
|
Table of Contents:
|
||||
Editor: Michael Orr
Technical Editor: Heather Stern
Senior Contributing Editor: Jim Dennis
Contributing Editors: Ben Okopnik, Dan Wilder, Don Marti
| TWDT 1 (gzipped text file) TWDT 2 (HTML file) are files containing the entire issue: one in text format, one in HTML. They are provided strictly as a way to save the contents as one file for later printing in the format of your choice; there is no guarantee of working links in the HTML version. |
|||
![[tm]](../gx/tm.gif) , http://www.linuxgazette.com/ , http://www.linuxgazette.com/This page maintained by the Editor of Linux Gazette, Copyright © 1996-2001 Specialized Systems Consultants, Inc. |
|||
 The Mailbag
The MailbagSend tech-support questions, answers and article ideas to The Answer Gang <>. Other mail (including questions or comments about the Gazette itself) should go to <>. All material sent to either of these addresses will be considered for publication in the next issue. Please send answers to the original querent too, so that s/he can get the answer without waiting for the next issue.
Unanswered questions might appear here. Questions with answers--or answers only--appear in The Answer Gang, 2-Cent Tips, or here, depending on their content. There is no guarantee that questions will ever be answered, especially if not related to Linux.
Before asking a question, please check the Linux Gazette FAQ to see if it has been answered there.
 ip_always_defrag missing from kernel 2.4?
ip_always_defrag missing from kernel 2.4?In its place there appear to be three new parameters:
ipfrag_high_thresh - INTEGER
Maximum memory used to reassemble IP fragments. When ipfrag_high_thresh bytes of memory is allocated for this purpose, the fragment handler will toss packets until ipfrag_low_thresh is reached.
ipfrag_low_thresh - INTEGER See ipfrag_high_thresh ipfrag_time - INTEGER Time in seconds to keep an IP fragment in memory.
Any idea what are 'reasonable' settings?
What settings will mimic, as closely as possible, the behavior of ip_always_defrag?
-- James Garrison
'Spanking New' Distribution ships with 'development' compilerHello TAG-Team,
I just installed Mandrake 8.0. I intend to use gcc (the compiler) quite a bit to recompile lots of software. Mandrake 8.0 ships with a development version of gcc (2.96) but I really want to stick with 2.95.x for stability/portability. How can I remove the development-gcc and put an older version in without breaking the system. I know there must be a way to do this via RPM, but it eludes me and I was seriously frightened to rebuild from an unmanaged source tarball.
-Marc Doughty
Printer memory overflowsI just got an older laser printer and it works very well with a HP LJ III printcap setting, except it has only 1 MB of RAM. This works well until I try to print a PDF, then it runs out of printer memory about 7/8 of the way through the page.
Is there some way to tell ghostscript/lpd to go easy on the thing? I was able to print them fine on my inkjet, and it definitely doesn't have 1 MB of memory installed...
Oh yes, the same .PDF prints fine on the Evil(tm) Operating System.
Thanks.
-- Jonathan Markevich
What happened to e2compr?I run Linux 2.2.14 on a laptop with a by now small hard drive. To put some huge files (such as graphics in the middle of editing) on it, I installed the e2compr patch to the kernel. I'd like to upgrade to 2.4, but the patch doesn't seem to be available for 2.4. Anybody know what happened to it?
phma
There's at least one new compressed filesystem in the new kernels, but I'm not sure that the one I'm thinking of is realy ext2 compatible. Still, you might not need that. There's a curious new style of ramdisk available too. Anyone who knows more is welcome to chime in ... -- Heather
Linux fashionGreetings
I'm reading the gazette for a wile now, and never found an answer to my simple question Where can I found Baby's clothes related to Linux? With Linux logo or something. I want my baby to be cool (and to use Linux) .....
thanks
Erez Avraham
It looks like The Emporium (a UK company) sells child size sweatshirts but I don't know what sizes are good for babies. Comments welcome. If you are a commercial entity which has 'em, let us know, and we'll put you in News Bytes. -- Heather
IRC channels for IPChainsOne more quickie: do you know of any IRC channels where I can get some IPChains questions answered? I'm trying to put in a firewall for a client using a script that has worked very well for me for several years (used to be IPMasq, but has been modified for IPChains) but just dies now and for the life of me I can't figure out why.
