was released a few months after we had produced "Apache SSL U.S." We started talking to Thawte--and decided to buy that product from them to eliminate any conflict of interest for some other business that we wanted to do with them.
You see Thawte's primary business is as a CA (certification authority). So it was an amicable arrangement since it wasn't the software business that they wanted to get into.
So we are now bundling Thawte certificates with a Stronghold package. That's only fifty dollars more--which is about half the regular price of a Thawte.
Jim: So do you find that many of your customers have to go with Verisign6 for other reasons?
Sameer: Well, Thawte is gaining in popularity though their certificates are only accepted in the latest browsers from Netscape and Microsoft. So support for older versions of Netscape is probably the main reason people had been choosing Verisign over Thawte. As the PKI certification7 authority marketplace matures I hope that people will be able to choose their CA's based on reputation rather than being stuck with whatever the browser makers supported.
Right now all of the CA's are too new to have any reputations. So far Verisign is known to be well funded and Thawte is thought of as a very small company. As far as I can tell they don't have any reputation with respect to which is more reliable.
The market will have to mature, and they will each have to have time to build up a track record before people will be able to make informed decisions.
Jim: Now, back when we were talking about support you mentioned that the e-mail support is included with Stronghold and that telephone support unbundled from it. What kind of support call volumes are you getting? Are you getting a lot of calls?
Sameer: Not at all. We have an installed base of something like 20,000 according to Netcraft--and we only about three people doing support and...
... there's no person who just does support. We're a small company so everyone does a lot of different things. But we have three people who mostly do support and two people with the word "support" in their title.
So the support load isn't very high. I think that's because the product is actually very easy to use, it's intuitive and it's easy to install.
Although we sold some phone support we really prefer e-mail. People get answers that are more fully formulated and they don't have to wait on hold. Also when we use e-mail then everything is tracked and recorded so it's easy to look back on what's been tried and it's easy to forward the issue around as needed.
We've been pretty successful steering people toward e-mail support so they don't have to buy the phone support.
Jim: So I've been reading in the apache's modules lists about these php's, what are those?
Sameer: php originally stood for "Personal Home Page"--but it doesn't really mean that any more, so it's just php and doesn't really stand for anything.
php is a specific module with does dynamic content--which is the phrase I like to use for things like server side includes, and extended ssi, php, e-perl and all of these things. They are all providing dynamic content--where the page is parsed by the server and the data that's sent to the client is based on the scripting that's inside the original document.
php is what we like to use because it's easy to use, it's very robust and it offers connectivity to almost every database out there. well I should say that--there are a lot of databases "out there". It can connect to postgres '95, msql, solid, sybase, odbc, c, etc.
It's a way to embed scripting inside of your html. So, for example, you can have conditional sections what will include blocks of html based on the results of certain pieces of code. You can have an HTML page which does a database query and formats and sends information out of the database. If offers significant speed advantages over CGI since it's loaded directly into the web server. You save the load of forking off a Perl process like you'd usually get with CGI.
So Stronghold 2.0 bundles with the php module. That's in beta now. We've been using php quite a bit in house for out database connectivity and our external web site. It's very useful.
We also support the server side includes--which were in the early CERN server. Stronghold is based on Apache which also includes the "extended SSI". XSSI adds things like conditionals.
Jim: So you think these sorts of tools are better than CGI?
Sameer: Yeah. It's a lot easier to build applications--particularly where it's not a complicated application--where you just want to include a little scripting directly in your HTML. If you use a CGI script--the script has to output all of the HTML. It's just as transparent to the browser--but it's a lot faster, and it's a lot easier for the web administrator to maintain.
Jim: On a different tack, you've got a proxying client that brings international versions of the standard browsers up to domestic standards of cryptographic strength. that puts you pretty close to the browsers. Where do you see the browser market going? In the browser wars what would you like to see come out of it?
Sameer: Hmm. That's tough to say. I think there's no alternatives to the Netscape and Microsoft browsers at this point. It's hard to say if one will destroy the other. It's such an open subject, maybe you could be a bit more specific?
Jim: Well--do you see Java doing anything significant
Sameer: I think Java has some potential for distributed computing. it has a long way to go. it's rather unfortunate Microsoft has decided to create it's own proprietary version of Java.
Then there's javascript--which isn't Java at all. So Netscape's decision to rename live script to "java"-script and that's added confusion to an already confused marketplace.
I think javascript is interesting because there are a lot of potential security problems in it's design. Some versions of Java have implementation problems. Those can be fixed. The design of Java pays due care to security considerations.
However when a language like javascript is designed with out any security in mind--you can't fix it.
Jim: In other words "implementations can't fix fundamental design flaws."
Sameer: So the danger is that it [javascript] has a similar name [to Java]-- and it is useful for building Intranet applications where hostile applications are not a security concern. So javascript can be used to connect to internal HR data applications or to an order entry system and make the interaction a lot easier.
Javascript's features allow you to make your client more active--so the user doesn't have to send everything to the server to get feedback from your web forms.
The problem is that there is currently no provision to restrict the browser--to say "I'll accept javascript from within my network but not anything from anywhere else" or "I'm willing to accept javascript from these people but not them."
Once it gets to that point I think javascript will have more of a future and offer real benefits.
Jim: Could you add those features to your client side proxy--the filtering that is?
Sameer: It could be done. It would be a lot of work and I'm not sure there'd be enough of a market for it. I think it's best done in the browser.
Hopefully Netscape will add that to their features set soon.
I usually have Javascript disable--but I see some cases where I'd like to use it. If I could just turn it on for those applications it would be very nice.
Java is much closer to secure deployment and authentication.
Jim: Speaking of authentication--I have a question about SSL. Currently the whole SSL view of the world, brought to us by the Netscape Commerce Server, is all about the server authenticating itself to the client--about web sites saying "You've reached me--and not some imposter and there's no man-in-the-middle and we can exchange information privately."
This doesn't seem to offer anything for the client to authenticate itself to the server other than manually typed passwords. So maybe that's a feature that we'd like to see in the browsers--is some sort of client authentication certificates for SSL.
Sameer: Actually that's already in there. Stronghold already supports client authentication. the SSL protocol added that in version 2. Netscape supports client certificate authentication starting with Navigator version 3 which is built about SSL version 3.
Stronghold was the first widely used, commercial server to support SSL client authentication. So now that we have the support in the browser and our server it's only a question of user acceptance and getting sites to start using it.
I think that the SSL client auth. is an excellent technology. We're using it extensively here at C2Net. Because we have people from all over the world we can't really have this big private WAN and we can't set up a VPN8 using something like Free S/WAN--because it isn't even ready yet.
So we issue client certificates to all of our employees. We have a Stronghold web server where our sensitive information is stored and an employee can connect to that server from wherever they are on the Internet and access business information. They are protected by full-strength cryptography and RSA encryption on the client side.
It's an incredibly empowering technology because we don't have to worry about making people come into the office to get this information. they can do it from home and the can do it securely.
Jim: So you don't have to worry about static IP addresses, and boring holes in your firewall and packet sniffers on your ISP's routers, and ....
Sameer: Right. As long as they have their client certificate on their laptop. You know I have a ricochet [ed. note: Metricom Ricochet are wireless modems that are popular in the Bay Area because they offer flat rate unlimited wireless PPP to modem users]--and I can do anything from my laptop through that.
I can review support questions, work in the bug tracking database, I use SSL to do logins. That isn't a product of ours.
Jim: I met Tatu Ylongen, author of ssh, at the IETF a couple of months ago. He's started his own company, too. I guess he does all the development and has Data Fellows doing all of the licensing.
Sameer: That's right. Data Fellows is doing all of the sales and marketing while he's doing the development.
Jim: So do you see C2Net coming out with, maybe, an ssltelnet and sslftp to compete with ssh?
Sameer: Well, we can talk about all the details of all our product ideas. there already is an ssltelnet and sslftp. nobody's supporting them and nobody's using them yet.
So I think, that as far as encrypting, secure shell logins and file transfers ssh is the best product out there. Although it's a different authentication protocol, not like the SSL between my browser and my web server--but it is RSA based and I can use my copy of ssh through my ricochet and login to my servers here.
Jim: So, if you were to configure all your systems here--presumably all Unix boxes, and you took out all of the unencrypted and weakly authenticated services you could almost run without any packet filters or firewalls--except to prevent address spoofing.
Sameer: We have packet filters on all the non-encrypted services--because there are still a number of useful services for use just within the private network. We don't allow any non-encrypted packets to pass through.
We allow ssh for logins and SSL for employee access to our internal web servers. Those both offer strong authentication--and the SSL is only accessible to people who have a C2Net employee certificate installed on their system.
Jim: Does the Netscape navigator support a "pass phrase" to unlock the locally installed certificates, like PGP does with your signature keys?
Sameer: Yes, it has some system where you use a pass phrase to encrypt your private keys.
Jim: So if you lose a laptop you don't have to run right into the office to revoke those certificates. Hopefully their crypto on that is strong enough to give you a few hours.
Sameer: I'm not sure what they use. Safe Passage uses DES [ed. note DES= Data Encryption Standard] You see browsers that support client certificates have to do RSA key generation. So the international versions are limited to 512 bits for the key. That means that Safe Passage has to proxy the support for the SSL client authentication as well. That puts the international client on an even footing with any of the domestic browsers since Safe Passage is actually connecting to the web servers for the browsers.
Another benefit of using Safe Passage is that it provides an integrated location for all your certificate keys if your using different browsers.
One of the problems with client certificates right now is that Netscape and Microsoft don't have a published interface for managing the keys that are installed in each. In other words if you've have a certificate in Navigator you can't transfer it to your copy of Internet Explorer and if you have a Navigator SMIME9 you can't transfer it into Eudora.
So Safe Passage helps by allowing you to use just one certificate database. We plan to offer an easy way to extract those certificates -- though we haven't figured out quite what that will be, yet.
There are standards emerging on how to do this--and we will be supporting those standards, of course.
Jim: Now this proxy is only available for Win 95, and NT
Sameer: ... and Win 3.1
Jim: Are you planning on release a Unix/Linux version of that
Sameer: Making it available for Unix wouldn't be difficult. It was actually prototyped under Unix and then ported to Windows and there a graphical interface was added to it.
However, there isn't much of a market demand, and we are a small company, so we can't afford to support Unix and Mac on it for now. We'll need to get some more resources before we could broaden that support--as much as I'd like to do it.
Jim: So, what else can you think of that just HAS to be said?
Sameer: The key thing that we, at C2Net, are focusing on is the worldwide deployment of cryptography. I think it's vital that we deploy strong crypto worldwide in the very near future.
The U.S. government has made it clear that their intent is to make the personal use of strong cryptography completely illegal. So, the deployment has to happen before they do that. If these crypto products aren't ubiquitous before that we'll have a have a much harder time in protecting our privacy.
I see cryptography being used for much more interesting things than just protecting credit cards. While I think that it's prudent to encrypt your credit card number before sending it over the 'net--it's not an interesting application of strong cryptography.
So we want to build an infrastructure so that restrictions on personal use of privacy technology will have major business implications ... so that privacy itself cannot be made illegal.
Do you find yourself having lots of different unsorted and more or less old backup files lying around when working on something, but do not dare to delete any of them because you might need to go back and find out what changes you have made compared to your current version ?