The only difference in this case that I can see is that the DSL line it sits behind is running Ethernet bridging (PacBell DSL) over an Alcatel modem and the script has been running behind a cable modem (no bridging); but why is that such a "deal-killer"?
Anyway, thanks again!
RAB
Roy Bettle
Tape BackupHi Sir,
Recently,in the pipeline of converting my NT server to a Redhat 7.1 Linux Server with Samba on it. But the problem is I'm using a a HP SureStoreDAT 40 tape Drive. And there is nowhere I can find the driver for this device(including the HP and Redhat website). I really hope that I can realise my dream of setting up 2 Linux server(with UPS and backup tape driver on) at my place. I don't want to scrap the whole project halfway. Does you knows where I can get the above driver or a generic driver well do? Or is there any recommendations on a almost similar tape drive that is well supported with Redhat? If I can't succeed then I 'll have to go to Windows2000 with all those expensive licenses. Thanks
warmest regards,
Desmond Lim
Article ideaYes, Gentle Readers, this is also in TAG this month, but folks looking for article ideas are encouraged to take this and run with it. For that matter, we have a PostgresSQL related article this month (nielsen.html) but it would be fun to have an article comparing PostgresSQL to MySQL. -- Heather
I would love to see an article about making sense of MySQL.Perhaps some basic commands, and how to do something useful with it.
Here are some basic commands. As far as "something useful", what would you consider useful?
I have found a lot of articles either lack basic usage and administration or it it fails to show how to put it all together and have somehing useful come out of it.
The 'mysql' command is your friend. You can practice entering commands with it, run ad-hoc queries, build and modify your tables, and test your ideas before coding them into a program. Let's look at one of the sample tables that come with MySQL in the 'test' database. First we'll see the names of the tables, then look at the structure of the TEAM table, then count how many records it contains, then display a few fields.
$ mysql test Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 1325 to server version: 3.23.35-log Type 'help;' or '\h' for help. Type '\c' to clear the buffer mysql> show tables; +------------------+ | Tables_in_test | +------------------+ | COLORS | | TEAM | +------------------+ 2 rows in set (0.00 sec) mysql> describe TEAM; +------------+---------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +------------+---------------+------+-----+---------+----------------+ | MEMBER_ID | int(11) | | PRI | NULL | auto_increment | | FIRST_NAME | varchar(32) | | | | | | LAST_NAME | varchar(32) | | | | | | REMARK | varchar(64) | | | | | | FAV_COLOR | varchar(32) | | MUL | | | | LAST_DATE | timestamp(14) | YES | MUL | NULL | | | OPEN_DATE | timestamp(14) | YES | MUL | NULL | | +------------+---------------+------+-----+---------+----------------+ 7 rows in set (0.00 sec) mysql> select count(*) from TEAM; +----------+ | count(*) | +----------+ | 4 | +----------+ 1 row in set (0.00 sec) mysql> select MEMBER_ID, REMARK, LAST_DATE from TEAM; +-----------+-----------------+----------------+ | MEMBER_ID | REMARK | LAST_DATE | +-----------+-----------------+----------------+ | 1 | Techno Needy | 20000508105403 | | 2 | Meticulous Nick | 20000508105403 | | 3 | The Data Diva | 20000508105403 | | 4 | The Logic Bunny | 20000508105403 | +-----------+-----------------+----------------+ 4 rows in set (0.01 sec)
Say we've forgotten the full name of that Diva person:
mysql> select MEMBER_ID, FIRST_NAME, LAST_NAME, REMARK -> from TEAM -> where REMARK LIKE "%Diva%"; +-----------+------------+-----------+---------------+ | MEMBER_ID | FIRST_NAME | LAST_NAME | REMARK | +-----------+------------+-----------+---------------+ | 3 | Brittney | McChristy | The Data Diva | +-----------+------------+-----------+---------------+ 1 row in set (0.01 sec)
What if Brittney McChristy changes her last name to Spears?