Would you like to get all those backups out of the way (without reducing the number of backups), have them sorted and systemated, and perhaps even with some sort of documentation like exactly when changes where made, by who (when several persons are involved), and a few lines that describes the changes which can be the input of an automatically made change-log ?
In that case read on because RCS will do that for you.
Lets have a look at an example (a traditional hello world program) of what RCS can do:
(hlovdal) localhost:/tmp/rcstest>ls -l
total 0
(hlovdal) localhost:/tmp/rcstest>cat > hello.c
/*
* $Id: issue20.html,v 1.1.1.1 1997/09/14 15:01:51 schwarz Exp $
*
* $Log: issue20.html,v $
* Revision 1.1.1.1 1997/09/14 15:01:51 schwarz
* Imported files
*
*/
main(){
printf("hello world");
}
(hlovdal) localhost:/tmp/rcstest>gcc -o hello hello.c
(hlovdal) localhost:/tmp/rcstest>./hello
hello world(hlovdal) localhost:/tmp/rcstest>ls -l
total 5
-rwxrwx--- 1 hlovdal hlovdal 3928 Jun 28 01:01 hello
-rw-rw---- 1 hlovdal hlovdal 60 Jun 28 01:00 hello.c
(hlovdal) localhost:/tmp/rcstest>
(The two $-tags in the comment are for automatically documentation, more about those later)
Our hello world program works now, so we would like to save it in it's current state before making any changes to it. This is done by running ci, Check In, on the source file. That is, the source file is put into the RCS database. When the file is checked in, it is by default also removed from the current directory.
(hlovdal) localhost:/tmp/rcstest>mkdir RCS
(hlovdal) localhost:/tmp/rcstest>ci hello.c
RCS/hello.c,v <-- hello.c
enter description, terminated with single '.' or end of file:
NOTE: This is NOT the log message!
>> A plain simple hello world program
>> .
initial revision: 1.1
done
(hlovdal) localhost:/tmp/rcstest>ls -l
total 5
drwxrwx--- 2 hlovdal hlovdal 1024 Jun 28 01:02 RCS
-rwxrwx--- 1 hlovdal hlovdal 3928 Jun 28 01:01 hello
(hlovdal) localhost:/tmp/rcstest>
By looking into the RCS directory we can now see that there is a file with the same name as our program with an extra extension ",v". (By omitting the RCS directory the file would be in the current directory) This file now holds the source plus some additional information, and will later on contain the source for all versions. The rcs file is not particularly interesting to look at directly:
(hlovdal) localhost:/tmp/rcstest>cat RCS/hello.c,v
head 1.1;
access;
symbols;
locks; strict;
comment @ * @;
1.1
date 97.06.28.01.03.43; author hlovdal; state Exp;
branches;
next ;
desc
@A plain simple hello world program
@
1.1
log
@Initial revision
@
text
@/*
* $Id: issue20.html,v 1.1.1.1 1997/09/14 15:01:51 schwarz Exp $
*
* $Log: issue20.html,v $
* Revision 1.1.1.1 1997/09/14 15:01:51 schwarz
* Imported files
*
*/
main(){
printf("hello world");
}
@
(hlovdal) localhost:/tmp/rcstest>
This our first version of the hello world program sort of worked, but it lacks an ending newline and the source isn't pretty. Lets fix that. The source was moved when it was checked in, so we must use co, Check Out, to copy the source out of the RCS database.
(hlovdal) localhost:/tmp/rcstest>co hello.c
RCS/hello.c,v --> hello.c
revision 1.1
done
(hlovdal) localhost:/tmp/rcstest>ls -l
total 6
drwxrwx--- 2 hlovdal hlovdal 1024 Jun 28 01:02 RCS
-rwxrwx--- 1 hlovdal hlovdal 3928 Jun 28 01:01 hello
-r--r----- 1 hlovdal hlovdal 189 Jun 28 01:04 hello.c
(hlovdal) localhost:/tmp/rcstest>
Note that co by default fetches the source read-only. This is usually not what we want, so in order to get the source writable we use the "-l" option to mark the file locked for others.
(hlovdal) localhost:/tmp/rcstest>co -l hello.c
RCS/hello.c,v --> hello.c
revision 1.1 (locked)
done
(hlovdal) localhost:/tmp/rcstest>ls -l
total 6
drwxrwx--- 2 hlovdal hlovdal 1024 Jun 28 01:02 RCS
-rwxrwx--- 1 hlovdal hlovdal 3928 Jun 28 01:01 hello
-rw-r----- 1 hlovdal hlovdal 197 Jun 28 01:05 hello.c
(hlovdal) localhost:/tmp/rcstest>
By looking at the hello.c file we see that now some values have been inserted into $Id: issue20.html,v 1.1.1.1 1997/09/14 15:01:51 schwarz Exp $ and $Log: issue20.html,v $ inserted into $Id$ and Revision 1.1.1.1 1997/09/14 15:01:51 schwarz inserted into $Id$ and Imported files inserted into $Id$ and.
(hlovdal) localhost:/tmp/rcstest>cat hello.c
/*
* $Id: issue20.html,v 1.1.1.1 1997/09/14 15:01:51 schwarz Exp $
*
* $Log: issue20.html,v $
* Revision 1.1.1.1 1997/09/14 15:01:51 schwarz
* Imported files
*
* Revision 1.1 1997/06/28 01:03:43 hlovdal
* Initial revision
*
*/
main(){
printf("hello world");
}
(hlovdal) localhost:/tmp/rcstest>vi hello.c
...
We makes a few changes. Exactly what was changed can be examined with the program rcsdiff.
(hlovdal) localhost:/tmp/rcstest>rcsdiff hello.c
===================================================================
RCS file: RCS/hello.c,v
retrieving revision 1.1
diff -r1.1 hello.c
9,10c9,14
< main(){
< printf("hello world");
---
>
> #include <stdio.h>
>
> int main(int argc, char *argv[]){
> printf("hello world\n");
> return 0;
(hlovdal) localhost:/tmp/rcstest>
The rcsdiff program is just a front end for ordinary diff, so it accepts all the options to diff, for example "-u".
(hlovdal) localhost:/tmp/rcstest>rcsdiff -u hello.c
===================================================================
RCS file: RCS/hello.c,v
retrieving revision 1.1
diff -u -r1.1 hello.c
--- hello.c 1997/06/28 01:03:43 1.1
+++ hello.c 1997/06/28 01:05:21
@@ -6,6 +6,10 @@
* Initial revision
*
*/
-main(){
-printf("hello world");
+
+#include <stdio.h>
+
+int main(int argc, char *argv[]){
+ printf("hello world\n");
+ return 0;
}
(hlovdal) localhost:/tmp/rcstest>
This version looks good, so we want to save it with Check In. By giving option "-l", ci runs a implicit "co -l" so that the source file remains checked out. When ci is run we are asked to enter a log description of our changes. This log description is inserted into $Log: issue20.html,v $ our changes. This log description is inserted into Revision 1.1.1.1 1997/09/14 15:01:51 schwarz our changes. This log description is inserted into Imported files our changes. This log description is inserted into.
(hlovdal) localhost:/tmp/rcstest>ci -l hello.c
RCS/hello.c,v <-- hello.c
new revision: 1.2; previous revision: 1.1
enter log message, terminated with single '.' or end of file:
>> Fixed main prototype, inserted a missing newline and a missing #include
>> .
done
(hlovdal) localhost:/tmp/rcstest>cat hello.c
/*
* $Id: issue20.html,v 1.1.1.1 1997/09/14 15:01:51 schwarz Exp $
*
* $Log: issue20.html,v $
* Revision 1.1.1.1 1997/09/14 15:01:51 schwarz
* Imported files
*
* Revision 1.2 1997/06/28 01:07:23 hlovdal
* Fixed main prototype, inserted a missing newline and a missing #include
*
* Revision 1.1 1997/06/28 01:03:43 hlovdal
* Initial revision
*
*/
#include <stdio.h>
int main(int argc, char *argv[]){
printf("hello world\n");
return 0;
}
(hlovdal) localhost:/tmp/rcstest>gcc -o hello hello.c
(hlovdal) localhost:/tmp/rcstest>./hello
hello world
(hlovdal) localhost:/tmp/rcstest>
For more info on RCS look at the rcsintro(1) man page.
Here in this example RCS is used on C source, but RCS can be used on many other things. Config files in /etc are for example excellent candidates of being put under RCS control.
RCS is one method of version control. Two others are SCCS and CVS. CVS (Concurrent Versions System) is a further development of RCS intended to be used on larger software projects. For example most (?) BSD clones are distributed and developed using CVS.
SCCS (Source Code Control System) is an old proprietary system which few (if any) uses. I think SCCS and RCS have a somewhat a similar relation as traditional compress vs gzip.
When you tell people that you are using Linux, their first comment often is "yes, a fine and interesting operating system for programmers and scientists, but not for ordinary people. There is no good applications software for it". Unfortunately, until just a couple of years ago, this remark was all too appropriate, especially where word processing was concerned.
It is only in recent years that the situation has begun to improve, with some good packages -- commercial, to be sure -- becoming available to UNIX in general, and to Linux in particular. E.g. Applixware, a complete office suite which received very good reviews in a recent article in Linux Journal, and the freeware-like Star Office package. Both of these contain very conventional word processing modules.
And yet -- TeX/Metafont, developed by Donald Knuth, and LaTeX, an extension written in TeX's macro language, from the hands of Leslie Lamport -- both systems further extended by a host of volunteers -- have existed for over a decade: free, publicly available, and good, very good. This is not WP any more, this is typesetting. You only have to look at a LaTeX-produced document, especially mathematics, to see the difference...
Until recently, the only way to use this software was by manually editing the source code of your document using the defined mark-up language -- the manual opened by the side of the keyboard. And writing formulas was a real pain in the butt. But mathematicians loved it! The beauty of LaTeX is, that it allows you to specify on a fairly abstract level the structure of a document, without bogging you down in details of the actual formatting.
Many science journals also distributed macro packages for TeX or LaTeX to help people write their articles in the prescribed standard format; thus, TeX became also an exchange standard for scientific manuscripts. (If only my Word for Windows would agree to produce the same page layout for my papers at home as it does at the job!)
Mark-up language. We have all heard of the mark-up language of the Web, HTML. Have you ever wondered how many web pages would be published in the world, if they all had to be edited by hand in raw HyperText Mark-up Language? Not many, I daresay. Everybody uses interactive, graphic tools, that show you here and now what your becoming web page looks like while you write it.
Several years ago, Matthias Ettrich from T�bingen University's computer science department, decided to do something about it. Also LaTeX needed an editor that was easy to use and showed you interactively, on the screen, how the document was to be structured; and then, on your order, generated the LaTeX code containing all the embedded commands needed for the typesetting job. Ettrich's first attempt was called Lyrix, but the name had to be changed to LyX for legal reasons.
Other volunteers in several countries joined the effort and, a year ago, a first beta release, 0.10.7, was published on the Web. It was in no way perfect or complete; not even all of the most common LaTeX features were supported. Yet I was interested enough to try it, and here are my first impressions.
For testing, and for writing this article, I use an Intel i486sx system running at 33 MHz (yes, LyX runs somewhat sluggishly, but at my job, on a 75 MHz Pentium, it flies), with 8 MB of memory and some 1.5 GB of Linux-dedicated disc storage. Last January I had installed RedHat 4.0 ("Colgate") and LaTeX2e the version required by LyX.
At the time when I started with Linux, in February this year, the LyX documentation was still pretty poor, but last June, a much improved documentation package has been published. About myself: I have some UNIX experience from half a decade ago (those Unices are hairy dogs next to Linux today), but my only previous experience with LaTeX has been occasionally printing out files that colleagues sent me.
LyX has many sites dedicated to it around the world. We list them here shortly. At them, you can find further links.
The "home site" for posting LyX material is the French machine, where new versions of LyX-related stuff are usually found first. Also the German LyX site in T�bingen is of interest. There also can be found links to a large number of other web sites dedicated to LyX on both sides of the Atlantic. In one of them, I even found a screen shot of LyX containing Chinese text...
There exists another LaTeX editor apparently designed along similar lines as LyX, for the MS Windows environment. It is a commerical product named "Scientific Word", said to be very good by its makers (of course!). I do not know any users however. Can anyone enlighten me? I also do not know if any Linux/UNIX version exists, as I for one do not fancy much the idea of having to use TeX in a DOS/Windows environment! But perhaps I am prejudiced...
My Linux version on CD-ROM contained a pre-version of LyX in the "Contributed" department, which did not work properly. On the Web I found the beta version 0.10.7 and downloaded it, a *.tar.gz file ("tarball").
The utility mc (Midnight Commander), a workalike of that other famous commander for DOS, allows you to look inside *.tar.gz and *.rpm (Red Hat Package Manager) files. Useful!
Inspecting the file with mc, or more traditionally, with the command
tar -tzvf,
is followed by unpacking it with the command
tar -xzvf
into a pre-created directory lyx.
To the beginning user, the tar command may seem forbidding with its scores of command line options. However, when using disk files rather than tape reels, you only need to know half a dozen of them; for creating an archive, scanning it, unpacking it, optionally gzipping/degzipping (GNU tar only!) and for giving the archive filename.
For help on all these options, use the on line help by typing
man tar
or
man info
or even better, their modern GUI equivalents
tkman tar
or
tkinfo tar.
Similarly you find help for any other command that you are interested in. The last two programs are good demonstations of the power of the tcl/tk scripting language, a sort of Visual Basic like (no insult intended) freeware thing running in a variety of windowing environments. Download recommended!
I created a directory lyx under /home, and expanded the downloaded package there.
First complication: LyX expects to be in /usr/local, being a standard place. If it is somewhere else, one must add the proper definition LYX_DIR to bashrc and LyX knows where everything is.
Next problem: To tell Linux where LyX is. As the binary executable was now in /home/lyx/bin/lyx, I solved this by putting a symbolic link into the executable directory /usr/bin, located in the shell's search path:
ln -s /home/lyx/bin/lyx /usr/bin/lyx,
and that's it. Symlinks are handy!
After that, LyX worked obediently from anywhere on the system.
One can create an alias:
lyx="lyx -width 600 -height 350",
with whatever values may be suitable to make the LyX window fit your screen.
To make also the man system find LyX's man pages, you should edit /etc/man.config, or alternatively (mandatory for tkman) define the shell variable MANPATH. Consult the relevant documentation.
There is a file .lyxrc in your home directory (or you should copy it there from the template in the distribution), which should be edited suitably. I found e.g. that the screen font utopia was lacking, and replaced it by times. Also the T1 font encoding did not work for the Scandinavian special characters, so I chose "default" instead; and input encoding "latin1". All the other editable options in the file are provided with helpful comments.
Some more tinkering with config files is needed to make everything work together. LyX, xdvi (print pre-viewer), ghostscript/ghostview (ditto; I found version 4.03-1 satisfactory, an older version proved buggy), dvips (printing module) and /etc/printcap, the file describing, or "retrofitting" by software, the capabilities of your printer. Fortunately the new, extensive LyX manual contains lots of info on these standard chores that any Linux user has to go through in order to make the printer work under Linux, and especially with TeX -- LyX or no LyX.
There are many other things you can or perhaps ought to do to make LyX live happily on your system; e.g., add it to the menu system of TheNextLevel. Let us hope that the packagers (Red Hat and others) will "discover" LyX and proceed to do all this tinkering on our behalf, so inexperienced users will not give up too easily before the slings and arrows of complexity...
The general answer to this is, based on my preliminary experiences: Yes!
It must be said that the software is not bug-free; but a segmentation fault is a rare event running LyX.
One annoying bug is that, when running LaTeX in the background after having just opened a file in the LyX window, control may not return to the foreground and one has to kill the job by control-C. (Obviously one does not lose any data due to this bug, only time.)
Also, many features in LaTeX -- some trivial -- are not directly supported by LyX or do not quite work as they should. I had trouble, e.g., with the Bibliography environment. But the more I got to know LyX, the more I learned to like it -- especially since it supports a transparency mode in which LaTeX commands are handed through unmodified to output. All you have to do is "paint" the LaTeX command red, using the mouse and the LaTeX toolbar button, and LyX skips all the processing there. This means that all commands not available directly in LyX, can be had by brute force, through the back door, in spite of LyX -- a technique at which I rapidly became proficient.
[Do-it-yourself 'bibliography' screen shot]
In fact, it is possible to use LyX simply as a "dumb editor" for LaTeX source code -- the way scientists have been using vi, emacs and all that. In this fashion, one gains nothing and loses nothing. As an editor, LyX is quite good, allowing you to set layout details, such as indent and alignment, for individual paragraphs, and character layout, such as font shaps and sizes, empasized, small caps, etc. for selected areas of text; as well as all that for the document as a whole (of course already this basic editing is translated internally to LaTeX mark-up).
But already using one of LaTeX's many "difficult" features supported by LyX -- the formula editor, say -- results in massive gains to the user, making the editing job quite essentially easier.
Anecdotical evidence: one of my German colleagues admitted that he has kept his LaTeX skills hidden from his university employer, because he hates writing -- nay, programming -- formulas and does not want to be ordered to do that.
We computer people should never underestimate the difficulty that programming (and mark-up language is a programming paradigm) poses to computer-naive users!
As a scientist I have to be able to write formulas easily and correctly. Therefore of course I wanted to put the math editor through its paces. The competition, MS Word for Windows, has a very good math editor (apparently sublicenced from a smaller company) and the litmus test for LyX is measuring up to this standard. Here follow some formulas that I often use in my work, first of all the expansion into spherical harmonics of the Earth's gravitational potential (W.A. Heiskanen and H. Moritz: Physical Geodesy, W.H. Freeman & Cy., 1967, p. 107):
...and in the print previewer (xdvi).
Another formula frequently encountered in physical geodesy is the Stokes integral, named after G.G. Stokes, the famous mathematician who in 1849 discovered this relationship between the global field of gravity anomalies (delta-g) and the undulations of mathematical mean sea level or the geoid N:
where the Stokes function S is defined by the same picture
So, what should the conclusion be? I did not write these two formulas as fast as I would have done in the WfW Equation Editor; but faster than when I did that for the first time, many years ago (�bung macht den Meister). And it most certainly beats manual LaTeX coding in both speed and convenience!
The Math Editor is good, intuitive, interactive and a fine piece of programming. Some small additions would be needed still. A few of the weirder mathematical symbols are still lacking -- they could be added to the math panel in their raw LaTeX form --, and one does not get the integration domain placed straight underneath the integral sign, like with the summation limits to the big Sigma sign. In display mode, these limits, which are entered as "index" and "exponent" -- nice touch! -- end up straight underneath and above the Sigma, see above.
To number equations, just push "insert label" inside the equation box and follow the crowd. You may use symbolic names for the formulas which will appear when you try to insert a cross-reference. Just take your pick. LaTeX will replace the references by numbers in the right sequence.
The standard functions sin and cos should be entered in "macro mode" prefixing them by a backslash. They are correctly displayed in roman. But you have to remember the function and symbol LaTeX names... not hard for sines and cosines, though. Placing them somewhere in the math panel would be a good idea also.
Also plain roman text can be entered, by a keystroke sequence documented in the User's Guide. Sub- and superscripts are entered in the traditional LaTeX way by prefixing with an underscore or a "hat" symbol.
One way in which LaTeX math mode is superior to Word for Windows is in changing the font size. If you change the default font size in a LaTeX document, all fonts, including those inside formulas, change proportionally along, without any special effort from your side. In WfW you have to separately change the standard font size inside the formula editor, and then click on every formula... I like it more the LaTeX way.
Perhaps formulas and equations are a too specialized property to convince the ordinary user to switch to LyX. But what about something more down-to-earth, such as section, subsection, subsubsection etc. headers?
In short: excellently supported. LyX shows the header numbers on-screen, changing them if material is added or removed. What's more, you can open a table-of-contents panel where you can quickly navigate within large documents. (In Word for Windows, this would correspond to "outline mode". But you do not have to switch modes in LyX, just click on the right header in the TOC panel.)
Like we discussed above for formulas, also section headers etc. may be referred to by embedding labels in them. These labels appear in a label panel that pops up whenever you want to insert a reference; nifty. One can refer either to the (sub-) section itself, or to the page it is on, like in "see Section 3 on Page 7". If you move material around, the numbers in the printed output may change, but not the labels.
[Using section and page references]
If you want a section header without a number, you use the alternative form section* (and equivalent sub- and subsub- forms) from the styles menu. These headers will then also not appear in the table of contents. If you want the header to appear there after all, you'd better open your LaTeX Companion, page 36, and add the command
\addcontentsline{toc}{section}{Section headers and friends}
painted in LaTeX red, of course.
Also nicely supported. These can be put into a "float", to be positioned suitably on the page (as LaTeX) does. The figure can contain a caption; captions are numbered and collected into a List of Figures/Tables. They can also be referred to -- you guessed it -- by embedding a label into the caption text.
LyX 0.10.7 shows *.eps (encapsulated postscript) figures on the screen, and so does the print previewer xdvi. I have noticed, however, that LyX does not display large pictures, which do come out nicely in print.
[The EPS popup for embedding graphics]
EPS pictures can be drawn using the facility xfig, which has a complex and somewhat cumbersome user interface that takes some time to learn. (Anyway, it beats the drawing tool packaged with WfW 6, which was a great disappointment after the nice one packaged with WfW 2.) Also bitmapped pictures can be generated in EPS format, e.g. by using the screen grabber facility import, part of the ImageMagick package (recommended!). In this way, the screen shots for this article were produced, in a bitmapped graphics mode, though.
One weakness I noticed in LyX was the lacking support for the LaTeX figure* and table* commands, which place a figure or table float across the full width of a two column page. (But, then, one easily inserts these commands manually, painting them red...)
[A do-it-yourself full-width figure float, with labeled caption]
And footnotes, of course. (But no thanks command support!)
One of the well known niceties of LaTeX is also the three "nested environments" (enumerate, itemize, description) for making numbered/bulleted/labeled lists. LyX supports these on-screen roughly as they will be on paper, with the numbers or letters showing for the enumerate environment. And they can be freely nested, four levels deep. Great!
Tables are nicely supported, with a fully functional (IMHO) table editor hanging from the right mouse button. The LyX team claims that this editor is buggy/incomplete/both, but it has satisfied at least my modest needs. The tables intelligently expand and contract depending on what they contain, just like in the LaTeX paper output. You can add and remove columns, put horizontal and vertical lines in the table or suppress them, and even join neighbouring cells. Text alignment can be set column-wise, like in LaTeX: left, right or centred.