mysql> update TEAM set LAST_NAME='Spears' WHERE MEMBER_ID=3; Query OK, 1 row affected (0.01 sec) mysql> select MEMBER_ID, FIRST_NAME, LAST_NAME, LAST_DATE from TEAM -> where MEMBER_ID=3; +-----------+------------+-----------+----------------+ | MEMBER_ID | FIRST_NAME | LAST_NAME | LAST_DATE | +-----------+------------+-----------+----------------+ | 3 | Brittney | Spears | 20010515134528 | +-----------+------------+-----------+----------------+ 1 row in set (0.00 sec)
Since LAST_DATE is the first TIMESTAMP field in the table, it's automatically reset to the current time whenever you make a change.
Now let's look at all the players whose favorite color is blue, listing the most recently-changed one first.
mysql> select MEMBER_ID, FIRST_NAME, LAST_NAME, FAV_COLOR, LAST_DATE from TEAM -> where FAV_COLOR = 'blue' -> order by LAST_DATE desc; +-----------+------------+-----------+-----------+----------------+ | MEMBER_ID | FIRST_NAME | LAST_NAME | FAV_COLOR | LAST_DATE | +-----------+------------+-----------+-----------+----------------+ | 3 | Brittney | Spears | blue | 20010515134528 | | 2 | Nick | Borders | blue | 20000508105403 | +-----------+------------+-----------+-----------+----------------+ 2 rows in set (0.00 sec)
Now let's create a table TEAM2 with a similar structure as TEAM.
mysql> create table TEAM2 ( -> MEMBER_ID int(11) not null auto_increment primary key, -> FIRST_NAME varchar(32) not null, -> LAST_NAME varchar(32) not null, -> REMARK varchar(64) not null, -> FAV_COLOR varchar(32) not null, -> LAST_DATE timestamp, -> OPEN_DATE timestamp); Query OK, 0 rows affected (0.01 sec) mysql> describe TEAM2; +------------+---------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +------------+---------------+------+-----+---------+----------------+ | MEMBER_ID | int(11) | | PRI | NULL | auto_increment | | FIRST_NAME | varchar(32) | | | | | | LAST_NAME | varchar(32) | | | | | | REMARK | varchar(64) | | | | | | FAV_COLOR | varchar(32) | | | | | | LAST_DATE | timestamp(14) | YES | | NULL | | | OPEN_DATE | timestamp(14) | YES | | NULL | | +------------+---------------+------+-----+---------+----------------+ 7 rows in set (0.00 sec)
Compare this with the TEAM decription above. They are identical (except for the multiple index we didn't create because this is a "simple" example).
Now, say you want to do a query in Python:
$ python
Python 1.6 (#1, Sep 5 2000, 17:46:48) [GCC 2.7.2.3] on linux2
Copyright (c) 1995-2000 Corporation for National Research Initiatives.
All Rights Reserved.
Copyright (c) 1991-1995 Stichting Mathematisch Centrum, Amsterdam.
All Rights Reserved.
>>> import MySQLdb
>>> conn = MySQLdb.connect(host='localhost', user='me', passwd='mypw', db='test')
>>> c = conn.cursor()
>>> c.execute("select MEMBER_ID, FIRST_NAME, LAST_NAME from TEAM")
4L
>>> records = c.fetchall()
>>> import pprint
>>> pprint.pprint(records)
((1L, 'Brad', 'Stec'),
(2L, 'Nick', 'Borders'),
(3L, 'Brittney', 'Spears'),
(4L, 'Fuzzy', 'Logic'))
Another approach is to have Python or a shell script write the SQL commands to a file and then run 'mysql' with its standard input coming from the file. Or in a shell script, pipe the command into mysql:
$ echo "select REMARK from TEAM" | mysql -t test +-----------------+ | REMARK | +-----------------+ | Techno Needy | | Meticulous Nick | | The Data Diva | | The Logic Bunny | +-----------------+
(The -t option tells MySQL to draw the table decorations even though it's running in batch mode. Add your MySQL username and password if requred.)