[A table example, from the Users Guide]
All the main menus given on the menu bar can be activated by pressing M-<letter>, the letter being the underlined one. Pretty logical, "Windows-like" and also documented somewhere in the set of documents in the 0.10.7 distribution.
What can be discovered by trial and error -- and is now also in the documentation --, is that M-<letter> followed by <space> pulls down the menu in question. A clever compromise saving CPU time on slow machines. And the submenu letters are given in the status line below the text screen anyway, if you hesitate... excellent design!
I was happy to find that my left hand finger reflex "Alt-F S" also here saved the file to disc. Use it frequently!
There are two different key binding maps available, the PC-like one (preferred by me, at least) and an emacs-like one for the aficionados.
LyX has also a good Find (and Find/Replace) facility
Cut and paste works within a document, and between two simultaneously open documents (only one of them is always visible). Also import from other applications works; export not yet.
LyX 0.10.7 as distributed supports almost all the standard LaTeX2e textclass types: article, report, book, letter and amsart ("American Mathematical Society article"). Furthermore, a special mode for Linuxdoc SGML format is provided, used here to produce this text. Making overhead transparencies and slides is semi-supported.
This is of course only the tip of a substantial iceberg: according to The LaTeX Companion (M. Goossens, F. Mittelbach, A. Samarin, Addison-Wesley 1994) there exist over 150 packages catering for the most varied publishing needs -- from sheet music to Feynman diagrams, and everything in between. It will be some time before LyX catches up!
Adding new textclasses is not difficult. First, the textclass file for LaTeX should be found (on the web, usually) and installed, if not already on your distribution; these files have the extension .cls. Then, a so-called layout file must be created -- usually based on an existing one such as article.layout -- in which the known properties of all the major commands and environments for that textclass are described. If this is done properly, LyX will make these styles behave on-screen in ways similar to LaTeX on the printed page. In other words, the near-WYSIWYG property.
I wrote myself a few such layout files for journals I contribute to; One thing I discovered the hard way, is that to make LaTeX recognise a new class file, you have to run
texhash
and to make LyX find a new class and layout file pair, you have to first edit the file chkconfig.ltx, and then run
latex chkconfig.ltx
One learns by doing.
After bringing out the 0.10.7 version, the LyX team proceeded to develop successive versions of 0.11. Unfortunately they have had no end of trouble with bugs; only now, 0.11.X is starting to be relatively clean and fully functional again. They replaced XForms, a library of graphic elements to be used under the X windowing system to produce user interfaces, by a similar but supposedly better library Qt; also many messy though functioning parts of the code have been sanitized.
One change in the making is the introduction of inheritance between .layout files; then you can say that a new texclass in LyX has all the properties of e.g. article, but with some added and some modified. In this way the work of writing new layout files, and of maintaining them, can be greatly reduced. LaTeX connoisseurs will recognize this technique as a carbon copy of the corresponding LaTeX practice, and will facilitate the "catching up" job for LyX.
Currently the Layout/Document menu offers a choice between various paper sizes, and for DIN A4 also a choice between a few standard margin width alternatives. Free setting of the margins by the user is not yet supported. Also this is scheduled to change. While waiting, you can use the geometry style package, which you should activate by including the lines
\usepackage{geometry}
\geometry{various page size and margin width options}
into the preamble of the LaTeX document. This is done from within LyX through the Layout menu. You see that one can still not do without a basic understanding of LaTeX...
One thing I intend to try out still is to use the mailmerge facility which is available for LaTeX inside LyX. It can surely be done, but a day has only 24 hours...
Concludingly I will say that the LyX system, though being still a little rough around the edges, actually works well, is, inspite of the beta label, already production quality and really makes exploiting the unique properties of LaTeX a great deal easier. In fact, I would venture to claim that, once installed, LyX 0.10.7 is no more difficult to use than the leading commercial WP packages for MS Windows -- a remarkable claim perhaps for software that does so much more.
What I like about the LyX philosophy -- and there has been some debate on this in the newsgroups also -- is that it does not try to cover up the true complexity of typesetting text, a complexity properly addressed by LaTeX; it just harnesses the built-in intelligence of this existing typesetting software to make the handling of it more easy and intuitive. And that is how it should be.
Traditional word processors -- no names mentioned -- do give you more freedom to format the text as you want; remarkably, this is not always a good thing. It is easily possible to generate documents that look precisely as tasteless on screen as they come out on the printed page!
Of course there are things which by their nature are best done in a WYSIWYG fashion, e.g. the editing of mathematical formulas which are among the most visual typographic objects known to man. Also the logical structure of a document, its division in chapters, sections etc., is an essential property that must be visually represented. But other aspects of typesetting are not intrinsically visual -- e.g. the division of a paper into pages is more a property of paper as a hardware medium than an intrinsic property of a text. Also page headers, page numbers etc. are only "programming devices" targeted at us, flesh-and-blood browsers of printed text. This surface structure of the written message is inessential, and LyX rightly tries to handle this elegantly outside the user's field of view.
Everything in this text above that resembles a trademark, probably is one. Contrary perhaps to the impression created above, I hold Microsoft(tm) Word(tm) for Windows(tm) to be an excellent piece of software, arguably the best in its category. I have been a happy user myself for four years. It is the market leader, a de-facto standard against which others are measured.
And that LyX, and LaTeX, measure up so well, does not reflect poorly on the Microsoft programmers' skills; the message is a positive one, about the benefits of standing on tall shoulders -- each other's shoulders. LyX, TeX, Linux, all have simply grown in a better environment, one of openness, civic spirit and genuine enthusiasm, rather than of dollars and lawsuits. That freedom makes excellent economic sense has been known since Adam Smith. Resisting its pull is futile!
When I was asked to write this article for Linux Gazette, the suggestion was made to write it with LyX and convert the LaTeX code to HTML using the conversion utility latex2html. I installed and tried out this utility at my job computer (the Pentium!) and decided against using it. It was very demanding on the CPU, especially when converting formulas into GIF pictures.
Therefore I chose the alternative of writing the text in the Linuxdoc SGML textclass, which is supported by LyX. (I should say that this support is a little sketchy still at this point. It is easy to produce SGML files by LyX that the converter chokes on, e.g. containing tscreen, supposed to indent text.)
Then, conversion by sgml2html, included in the linuxdoc-sgml package -- runs very quickly -- and possible embedded pictures can be added only after that, using the Netscape HTML editor, if you have it installed. Obtaining these pictures, screen shots, was easy enough with ImageMagick.
Finally, UNIX wouldn't be UNIX, if there was not a quicker way to change the colours of background and text of all the .html files obtained from the conversion run:
#!/bin/bash
#
# Add background and text colour to an HTML document
#
for i in *.html
do
sed -e s'/<BODY>/<BODY bgcolor=\"fff0e8\" text=\"503000\">/g' $i >temp
mv temp $i
echo $i
done
exit 0
lilo as bootmanager, I boot with an additional variable assignment. The kernel passes this to the init-processes shell environment. So all processes started by init can use it. Example:
linux netoff=
This sets up the variable netoff. It is assigned nothing. I use it as a flag meaning "now I am in the office". Booting with linux netetc= means "now I am at customer site". Using lowercase variable names is just for convenient typing. If you prefer, you can use something like NETENVIRON=123.
The real work of processing this variables is done in my /etc/init.d/netenv. Take a look at this code fragment:
NETENV=/tmp/netenv # When located in /tmp, script must be called
# AFTER wiping out /tmp has been done ...
...
elif env | grep '^netoff=' > /dev/null; then
(
echo ""# Networkenvironment: Laptop at office (Network-Interface: Ethernet)"
echo "export PROFILE=31"
echo "IPADDR=\"123.456.78.123\""
echo "NETMASK=\"255.255.255.0\""
echo "NETWORK=\"123.456.78.0\""
echo "BROADCAST=\"123.456.78.255\""
echo "GATEWAY=\"123.456.78.1\""
echo "DOMAIN=\"rw.sni.de\""
echo "DNS_1=\"123.456.89.9\""
echo "export RLPR_PRINTHOST=printer-off"
echo "export PRINTER=pr1"
) > $NETENV
elif env | grep '^netetc=' > /dev/null; then
(
echo "# Networkenvironment: Laptop at customer site (Network-Interface: Ethernet)"
echo "export PROFILE=32"
...
echo "export RLPR_PRINTHOST=printer-etc"
echo "export PRINTER=pr1"
) > $NETENV
Output ist written to a world readable file. Scripts which shall use the assignments simply have to do something like
. /tmp/netenv
For further details you may refer to the included netenv.
As you can see from the code, I do assign not only network stuff, but also a Variable PROFILE as well as printing stuff. This makes it possible, to have e.g. ONE .fvwm95rc.
I would like to show you how to do that when I come back from my vacation.
So far !
Kind regards
Gerd


![]() Welcome to the August WM!
Welcome to the August WM!
![]() 2 PC LAN: Adventures in Home Networking!
2 PC LAN: Adventures in Home Networking!
![]() XEmacs Xtras!
XEmacs Xtras!
![]() Closing Up Shop...
Closing Up Shop...

Howdy! How y'all doing?
Thanks for droppin' in! The big news this month is that I finally got that old PC that bought a couple months ago up and running AND was able to get Ethernet set up between them. I've written about my experiences with TCP/IP, Ethernet setup, and Samba here in the hopes that they might either encourage or guide others in a similar endeavor. This is a whole lot of fun!
I've also been learning a bit about the venerable emacs editor. Actually, I've been learning on its worthy progeny, XEmacs 19.15. Along the way I've discovered that there's a wealth of elisp code out there to customize emacs in all sorts of ways. I've included some code snippets that I've recently culled from the comp.emacs and comp.emacs.xemacs groups.
Finally, in the "Closing Up Shop" section I've included some of the more useful UNIX-type resources that have been ported to the Windows NT/95 environment. I've come to the conclusion that there is no such thing as the "perfect OS", because there is always some feature, utility, or application that it lacks (sorry, even 'ol Linux can't do everything that I'd like it to do!). I've been having to use Windows NT 4.0 at work and have been sorely missing the tools that I've grown accustomed to under Linux. After a bit of 'Net searching I've put together a small collection of UNIX utilities and programs that have been ported to the Windows environment.
Anyway, my sincerest thanks and kudos to Marjorie and Amy at SSC who continue to do a great job of getting the Linux Gazette out each month. This is a lot of work and they are doing a fantastic job!
Hope y'all enjoy!
John
 2 PC LAN: Adventures in Home Networking!
2 PC LAN: Adventures in Home Networking!ABSTRACT
This is a brief recounting of my experiences setting up a small, 2 PC home LAN. The purpose was to to connect a computer running Linux kernel version 2.0.30 with another running Windows 95. Networking was accomplished via TCP/IP over Ethernet. Basic TCP/IP services (ping, telnet, SMTP) were setup. In addition, file, printer, and CD-ROM sharing was achieved using Samba v. 1.9.16p11.
This is the story of an adventure...
"A Horse And His Boy", by C.S. Lewis
CAVEAT: What follows is an account of my own experiences with setting up a small home LAN. I started out knowing a bit of networking theory, but had little practical experience with networking stuff. Along the way, I learned a bit and discovered a few things by trial and error. What I hope to do is encourage y'all to give this a try. It's definitely not as hard as it looks and it is SERIOUSLY COOL!
BUT...