'mysqldump' prints a set of SQL commands which can recreate a table. This provides a simple way to backup and restore:
$ mysqldump --opt -u Username -pPassword test TEAM >/backups/team.sql $ mysql -u Username -pPassword test </backups/team.sql
This can be used for system backups, or for ad-hoc backups while you're designing an application or doing complex edits. (And it saves your butt if you accidentally forget the WHERE clause in an UPDATE statement and end up changing all records instead of just one!)
You can also do system backups by rsyncing or tarring the /var/lib/mysql/ directory. However, you run the risk that a table may be in the middle of an update. MySQL does have a command "LOCK TABLES the_table READ", but interspersing it with backup commands in Python/Perl/whatever is less convenient than mysqldump, and trying to do it in a shell script without running mysql as a coprocess is pretty difficult.
The only other maintenance operation is creating users and assigning access privileges. Study "GRANT and REVOKE syntax" (section 7.25) in the MySQL reference manual. I always have to reread this whenever I add a database. Generally you want a command like:
mysql> grant SELECT, INSERT, DELETE, UPDATE on test.TEAM to somebody -> identified by 'her_password'; Query OK, 0 rows affected (0.03 sec)
This will allow "somebody" to view and modify records but not to change the table structure. (I always alter tables as the MySQL root user.) To allow viewing and modifying of all current and future tables in datbase 'test', use "on test.*". To allow certain users access without a password, omit the "identified by 'her_password'" portion. To limit access according to the client's hostname, use 'to somebody@"%.mysite.com"'.
Remember that MySQL usernames have no relationship to login usernames.
To join multiple tables (MySQL is a "relational" DBMS after all), see "SELECT syntax" (section 7.11). Actually, all of chapter 7 is good to have around for reference. The MySQL manual is at http://www.mysql.com/doc/
-- Mike Orr
bash string manipulatingOn Thu, 10 May 2001, you wrote:
I realize that this question was quite old, but I just came across it while cleaning out my inbox. Here's a couple of quick suggestions:
Thanks very much, very useful.
First: don't use this sort of "psuedo array." If you want an array (perhaps an associative array, what PERL calls a "hash") then use an array. Korn shell supports associative arrays. Bash doesn't. With other shells, you'll have to check.
Not easy when you have to work with what is given ![]() Actually I ditched it all and rewrote the app in XML and XSLT
Actually I ditched it all and rewrote the app in XML and XSLT ![]()
///Peter
Linux in AfricaMartin is one of our authors.
Hi,
This is to inform the world of an idea we are playing with. I work for an 3rd world aid organisation and recently returned home from a trip to Dar es Salaam, Tanzania. One of the ideas I brought with me back was the wish of some of our member organisations to set up some kind of computer training in "rural" Tanzania.
The interest of computers, and computer aided training is great, the means of buying computers non-existant. So, the idea is to set up training centres using "second hand" computers. My idea is to have this equiped with Linux and Star Office which will be ideal in terms of priceing and stability - if not perhaps in trained staff.
All of this is of course only in a very early stage of planning, but we hope to go ahead with the project at the latest during next year. If anyone else has any experiences of similar projects I am interested in hearing from you!
Regards,
Martin Skjöldebrand CTO, Forum Syd The Swedish NGO Centre for Development Co-operation.
Your replyThank you for your reply...I know I answered it already but at that point I had only seen what was written on the TAG site (board/whatever) which was very brief. Your email to me had not arrived at that point, so I didn't get much of a message from you -as you may? have gathered from my answer to it. Sorry about my email settings...I was sending from a machine which was only just set up and running on defaults which I hadn't looked at. (Or maybe it was the setup of the message board....perhaps I pressed a "include html tags" button or something , not thinking. I really can't remember). I'll pay more attention to it in future. As for your answer, thank you very much. It will help me in the future, I'm sure. I don't really know anyone who I can talk to about this sort of stuff (computers) so reading what I can find and filing away little tips like that is pretty much my sole reference source when things f up. I only found out that TAG even existed on the weekend, so maybe I'll write again sometime. A really useful site.
Thanks again and keep up the good work helping people.
All the best, Peter.
On Sun, May 06, 2001 at 06:12:32AM +0100, Peter P wrote:
Content-Type: text/html; charset=iso-8859-1
Don't do that, please. Sending e-mail in any format other than plain text lowers the chances of your question being answered. It's impolite ... "Bad signature" is, of course, a software-dependent error, but it seems to be a pretty standardized one: what it usually means is that something scribbled over the last couple of bytes of the first sector on the drive. ...
just so you know...That others have been helped by having this out there. thanks!
Submission: A tired Newbie attempts LinuxOf all the articles I have read on how wonderful Linux is, seldom have I seen any that [cynically] document how the average Windows user can go from mouse-clicking dweeb to Linux junkie. Perhaps such an article does not exist? Or, maybe those that made the jump to Linux have forgotten the hoops us Win-dweebs are still facing.
A few years back, when this giant Linux wave began to crest, I was working for a local Electronics Boutique (EB) store for a few hours a week. Microsoft was in the news almost daily, and as the lawsuit against it grinded close to a close, anything Linux faired very well in the stock market and in the software reviews, it seemed. Heck, even EB was begining to stock games for Linux, maybe this is the little OS that can make it after all. So, like others, I took the dip into Linux, bringing home a copy of RedHat and pretty much every version since.
< Buying Linux >
Perhaps the first thing to be forgotten about Linux versus Windows was "Hey, Linux is FREE". What someone forgot to tell the rest of the world was that its one helluva download that doesn't always like to finish. And, up here in the NorthEast (Maine specifically), broadband wasnt here, so your idea of a good download was a 5.3k connect on the 56k modem! So, off to the store and buy a copy for $30 or so bucks. Then, not more than 3 months later, another build is out! Off we go and spend another $30 bucks....and repeat this process a few more times to our current build. Hmmm, well, its cost me more than all my Microsoft updates, and the Windows Update button sure is vastly easier than the Linux equivalent(s).
So, the claim of FREE FREE FREE really isn't so....I've found other places that you can buy a CD copy cheaper but still, some money negates the FREE.
Many free software notables would stand firmly on the point that "free" in "free software" is not about money, it's about your ability to improve, debug, or even use these applications after their original vendor gives up on them, disappears, or even simply turns to other things.
On the flip side(s) of this coin (these dice?), there are some who say "some work negates the FREE" ... such as your note below ... and those for whom a "free download" (which is certainly available for most Linux variants) is really quite expensive. Thus the appearance and eventual success of companies pre-loading Linux. - Heather
< Install...I dare you...>
Linux this, Linux that...that's all we've heard. Microsoft is bad (say using the Napsater Baaad sound effect from cartoon portraying Lars Ulrich). So now we give it the go, and guess what? The Linux operating system that w anted so much to be different from Windows looks JUST LIKE IT. Now while I will concede it IS easy to jump into for a user like me, all the books I had seemed to point to the beauty of working in the shell.
And another favorite of mine, something I can't understand at all. Why doesn't Linux do the equivalent of a DOS PATH command? Newbie Me is trying to shutdown my system and I, armed with book, type "shutdown -h now" and am told 'command not found'. But wait, my book says...etc etc....and of course, I now know you have to wander into sbin to make things happen. Why such commands aren't pathed like DOS is beyond me....perhaps that's another HowTo that has eluded me.