This is NOT a HOWTO. There are numerous well written and informative sources of definitive information on setting up TCP/IP and Ethernet under Linux and Windows 95. The point of this is to share my own experiences. If you find something here that's helpful, that's great. Keep in mind, though, that you're on your own. Like all things with Linux, it's your responsibility to make sure you know what you're doing BEFORE you go messing with things. I've tried to ensure that the information here is as correct as possible, but I can't vouch for everything. Before you do anything to your system, make sure you know what you're doing! Like the old saying goes...
If it breaks, you get to keep both pieces...
Also, this is NOT intended for anyone who is setting up networking in a public or semi-public setting. What is described below is a small home setup: both boxes set on my desk in the office. I'm the only one that has physical access to them with the exception of my wife who does not use Linux at all and who uses Win95 only for email and a bit of word processing. Networking opens up potentially hazardous portals of entry into your system. I'll point out the few places where I've tried to include minor security measures. If you're setting up networking in a public or semi-public setting then this is definitely not what you need to be reading. There are plenty of good books on networking and security and you'd do well to peruse them if you're not completely sure of what you're doing.
The wise will heed this warning...
Anyway, now that I've got that off my chest... :-)
One of the things that I've been wanting to do for some time now is learn a bit about networking. I'd taken a class in networking last Fall and had gotten quite a bit of theory, but precious little "hands on" experience. When I finally bought an old "as-is" PC a while ago I started entertaining hopes that I could somehow set up a small 2 PC LAN. The dream was born...
The reality of the situation, however, soon became quite evident. After a frustrating couple days of swapping out one board after another to isolate and replace the defective ones, I finally managed to get the 'ol PC to boot and installed a copy of WFW 3.11 on it. The old ISA I/O board was a serious dog and the ancient WD video card with 512K didn't help the situation any. But I was glad to see that it worked at least. I finally got tired of watching window redraws and, after finishing up school and starting work, did a major overhaul. My wife very kindly OK'd the investment after numerous assurances that the upgrade would be "her box" and that I'd make sure that it booted to Windows and that there'd be handy icons for the word processor and email stuff... my wife is a sweetheart! :-)
Anyway, the old box got transformed (thanks to a new MB, HD, EDO RAM, and a few other goodies) into a decent performer. When I bought it there was an Artisoft AE-2 NIC in it which I hoped was still working. When my brother-in-law gave me a WD 8003 NIC that he had lying around, I knew that I was on the verge of an adventure. After picking up the thin coax cable, T's, and terminators at Javanco's here in town, I was all set. The adventure was on...!
One of the first things I had to do was install the NIC cards, which turned out to be more of a chore than I had first anticipated. The cards, as it turned out, both worked fine. What was missing was documentation on all those funny little plastic jumpers that I'd need to set the IRQ and base I/O and such. In a stroke of good fortune I happened across one of those sites that belongs in EVERYONE's bookmark file:
Deja News <http://www.dejanews.com>
Deja News, for those who've not come across this place, provides a search engine for a database of Usenet postings. It's a fantastic source of information; granted, the signal to noise ration dips a bit now and then, but with some judicious searching you can find answers to all kinds of interesting problems. After searching for "Artisoft AE-2" and "WD 8003" I found myself in possession of several postings with complete descriptions of jumper settings that previous net pioneers had culled off of manufacturer's FTP sites and Web pages.
I was happy.
I initially set the cards up under Win95 since it was easy to find an unused IRQ and base IO offset. Once IRQ and IO conflicts had been settled for both boxes I decided to try Win95 -> Win95 peer-to-peer networking. This actually turned out to be the easiest part of the setup, owing in no small part to the fact that my "programmer/networking guru" brother-in-law came for the weekend. We managed to have one box talking to the other in no time.
I won't go into great detail as to how we did this: there are numerous excellent (and plenty of not-so-excellent...) references on setting up Win95 boxes. In brief, however, this is what we did:
If you right click on "Network Neighborhood" -> "Properties", a dialog box appears that should look something like this. Click on the Add -> Protocol -> Microsoft buttons to select TCP/IP. You'll likely need the setup disks or CDROM to install the drivers.
Since there were just two boxes on the network all I set up was the IP address and netmask; all other default settings appeared to be correct. Since this wasn't a dial up connection I didn't define a DNS.
I found out the hard way that if you want to set up a workgroup to shared resources that everyone in the workgroup has to use the same workgroup name...
Duh... :-)
Anyway, I defined workgroup and hostnames after making sure that I had OK'd the "File and Print Sharing..." checkboxes from the main Network configuration dialog box. After doing this, I set up each share by right-clicking on the item (drive C, drive D, the CD-ROM, the printer, and so forth...), selecting the "Sharing..." menu item, and then configured share properties and passwords. Also, I selected the "Share Level Access Control" from the "Access Control" tab item.
This one would have completely stumped me had it not been for Bill, my brother-in-law. After we got all through with basic setup he had me set up a hosts file in C:\Win95 (being the non-conformist that I am this is where I put all the Windows stuff). Basically, this is just a file called "hosts" and is similar to the stock /etc/hosts file under Linux. At the moment, mine looks like:
127.0.0.1 localhost
192.168.1.1 Johnsbox
192.168.1.2 Faithsbox
192.168.1.3 Caduceus
At this point, I rebooted both boxes and was able to login and browse shares from either box. I doubt that this is the optimal setup; however, since everything seemed to work and I was able to browse through directories and share the printer, floppy drive, and CD-ROM, I figured I'd leave well enough alone. All in all, I was pretty pleased with this...
Seriously cool... :-)
So, at this point I knew that the NIC's and all the hardware were working and that I should be able to do something similar between Linux -> Win95. The real adventure was just beginning so it was...
Setting up networking support under Linux was just a bit more work than under Win95 and while it wasn't excessively difficult I'll admit that I got bit more than once by a couple of gotcha's!. I'll try to mention these as I go. I also found a fair amount of helpful documentation along the way which I'll also try to give pointers to. In brief, I took the following steps to get networking up and going:
One thing that I did that I'd encourage y'all to do: take lots of notes. There are all kinds of details that you need to attend to along the way and its easy to forget what you've done and what you haven't done. Also, things occasionally break along the way, it's nice to be able to "back out" of recent changes. Anyway, the first thing to do was...
Building a new kernel with the needed networking support was fairly straightforward, although there was one gotcha that I'll mention. The kernel options that I compiled in included Networking support, TCP/IP networking, Network device support, Ethernet support, and support for the Artisoft NIC. I also decided to compile as many of these options as modules as I could and use the kerneld to automatically load and unload them as needed. I also anticipated setting up Samba to fully realize Linux <-> Win95 networking, so I compiled these options in as well.
In summary, the kernel options I included were:
Enable loadable module support (CONFIG_MODULES) [Y/n/?] Y Kernel daemon support (e.g. autoload of modules) (CONFIG_KERNELD) [Y/n/?] Y Networking support (CONFIG_NET) [Y/n/?] Y TCP/IP networking (CONFIG_INET) [Y/n/?] Y Network device support (CONFIG_NETDEVICES) [Y/n/?] Y Ethernet (10 or 100Mbit) (CONFIG_NET_ETHERNET) [Y/n/?] Y Other ISA cards (CONFIG_NET_ISA) [Y/n/?] Y NE2000/NE1000 support (CONFIG_NE2000) [M/n/y/?] M SMB filesystem support (to mount WfW shares etc..) (CONFIG_SMB_FS) [M/n/y/?] Y SMB Win95 bug work-around (CONFIG_SMB_WIN95) [Y/n/?] Y
After I did this, I updated /etc/lilo.conf, using an "append" line to pass it the base IO address and IRQ number for the network card. The global section of /etc/lilo.conf now looked like:
# START LILO GLOBAL SECTION boot = /dev/fd0 delay = 300 vga = normal append = "ether=10,0x300,eth0" ...An important README file that you'll want to have a look at is in the Documentation directory of the linux source (which is normally under /usr/src/linux/Documentation) in the networking subdirectory. It's the net-modules.txt file which describes how to use networking device driver modules. Specifically, it strongly recommends passing the network card base address and IRQ instead of auto-probing. Here's a short snippet from the file:
In many cases it is highly preferred that insmod:ing is done ONLY with defining an explicit address for the card, AND BY NOT USING AUTO-PROBING! Now most cards have some explicitly defined base address, they are compiled with (to avoid auto-probing, among other things). If that compiled value does not match your actual configuration, do use "io=0xXXX" -parameter for the insmod, and give there a value matching your environment. If you are adventurous, you can ask the driver to autoprobe by using "io=0" parameter, however it is potentially dangerous thing to do in a live system. (If you don't know where the card is located, you can try autoprobing, and after possible crash recovery, insmod with proper IO-address..)The file had these additional comments about "NE2000" clone cards, like the one that I was using:
8390 based Network Modules (Paul Gortmaker, Nov 12, 1995)
--------------------------
(Includes: smc-ultra, ne, wd, 3c503, hp, hp-plus, e2100 and ac3200)
The 8390 series of network drivers now support multiple card systems
without reloading the same module multiple times (memory efficient!) This
is done by specifying multiple comma separated values, such as:
insmod 3c503.o io=0x280,0x300,0x330,0x350 xcvr=0,1,0,1
The above would have the one module controlling four 3c503 cards, with
card 2 and 4 using external transceivers. The "insmod" manual
describes the usage of comma separated value lists.
It is *STRONGLY RECOMMENDED* that you supply "io=" instead
of autoprobing. If an "io=" argument is not supplied, then
the ISA drivers will complain about autoprobing being not recommended,
and begrudgingly autoprobe for a *SINGLE CARD ONLY* -- if you want to
use multiple cards you *have* to supply an "io=0xNNN,0xQQQ,..."
argument.
The ne module is an exception to the above. A NE2000 is essentially an
8390 chip, some bus glue and some RAM. Because of this, the ne probe is
more invasive than the rest, and so at boot we make sure the ne probe is
done last of all the 8390 cards (so that it won't trip over other 8390
based cards) With modules we can't ensure that all other non-ne 8390
cards have already been found. Because of this, the ne module REQUIRES
an "io=0xNNN" argument passed in via insmod. It will refuse
to autoprobe.
It is also worth noting that auto-IRQ probably isn't as reliable during
the flurry of interrupt activity on a running machine. Cards such as the
ne2000 that can't get the IRQ setting from an EEPROM or configuration
register are probably best supplied with an "irq=M" argument
as well.
[snip!...]
If you're planning on using modular device drivers I'd recommend having a look at this file as it contains additional helpful information.
The gotcha that I encountered occurred after successfully compiling and installing the new kernel. After I rebooted, there was no message indicating that it had found the network card. As I'm sure most of you know, you can review kernel boot messages using something like:
# dmesg | less
I went back and recompiled and installed yet another kernel, this time with everything compiled into the kernel and NOT as modules; this time, I got the following message:
loading device 'eth0'... ne.c:v1.10 9/23/94 Donald Becker ([email protected]) NE*000 ethercard probe at 0x300: 00 00 6e 30 91 cf eth0: NE2000 found at 0x300, using IRQ 10.
I suspect that many of you have already guessed what I did wrong: I compiled the network device driver as a module but NEVER LOADED THE MODULE!
Duh!