<...and the adventure continues...>
And now, two years later, I'm pleased to inform you that I have three Linux machines on my network, two are DNS servers and the other acts as my TUCOWS mirror. The DNS Servers work great....their version of BIND was flawed and five days into service, they were hacked into. Its just not fair, is it? But, my local Linux Guru solved the problem with a newer version of BIND and he's been watching over the machines to date. While I am still trying to learn more, its a slow process for a WinDweeb. While others wait for their ship to come in, I'm hunting for that perfect HowTo to guide me into the halls of Linux Guru-Land.
Paul Bussiere
While Paul later noted that he meant this "tongue in cheek" ... meanwhile, The Answer Gang answered him (see this month's TAG). Still, Linux Gazette will cheerfully publish articles aiding the true Newbie have a little more fun with Linux. If you have tiny picce of his "WinDweeb-to-LinuxGuru-HOWTO" waiting in you, check out our author guidelines, and then let us know! -- Heather
GIF -> PNGSoon, all GIF images in the back issues of LG will be converted to PNG or JPG format. If you have a graphical browser that doesn't display PNG images properly (like the ones in The Weekend Mechanic article), speak up now.
HelpDex is alive again!Hi all,
I'll try to get right to the point. It's been two months since HelpDex finished up on LinuxToday.com. Since then, strips have only been appearing on www.LinuxGazette.com but nowhere else. A huge thanks to Mike from LG for this.
Can you spread the word for me please, the more I know I'm wanted the more likely I am to not be lazy ![]()
Oh, and there's also plenty of cool reading around. Check out Sir JH Flakey (http://www.core.org.au/cartoons.php) and of course, ANY book that comes out of O'Reilly ![]()
Shane
 |
Contents: |
Submitters, send your News Bytes items in PLAIN TEXT format. Other formats may be rejected without reading. You have been warned! A one- or two-paragraph summary plus URL gets you a better announcement than an entire press release.
 June 2001 Linux Journal
June 2001 Linux Journal
The June issue of Linux Journal focuses on world domination! No, actually it focuses on Internationalization & Emerging Markets, but it does have a cool cover picture of penguins erecting a Linux flag on the South Pole, with sixteen national flags in the background. Inside, there's a security article called "Paranoid Penguin", and a game review about taming monsters (Heroes of Might and Magic III).
Copies are available at newsstands now. Click here to view the table of contents, or here to subscribe.
All articles through December 1999 are available for public reading at http://www.linuxjournal.com/lj-issues/mags.html. Recent articles are available on-line for subscribers only at http://interactive.linuxjournal.com/.
May/June 2001 Embedded Linux Journal
The May/June issue of Embedded Linux Journal focuses on Cross Development and includes an overview of the second ELJ contest, based on the New Internet Computer (NIC). Subscriptions are free to qualified applicants in North America - sign up at http://embedded.linuxjournal.com/subscribe/.
Linux Journal's 2001 Buyer's Guide Linux Journal's 2001 Buyer's Guide is on sale now. It is the only comprehensive directory of Linux-related vendors and services, and is well-known as the definitive resource for Linux users. The guide includes a quick-reference chart to more than twenty Linux distributions, and with over 1600 listings, the guide is bigger than ever. For more information visit http://www.linuxjournal.com/lj-issues/issuebg2001/index.html.
Linux Journal's 2001 Buyer's Guide is on sale now. It is the only comprehensive directory of Linux-related vendors and services, and is well-known as the definitive resource for Linux users. The guide includes a quick-reference chart to more than twenty Linux distributions, and with over 1600 listings, the guide is bigger than ever. For more information visit http://www.linuxjournal.com/lj-issues/issuebg2001/index.html.
The guide is available on newsstands through August 1, 2001, and is available at the Linux Journal Store on-line at http://store.linuxjournal.com/.
Russian Distributions of LinuxThis spring two new distributions of Linux came out in Russia.
ASP-Linux is based on Red Hat 7.0, and has been modified to provide the Linux 2.4 kernel as an installation option and given a new installation program that can be run from Windows to partition and install ASPLinux as a dual-boot option on an existing Windows machine. The installation program is called EspressoDownload. Although ASPLinux has strong Singaporean connections, the development team is largely Russian.