The Slackware distribution includes an rc.modules file with the set of rc files. Among other things, this allows you to specify modules to load at boot up using modprobe. After uncommenting the line for the ne.o driver and specifying the base IO and IRQ values, it loaded without a hitch. Those of you using a Red Hat, or Red Hat derived system, will probably find a similar file under the /etc subdirectory. The invocation that I'm using is:
# jmf -- this is for the Artisoft NE-2 which is jumpered to io=0x300, irq=10 /sbin/modprobe ne io=0x300,irq=10
Anyway, that was a pretty minor gotcha, but I did manage to lose a bit of time messing around with repetitive kernel recompiles and such. Let me mention here that there are a couple helpful HOWTO's that you might be interested in looking over:
The Ethernet-HOWTO contains a LOT of details with respect to setting up Ethernet support under Linux. Personally, I wished that the author had taken more of a step-by-step approach to doing this; still there's a good deal of very useful information here. The Kernel-HOWTO is a good reference to use if you're new to Linux or still don't feel comfortable yet with the notion of compiling and installing a new kernel. This is actually a pretty painless proposition now and with the advent of both an ncurses- (actually "dialog-based") and a tk-based configuration utility, kernel customization and compilation is definitely getting easier.
Once the kernel correctly recognized and initialize the network device, the next step was updating the necessary networking configuration files. There's an absolutely fantastic HOWTO file that goes through this process in an orderly and well-documented manner:
The NET-3 HOWTO
This is a must read document as it describes each of the files needed for networking configuration, gives working examples, and touches on various issues such as security. It is, however, as the author points out, not a networking security oriented document. If security is an issue then you'll probably want to read one of the several excellent reference works available through publishers such as O'Reilly & Assoc..
Since all of you can read, I'll not insult your intelligence by rehashing what is amply covered in this HOWTO. I would like to make a couple comments about certain files. To begin with, I'm using a Slackware 3.2 distribution, so the files on other distributions may be in different locations (or use a different filename) than the ones mentioned here. These are the files that I edited:
/etc/rc.d/rc.inet1 /etc/rc.d/rc.inet2 /etc/hosts /etc/hosts.allow /etc/hosts.deny /etc/resolv.conf
Slackware uses rc.inet1 to configure the network interfaces and update the kernel routing tables. I chose to assign the boxes IP addresses from the 192.168.xxx.xxx block. The NET-3 HOWTO covers the assignment of IP addresses in a private network (such as a home LAN like I was setting up). Basically, there are three blocks of addresses that are reserved for private networks (a Class A, Class B, and Class C block). If you're interested, RFC-1597 describes this in detail.
And speaking of which, I should mention another very useful WWW resource that you should add to your bookmark file if you haven't already. Nexor Corporation has a web page that allows easy look up and retrieval of RFC documents. Their URL for this service is:
http://www.nexor.com/public/rfc/index/rfc.html
For the curious, my rc.inet1 now looks like:
#! /bin/sh
#
# rc.inet1 This shell script boots up the base INET system.
#
# Version: @(#)/etc/rc.d/rc.inet1 1.01 05/27/93
HOSTNAME=$(cat /etc/HOSTNAME)
# Attach the loopback device.
/sbin/ifconfig lo 127.0.0.1
/sbin/route add -net 127.0.0.0 netmask 255.0.0.0 lo
# IF YOU HAVE AN ETHERNET CONNECTION, use these lines below to configure the
# eth0 interface. If you're only using loopback or SLIP, don't include the
# rest of the lines in this file.
# IP addresses for TCP/IP Ethernet connection
IPADDR="192.168.1.3"
NETMASK="255.255.255.0"
NETWORK="192.168.1.0"
BROADCAST="192.168.1.255"
GATEWAY="
# Uncomment the line below to configure your Ethernet card.
/sbin/ifconfig eth0 ${IPADDR} broadcast ${BROADCAST} netmask ${NETMASK}
[...]
# Set up IP routing table.
/sbin/route add -net ${NETWORK} netmask ${NETMASK} eth0
if [ -n $GATEWAY ]; then
/sbin/route add default gw ${GATEWAY} netmask 0.0.0.0 metric 1
fi
# End of rc.inet1
In addition, my /etc/hosts, /etc/hosts.allow, and /etc/hosts.deny files look like:
# # hosts This file describes a number of hostname-to-address # mappings for the TCP/IP subsystem. It is mostly # used at boot time, when no name servers are running. # On small systems, this file can be used instead of a # "named" name server. Just add the names, addresses # and any aliases to this file... # # By the way, Arnt Gulbrandsen <[email protected]> says that 127.0.0.1 # should NEVER be named with the name of the machine. It causes problems # for some (stupid) programs, irc and reputedly talk. :^) # # For loopbacking. 127.0.0.1 localhost 192.168.1.1 Johnsbox.vanderbilt.edu Johnsbox 192.168.1.2 Faithsbox.vanderbilt.edu Faithsbox 192.168.1.3 Caduceus.vanderbilt.edu Caduceus # END /etc/hosts
# # hosts.allow This file describes the names of the hosts which are # allowed to use the local INET services, as decided by # the '/usr/sbin/tcpd' server. # # Version: @(#)/etc/hosts.allow 1.00 05/28/93 # # Author: Fred N. van Kempen, <[email protected]> # # # allow all services ONLY to the local boxes ALL: 127.0.0.1 ALL: 192.168.1.1 ALL: 192.168.1.2 ALL: 192.168.1.3 # End of hosts.allow.
# # hosts.deny This file describes the names of the hosts which are # *not* allowed to use the local INET services, as decided # by the '/usr/sbin/tcpd' server. # # Version: @(#)/etc/hosts.deny 1.00 05/28/93 # # Author: Fred N. van Kempen, <[email protected]> # # # deny all services to everyone unless specified in /etc/hosts.allow ALL: ALL # End of hosts.deny.
Finally, I updated /etc/resolv.conf to point to the DNS servers at Vanderbilt University and, secondarily, at MTSU:
domain vanderbilt.edu nameserver 129.59.1.10 nameserver 161.45.1.2
At this point, I rebooted both boxes and kept a watch out for boot up error messages...
So far, so good...
The seriously cool moment occurred when I was able to both ping and then telnet from my wife's Win95 box to Linux. Here's the screen shots of this glorious occasion ;-)
Pinging from Win95->Linux
Telnetting from Win95->Linux
You've probably noticed that I wasn't using the telnet client that comes with Win95. I've found several freeware sites recently and one of them had the venerable ewan 1.05 telnet client that I'd been using for the past couple years. This provides at least ANSI colors as you can see from screen dump of the XEmacs session I had running.
These alone were worth a bit of celebrating! Running console-based programs via telnet was surprisingly fast: there was little or no performance difference between the telnet session and running the programs natively under Linux. This was seriously cool!
I also found that I could ping from Linux->Win95 and that I could ping and telnet from Win95->Linux using both IP address and hostname!
I was a happy man :-)
Still, there was one final challenge left...
This is still, as the academe's would say, "a work in progress..."
(which is to say: "all the bugs ain't worked out yet...")
Still, I've got file and CD-ROM sharing working and am closing in on getting printer support working as well! At the moment, I can browse my Linux file system from under Win95, view and edit files, use the CD-ROM (and the floppy drive) as though they were local. This has been a serious pump! I've also discovered that I can do some other nifty things using TCP/IP, such as email, which I'll mention later. All in all, this has been huge! So, here are how things got started...
The first thing I did, and if you're interested in setting up Samba what I'd suggest that you do first too, to head right on out to:
Official Samba Home Page
Samba was created by Andrew Tridgell, who has not only written a fantastic program, but has provided a wealth of information on Samba at the home page. This includes:
This is definitely Stop Number One.
Stop Number Two was the SMB-HOWTO which provided a good deal of useful information in compiling, installing, and configuring Samba. After messing around with this for the past couple weeks and starting to read the comp.protocols.smb newsgroup, I'm convinced that the biggest challenge to getting Samba up and doing what you want is getting the smb.conf configuration file correct. Hence, you'll probably want to spend a bit of time with the documentation.
The good news is, however, that getting basic file sharing up and working is pretty straightforward.
Anyway, the first thing I did was to get the current source, which as of July, 1997 was 1.9.16p11. Compiling and installing Samba was fairly easy. The first thing to do was edit the Makefile under samba-1.9.16p11/source and change the defaults to match my preferences. Specifically, the values I used were:
BASEDIR = /usr/local/samba BINDIR = $(BASEDIR)/bin SBINDIR = $(BASEDIR)/bin LIBDIR = $(BASEDIR)/lib VARDIR = $(BASEDIR)/var FLAGS1 = -O -DSYSLOG SMBLOGFILE = $(VARDIR)/log.smb NMBLOGFILE = $(VARDIR)/log.nmb CONFIGFILE = $(LIBDIR)/smb.conf LMHOSTSFILE = $(LIBDIR)/lmhosts LOCKDIR = $(VARDIR)/locks WORKGROUP = FISK GUESTACCOUNT = guest FLAGSM = -DLINUX -DSHADOW_PWD LIBSM = -lshadow
Basically, I used the Samba default filesystem structure, which puts all the program and configuration files under /usr/local/samba. I added the -DSYSLOG flag since I'm basically nosy about what's going on and like to see log files to help diagnose problems. The log file and lock file locations, once again, are defaults. I made the default workgroup FISK which is what I used under Win95; I also made sure that I had a guest account and group to which login was barred. The reason for this is giving in the Makefile:
# set this to the name of the default account, which is the one # to use when no username or password is specified. This can be overridden # in the runtime configuration file (see smb.conf(5)) # NOTE: The account "nobody" may not be a good one as # on many unixes it may not be able to print. Thus you # might have to create a separate guest account that can print. GUESTACCOUNT = guestAnd finally, I compiled Samba with shadow password support. You'll find several configuration options for Linux with and without shadow passwords, quotas, and so forth so just pick whichever one is suitable and uncomment the appropriate lines. Hereafter, the compile and install were as simple as:
# make
# make install
At this point I should have mentioned that I was actually doing all this from two VT's (after logging in as root). From the first VT I was editing the Makefile and managing the compilation; from the other VT I had changed to the samba-1.9.16pll/docs/ subdirectory and was following the INSTALL.txt file directions. At the top of the file is the encouraging pronouncement HOW TO INSTALL AND TEST SAMBA and, in fact, the directions do a pretty good job of doing just that.
At this point, I'd done the first couple steps:
If you're wondering what this "all important step" might be, here's Andrew in his own words:
At this stage you must fetch yourself a coffee or other drink you find stimulating. Getting the rest of the install right can sometimes be tricky, so you will probably need it.
So, after grabbing a coke and a bag 'o nachos, I was ready to plunge ahead. I'd suggest you do the same...
The next step is to create the smb.conf file. Now, the good news is that it appears that it isn't too hard to get something working -- you should definitely see fruits of your labors! The bad news is that getting everything exactly right is quite a bit more challenging.