ALT Linux is a decendant of Mandrake Linux. The creators of this distribution were previously known as IP Labs Linux Team, but now have firm of their own. ALT Linux are distributing a beta-version of their new server distribution ALT Linux Castle. This distribution will have crypt_blowfish as main password hashing algorithm and a chrooted environment for all base services. Download is available.
CalderaCaldera Systems, Inc. has announced its completion of the acquisition of The Santa Cruz Operation, Inc. (SCO) Server Software and Professional Services divisions, UnixWare and OpenServer technologies. Caldera will now be able to offer "customized solutions through expanded professional services". Furthermore, Caldera has also acquired the assets of the WhatifLinux technology from Acrylis Inc. WhatifLinux technology provides Open Source users and system administrators with Internet-delivered tools and services for faster, more reliable software management.
Caldera has announced the launch of the Caldera Developer Network. Caldera developers, including members of the Open Source developer community, will have early access to UNIX and Linux technologies, allowing them to develop on UNIX, on Linux, or on a combined UNIX and Linux platform. This, plus the network's worldwide support and additional services, will enable members to build and develop their products with globally portable applications and get to market faster.
MandrakeMandrakeSoft have just announced the availability of their latest version, 8.0, in download format. This includes the newest version of the graphical environments KDE (2.1.1) and GNOME (1.4) featuring many new enhancements and applications. The 8.0 version promises to be the most powerful and complete Linux-Mandrake distribution while at the same time retaining the simplicity of installation and use that has made MandrakeSoft a recognized leader in the Linux field.
RockVersion 1.4 of ROCK Linux is ready to roll. This version is "intended" for production use, although the announcement warns that waiting another minor release or two would be prudent. ROCK is often referred to as being "harder to install" than other distributions. This is not strictly true. It aims to remain as close to the upstream software as possible rather than offering distribution bells and whistles. That said, a binary install is pretty easy, and a source install is not out of the question for an experienced user. ROCK does not contain an intrusive set of system administration utilities. The ROCK philosophy might be worth reading as would their guide.
SuSESuSE Linux 7.2 will be available June 15th. It includes kernel 2.4.4, KDE 2.12 and Gnome 1.4.
In addition, 7.2 for Intel's Itanium-based (64-bit) systems will be released June 20th, but this version will be available directly from SuSE only.
Upcoming conferences and eventsListings courtesy Linux Journal. See LJ's Events page for the latest goings-on.
|
|
|
| Linux Expo, Milan |
June 6-7, 2001 Milan, Italy http://www.linux-expo.com |
|
|
|
| Linux Expo Montréal |
June 13-14, 2001 Montréal, Canada http://www.linuxexpomontreal.com/EN/home/ |
|
|
|
| Open Source Handhelds Summit |
June 18-19, 2001 Austin, TX http://osdn.com/conferences/handhelds/ |
|
|
|
| USENIX Annual Technical Conference |
June 25-30, 2001 Boston, MA http://www.usenix.org/events/usenix01 |
|
|
|
| PC Expo |
June 26-29, 2001 New York, NY www.pcexpo.com |
|
|
|
| Internet World Summer |
July 10-12, 2001 Chicago, IL http://www.internetworld.com |
|
|
|
| O'Reilly Open Source Convention |
July 23-27, 2001 San Diego, CA http://conferences.oreilly.com |
|
|
|
| 10th USENIX Security Symposium |
August 13-17, 2001 Washington, D.C. http://www.usenix.org/events/sec01/ |
|
|
|
| HunTEC Technology Expo & Conference Hosted by Hunstville IEEE |
August 17-18, 2001 Huntsville, AL URL unkown at present |
|
|
|
| Computerfest |
August 25-26, 2001 Dayton, OH http://www.computerfest.com |
|
|
|
| LinuxWorld Conference & Expo |