In the samba-1.9.16p11/examples/simple directory there's a well-commented sample smb.conf file that I used as a template when setting this up. As the documentation suggests, you'll probably want to be armed with this or an equivalent template and the smb.conf manual page, which goes into great detail with regard to each of the configuration options. Fortunately, the manual page is pretty well written although there is admittedly quite a bit of it... :-)
After making a few guesses about what I'd like to try I went back to the INSTALL.txt file and continued with the installation instructions. The next thing it suggests doing is testing the configuration file with the included testparm program. This is really handy as it will let you spot errors in the syntax of the configuration file. Here's a copy of my current smb.conf file:
; Configuration file for smbd. [global] workgroup = FISK printing = bsd printcap name = /etc/printcap load printers = yes guest account = guest domain master = yes log file = /usr/local/samba/log.%m [homes] comment = Home Directories browseable = yes read only = no writable = yes create mode = 0744 [printers] comment = All Printers browseable = no printable = yes public = no writable = no create mode = 0755 path = /var/spool/public print command = echo Printing %s >> /tmp/smb_print.log; lpr -P %p %s [guest] comment = Toplevel Directory browseable = yes printable = no public = yes writable = no readonly = yes only guest = yes path = / [cdrom] comment = Mitsumi CD-ROM Drive browseable = yes writeable = no readonly = yes printable = no public = yes only guest = no path = /cdrom ; END smb.conf
When I run the testparm program on this file I get:
Load smb config files from /usr/local/samba/lib/smb.conf Processing section "homes]" Processing section "printers]" Processing section "guest]" Processing section "cdrom]" Loaded services file OK. Press enter to see a dump of your service definitions
By hitting ENTER you get a LOT of detailed information about the current values of the configuration. Since this seemed to be OK I went ahead and started the smbd and nmbd daemons from the command line using:
# /usr/local/samba/bin/smbd -D -d1 -s/usr/local/samba/lib/smb.conf
# /usr/local/samba/bin/nmbd -D -d1 -s/usr/local/samba/lib/smb.conf \
-l/usr/local/samba/log
The -D option specifies that smbd and nmbd run as daemons; -d1 sets the debug level; and -s and -l set the locations of the smb.conf and logging files respectively. After having a peek at ps -x to make sure that they had started OK, I ran the next test, which involves using the smbclient program to list the shares on the local server. Doing this I get:
# smbclient -L Caduceus
Added interface ip=192.168.1.3 bcast=192.168.1.255 nmask=255.255.255.0
Server time is Mon Jul 28 20:36:15 1997
Timezone is UTC-5.0
Domain=[FISK] OS=[Unix] Server=[Samba 1.9.16p11]
Server=[caduceus] User=[fiskjm] Workgroup=[FISK] Domain=[FISK]
Sharename Type Comment
--------- ---- -------
ascii Printer ljet2p-letter-ascii-mono
cdrom Disk Mitsumi CD-ROM Drive
fiskjm Disk Home Directories
guest Disk Toplevel Directory
homes Disk Home Directories
IPC$ IPC IPC Service (Samba 1.9.16p11)
lp2 Printer ljet2p-letter-auto-mono
raw Printer ljet2p-letter-raw
This machine has a browse list:
Server Comment
--------- -------
CADUCEUS Samba 1.9.16p11
This machine has a workgroup list:
Workgroup Master
--------- -------
FISK CADUCEUS
Again, there's a good deal of information (just keep telling yourself that this is the "Information Age" and there's supposed to be a lot of this around... :-). Anyway, I didn't spot any errors here and so tried to connect to the local server, again using smbclient:
fiskjm@Caduceus [ttyp1] [docs] $ smbclient '\\Caduceus\fiskjm' Added interface ip=192.168.1.3 bcast=192.168.1.255 nmask=255.255.255.0 Server time is Mon Jul 28 20:39:49 1997 Timezone is UTC-5.0 Password: Domain=[FISK] OS=[Unix] Server=[Samba 1.9.16p11] smb: \>
Excellent! So far, so good...
The last thing to do was head back to the Win95 box, and this is where the fun began...
Let me stress once again that all of the above steps are outlined in the INSTALL.txt file which really does a nice job of leading the uninitiated, like myself, through this potentially bewildering process. At this point, then, I was ready to try connecting from Win95.
The first thing I noticed was that when I clicked on the "Network Neighborhood" the Linux box did not immediately show up! So I did the next logical thing (logical, at least in my own mind, I guess...) I pinged Caduceus (my Linux box) from Win95 and, sure enough, it answered back. I then telnetted to it from Win95 and again, had no trouble! Now, when I clicked on "Network Neighborhood" Caduceus showed up!
I honestly haven't a good explanation of why this happens but I've found it to be the case from time to time: to get the SMB shares to "show up" I need to ping or telnet to the Linux box before trying to browse. Those of you who have more experience or insight might be able to offer an explanation...
Anyway, I was thrilled to see 'ol Caduceus show up. And just so that you don't think I was making this up, here's a screen dump of Network Neighborhood showing Caduceus. The next gotcha came when I clicked on the Caduceus icon: I got an error to the effect of "network not found..." which had me completely stymied.
Fortunately, in the samba-1.9.16p11/docs directory there's another helpful file called DIAGNOSE.txtwhich, as the name implies, is a useful checklist of things to run down when trying to pin-point the cause of a problem. As it turned out, the solution to the "network not found" error was adding the IP address of Caduceus to the WINS server configuration box in the Network options dialog box. Doing this and rebooting the Win95 box fixed the problem completely!
At this point, I was golden! I could now:
This was a serious pump! ;-)
I found that I could mount a CD under Linux and then browse the contents of that CD via Samba! I found that I could even install Win95 software via a CD mounted under Linux.
I was dancin'!! This rocks!
In addition to the above I also found that I could browse my entire Linux hierarchy as "guest". What was even MORE freaky was that I could mount my local Win95 partitions under Linux (to /dosC, for example) and then browse those files via Samba from the other networked Win95 box. This was getting better and better all the time... ;-)
I'm sure, having skimmed through most of the docs and reading a bit of the newsgroup digests, that there are all sorts of way too cool things that can be done with Samba...
This'll let you push the envelope, my friend...
...riding the Ragged Edge of Destruction and Howling in the Wind!
This is what makes Linux just rock!
Anyway, as I said before, this is still a work in progress. The one thing that I'm still working on is printing, both from Linux->Win95 and vice versa. I'm getting incrementally closer, but haven't quite gotten all the pieces together yet. Still, after a Dejanews search I'm armed with a host of old postings on the subject and have a plan of attack in figuring this out. One thing about Linux...
It hones your problem solving skills :-)
The next step in the Odyssey, after whipping printing into shape, is to set up modem sharing between the Linux box and Win95. Currently, I'm doing all my dialup networking (or realistically, the vast majority of it) under Linux. What I'm planning to have a go at next is IP masquerading that would allow the Win95 box to access the 'Net via the dialup line under Linux. I've already discovered that, using Eudora Lite for Windows 95/NT, an excellent, mature, and freely available SMTP/POP email client from the folks at Qualcomm Corporation, I can use the in.pop3d daemon to allow Eudora to pick up mail from the Linux box via POP3 and then send mail out using sendmail running under Linux! This is another Huge Blow For Freedom since it allows me to pick up mail under Linux, skim through the mail for stuff that's specifically mine, and then POP the rest to the Win95 box where my wife can read/reply to it. Outgoing mail is forwarded to sendmail under Linux where it's queued up and sent out the next time a connection is made.
It just gives me Willies!
So, I'm one Seriously Happy Linux Hombre Kinda Guy! I know that it's quite expensive setting up a single box, let alone two, but if you can find an old beater box somewhere: someone's upgrade "hand-me-down" or something like that, and a couple old NIC cards I'd really recommend this to you. You'll never be the same...
Trust me... :-)
For those of you who've caught the bug, here are a few more resources that I came across in the nascent stages of The Quest. In addition to the HOWTO's and other documents already listed, have a look at:
He covers TCP/IP, Samba, and IP firewall setup to make all of this happen. I'd definitely have a look a this.
The above list is far from comprehensive, although I trust that it at least provides a jumping off site for further exploration. I really can't stress how much fun this networking stuff has been. Being able to share resources between a Linux box and a Windows box has opened up all sorts of possibilities. My wife is actually talking about "her box" which is a major step forward in computer acceptance around the Fisk household after years of..., er... detente.
I'd also like to point out once again that this is a NETWORK NEWBIE's article: I'm way down low on that 'ol learning curve and have quite a ways to go before I can claim basic proficiency. Be warned once again that at least part of what I've mentioned here may well be wrong (the problem, of course, is that I don't know which part). Please don't hesitate to drop me a note and provide corrections or modifications.
Anyway, here's wishing y'all a VERY HAPPY LINUX'ing!
Best Wishes,
John M. Fisk
Nashville, TN
28 July, 1997
XEmacs Xtras!Since the end of the Spring semester, which can be loosely interpreted to mean, "since I had a bit more time...", I've been slowly learning my way around XEmacs. I've still not formed a solid opinion on it yet, but it's definitely growing on me. I love the speed of vi[m] and I still use this for all the day to day editing and such that needs to be done. But I've slowly grow quite attached to XEmacs and all the nifty things that this great editor is capable of doing.
And for those of you who are unfamiliar with it, XEmacs is...
Well, in their own words (from the XEmacs FAQ):
What is XEmacs? =============== An alternative to GNU Emacs, originally based on an early alpha version of FSF's version 19, and has diverged quite a bit since then. XEmacs was known as Lucid Emacs through version 19.10. Almost all features of GNU Emacs are supported in XEmacs The maintainers of XEmacs actively track changes to GNU Emacs while also working to add new features.
I guess, to my own conceits, XEmacs provides all of the power and sophistication of its worthy progenitor, GNU Emacs, with a goodly assortment of the amenities of a GUI. It seems to strike a nice balance between the "pretty, mouse-driven UI" and the speed of the keyboard. All in all, I'm having a great time messing around with this. Which reminds me, Dan Nicolaescu sent a very nice note pointing out something that I'd clearly missed:
From [email protected] Tue Jul 22 22:09:23 1997
Date: Sun, 29 Jun 1997 10:16:13 -0700
From: Dan Nicolaescu <[email protected]>
To: [email protected]
Subject: article in Linux GazetteHi!
I have one comment about the screen captures of Emacs and XEmacs in your article in Linux Gazette at ../issue18/wkndmech.html
To truly illustrate both emacsen syntax coloring capabilities you would better take a snapshot after you put in your .emacs (setq font-lock-maximum-decoration t) and restart [X]Emacs.
Regards,
Dan
Thanks Dan!
As the old academic saw goes, "this is left as an exercise for the reader". I appreciated his pointing this out.
This segues right into another point that I wanted to bring up: there is a HUGE amount of interesting and fun elisp code floating around out there that does all sorts of cool and groovy things.
Like what, you ask...?
Well, in issue 11 of the Linux Gazette, the prolific Larry Ayers had an article on adding a "kill ring menu" to the menu bar which allows you to select from a number of previously killed sections of text being held in the kill ring. I've added this to my ~/.emacs file and it works like a charm! Kudos to Larry!
Well guess what? If you hang around the comp.emacs, comp.emacs.xemacs, or gnu.emacs.sources newsgroups you'll find that code snippets like this are passed around all the time. To help entice you, here are two postings that I ran across a little while ago. The first, from David Hughes tells how to set up func-menu which provides a menu of the functions defined in the current buffer. This is similar to using etags or ctags for those of you who are familiar with these programs, but adds a clever bit of GUI:
From: [email protected] (David Hughes) Subject: Re: Is func-menu what I'm looking for? Newsgroups: comp.emacs.xemacs Sender: [email protected] Lines: 50 Xref: news.vanderbilt.edu comp.emacs.xemacs:16055 > Hi gurus, > > I remember, a while ago, I used to be have a menu that would > give me the name of the functions defined in the current buffer. > The menu would also allow me to point to one particular function. > > I'd like to be able to use that again, but I do not know > which package does it. > Is it func-menu? > If so, where can I find it? I have tried, but I could > not find it. Add the following (or something like it) to your .emacs ;;; func-menu is a package that scans your source file for function ;;; definitions and makes a menubar entry that lets you jump to any ;;; particular function definition by selecting it from the menu. The ;;; following code turns this on for all of the recognized languages. ;;; Scanning the buffer takes some time, but not much. ;;; ;;; Send bug reports, enhancements etc to: ;;; David Hughes <[email protected]> ;;; (cond (running-xemacs (require 'func-menu) (define-key global-map 'f8 'function-menu) (add-hook 'find-file-hooks 'fume-add-menubar-entry) (define-key global-map "C-cl" 'fume-list-functions) (define-key global-map "C-cg" 'fume-prompt-function-goto) ;; The Hyperbole information manager package uses (shift button2) and ;; (shift button3) to provide context-sensitive mouse keys. If you ;; use this next binding, it will conflict with Hyperbole's setup. ;; Choose another mouse key if you use Hyperbole. (define-key global-map '(shift button3) 'mouse-function-menu) ;; For descriptions of the following user-customizable variables, ;; type C-h v <variable> (setq fume-max-items 25 fume-fn-window-position 3 fume-auto-position-popup t fume-display-in-modeline-p t fume-menubar-menu-location "File" fume-buffer-name "Function List*" fume-no-prompt-on-valid-default nil) )) -- David Hughes
The second, by Tom Steger (who actually tips the hat to another fella...), tells how to do something that I really have gotten used to under vi[m], and that is hitting the percent "%" key when the cursor is positioned on top of a brace, bracket, parenthesis, etc. and have it move to the matching element. For those long-winded functions with lots of nesting this is a godsend when trying to untangle a mass of braces and brackets.
Date: Mon, 23 Jun 1997 08:20:35 -0400 From: [email protected] (Tom Steger) Subject: Re: matching parenthesis Newsgroups: comp.emacs.xemacs > Hi, > > Is there a command in xemacs19.15 by which I can go to a matching > parenthesis (like % in vi) ?? > > I do have the parenthesis library working which highlights the > matching parenthesis but if the matching parenthesis is out > of the page how do I get to it without moving the cursor ?? > > Thanks in advance, > Chetan I got the following from [email protected] in response to a similar question. I bound it to ALT %. (defun goto-matching-paren () "Move cursor to matching paren." (interactive) (let* ((oldpos (point)) (blinkpos)) (condition-case () (setq blinkpos (scan-sexps oldpos 1)) (error nil)) (if blinkpos (setq blinkpos (1- blinkpos)) (condition-case () (setq blinkpos (scan-sexps (1+ oldpos) -1)) (error nil))) (setq mismatch (/= (char-after oldpos) (logand (lsh (aref (syntax-table) (char-after blinkpos)) -8) 255))) (if mismatch (progn (setq blinkpos nil) (message "Mismatched parentheses" (if blinkpos (goto-char blinkpos))))) (global-set-key "M-%" 'goto-matching-paren)
I know that trying to cut and paste from HTML isn't always the easiest so if you're interested in trying these things out I've taken the liberty of cat'ing these into a plain ASCII file. You can either save the following link to a file or else display it and then save it as a plain text file:
Anyway, I've had a huge amount of fun playing with this, hope you do too.
Enjoy!
John M. Fisk
Nashville, TN
29 July, 1997
Say, thanks again for stopping in!
Thought I'd finish up with a quick list of UNIX resources for Win95/NT users. When I started work this summer they upgraded the workstation that I'd been using to a Pentium-based system running Windows NT version 4.0. This was the first time that I'd used NT and, although it's quite similar to Windows 95, found that it took a bit of getting used to.
One of the things that I really missed were the editors and file processing tools that I'd been using under Linux at home and at school. I soon discovered that there's quite a wealth of UNIX type tools that have been ported to the Win95/NT environment. I was quite impressed at what is currently available: vi, emacs, perl, tcl/tk, gcc, gs, ksh, bash, and so forth. Not all programs work as well in the Windows environment and often there are missing features. Still, overall I've been pretty pleased at what's out there.
So here's a short listing of some of the resources "out there..."
If you want, you can head right on out to the GNU Emacs for Windows NT/95 FTP site
These guys have provided a high quality, 32 bit, GNU-based development environment with an impressive number of utilities as well as the bash shell. I've been using these tools for the past couple months now and they are truly a godsend. If memory serves me correctly you'll find both development archives as well as an archive with basic file and disk utilities (grep, awk, sed, cat, rm, ls, and so forth). This is a definite bookmark site.
This is under the leadership of David Korn (of the Korn Shell fame...) who describes UWin as "a package [which] provides a mechanism for building and running UNIX applications on Windows NT and Windows 95..."
Comparison shoppers will want to have a look at what's available here as well and make their own decisions.
You'll find a host of tools and utilities including brand new DJGPP binaries from the Pentium Compiler Group! This is another must visit site.
If you "do perl" then this is your site!
Well, I'm running out of time here, but hopefully this will get you going. With a bit of poking around you'll easily find ports of several other excellent programs including:
A Yahoo search will often get you going on the right track. Also, a couple of the pages above have a very nice set of links to help you on your search for Good Tools.
Anyway, thanks again for stopping by! Take care.
Best Wishes,
John M. Fisk
Nashville, TN
29 July, 1997

Got any comments, suggestions, criticisms or ideas?
Feel free to drop me a note at:

 Larry Ayers Gerd BavendiekJim DennisJohn Fisk Guy GeensMichael J. Hammel Håkon Loøvdal Andy Vaught
Larry Ayers Gerd BavendiekJim DennisJohn Fisk Guy GeensMichael J. Hammel Håkon Loøvdal Andy VaughtThanks to all our authors, not just the ones above, but also those who wrote giving us their tips and tricks and making suggestions. Thanks also to our new mirror sites.
 My assistant, Amy Kukuk, did all the work again this month. She's so good to me. Thank you, Amy.
My assistant, Amy Kukuk, did all the work again this month. She's so good to me. Thank you, Amy.
Vacations are fun and wonderful, but mine sure put me behind schedule with my Linux Journal work. My grandchildren are even smarter and more beautiful than I remembered. It was a much needed break, and I expect to get caught up this week. :-)
Linux Journal is expanding to 116 pages and going to perfect binding with the October issue. No wonder I'm working so hard!
 Riley is going off again this Saturday for our annual week-long motorcyle trek with friends. This time I'm staying home. :-( Oh, well, perhaps next year. (Needless to say, our motorcycle is a BMW.)
Riley is going off again this Saturday for our annual week-long motorcyle trek with friends. This time I'm staying home. :-( Oh, well, perhaps next year. (Needless to say, our motorcycle is a BMW.)
Have fun!
Marjorie L. Richardson
Editor, Linux Gazette
Linux Gazette Issue 20, August 1997, http://www.ssc.com/lg/
This page written and maintained by the Editor of Linux Gazette,
 The Mailbag!
The Mailbag!![[Click for screen shot!]](./gx/lyx/overview.jpeg){kind=link}
{kind=link}
![[Do-it-yourself 'bibliography' screen shot]](./gx/lyx/bibliography.jpeg){kind=link}
![[The formula on-screen]](./gx/lyx/eq_spher.jpeg){kind=link}
{kind=link}
![[Stokes on-screen]](./gx/lyx/eq_stokes.jpeg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![[Using section and page references]](./gx/lyx/ref_pageref.jpeg){kind=link}
![[The EPS popup for embedding graphics]](./gx/lyx/eps_popup.jpeg){kind=link}
![[A do-it-yourself full-width figure float, with labeled caption]](./gx/lyx/figure_star.jpeg){kind=link}
![[Nested environments example]](./gx/lyx/nested_env.jpeg){kind=link}
![[A table example, from the Users Guide]](./gx/lyx/table.jpeg){kind=link}
{kind=link}
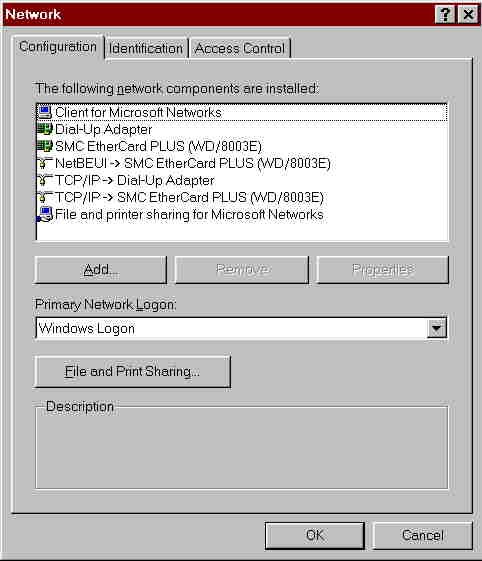{kind=link}
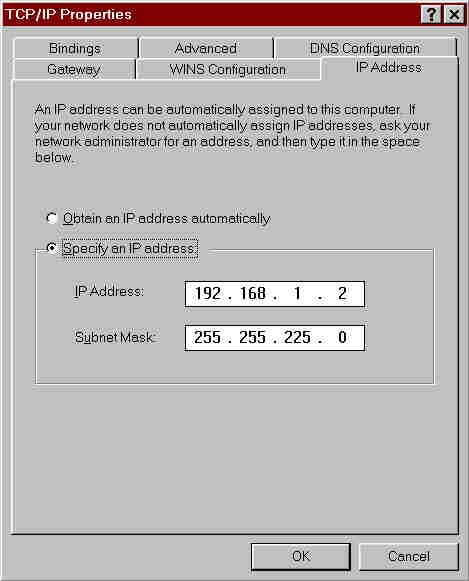{kind=link}
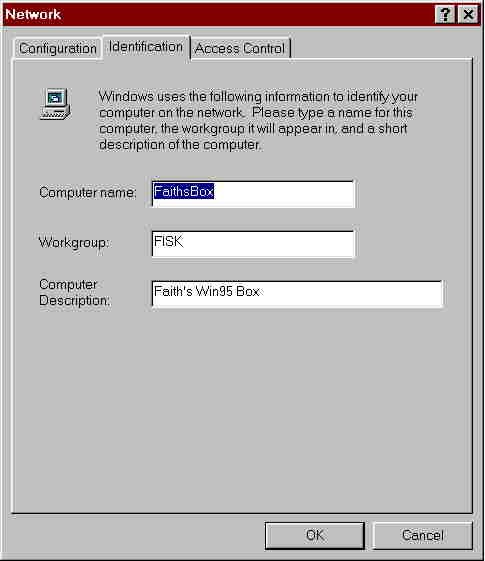{kind=link}
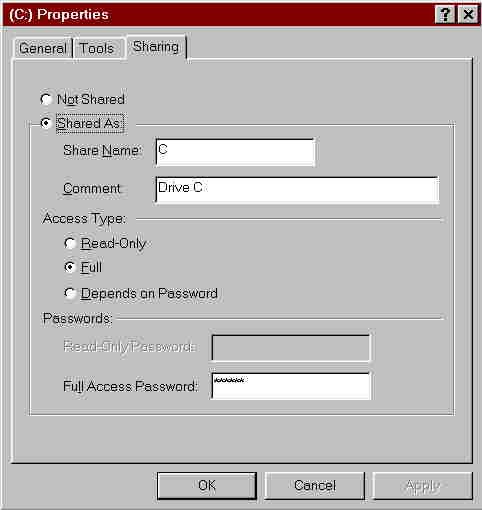{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}