August 27-30, 2001 San Francisco, CA http://www.linuxworldexpo.com |
|
|
|
| Red Hat TechWorld Brussels |
September 17-18, 2001 Brussels, Belgium http://www.europe.redhat.com/techworld |
|
|
|
| The O'Reilly Peer-to-Peer Conference |
September 17-20, 2001 Washington, DC http://conferences.oreilly.com/p2p/call_fall.html |
|
|
|
| Linux Lunacy Co-Produced by Linux Journal and Geek Cruises Send a Friend LJ and Enter to Win a Cruise! |
October 21-28, 2001 Eastern Caribbean http://www.geekcruises.com |
|
|
|
| LinuxWorld Conference & Expo |
October 30 - November 1, 2001 Frankfurt, Germany http://www.linuxworldexpo.de |
|
|
|
| 5th Annual Linux Showcase & Conference |
November 6-10, 2001 Oakland, CA http://www.linuxshowcase.org/ |
|
|
|
| Strictly e-Business Solutions Expo |
November 7-8, 2001 Houston, TX http://www.strictlyebusinessexpo.com |
|
|
|
| LINUX Business Expo Co-located with COMDEX |
November 12-16, 2001 Las Vegas, NV http://www.linuxbusinessexpo.com |
|
|
|
| 15th Systems Administration Conference/LISA 2001 |
December 2-7, 2001 San Diego, CA http://www.usenix.org/events/lisa2001 |
|
|
|
Linux@work Europe 2001 for FREE -- call for participation.For the third year, LogOn Technology Transfer will be organizing a series of Linux events throughout Europe called "Linux@work". Each "Linux@work" is composed by a conference and an exhibits. These 1-day, city-to-city events, will take place in several European venues in 2001. Among the keynote speakers: Jon "maddog" Hall, President Linux International and Robert J. Chassel, Executive Director Free Software Foundation. To register and for the full conference programs: http://www.ltt.de/linux_at_work.2001/.
Linux NetworX Expands Market Reach into EuropeLinux NetworX, a provider of Linux cluster computing solutions, has announced an international partner/distributor agreement with France-based Athena Global Services. Athena Global Services, a leading value-added distributor of new IT technologies in France, is the first authorized Linux NetworX distributor in Europe. The Linux NetworX newsletter has more details.
TeamLinux | explore New Interactive Kiosk Product LineTeamLinux | explore have announced the immediate availability of a complete product line including six new units. Ranging in suggested base price from $1,499 to $6,500, the kiosks are designed for a wide variety of business environments and offer a selection of optional feature packages to suit the multimedia and transactional needs of users. The TeamLinux | explore's new kiosk line incorporates multiple performance and peripheral options including touch screens, printers, magnetic card devices, modems, keyboard and pointing devices, videoconferencing capabilities, and wireless connectivity.
IBM Offers KDE TutorialIBM has added a free tutorial on desktop basics using "K Desktop Environment" or KDE to its growing collection on the developerWorks Linux Zone. This tutorial will teach Linux users of ever level to customize thier own KDE GUI. Released February 26, KDE 2.1 addresses the need for an Internet-enabled desktop for Linux.
Linux BreakfastTimes N Systems is hosting a technology breakfast series and would like to invite you. Their technology focuses on IP-SAN and storage virtualization...and works well with Linux.
The breakfast is educational and they have got Tom Henderson from Extreme Labs coming to speak. RSVP online.
Linux LinksPython
Bad economy is good for open source.
Microsoft denounces open source.
mamalinux is one of Montreal's largest Linux portals.
May 9 (1996) was the day that Linus Torvalds said he wanted a penguin to be the mascot for Linux... a cute and cuddly one at that... :). So, belatedly, you can view A Complete History of Tux (So Far) as a kind of birthday celebration.
FirstLinux.com are watching TV with Zapping under Linux.
A correspondent has recently written an article showing how Xalan-J can be used in a Java servlet to perform XSL transformations and to output HTML and WML. Perhaps of interest.
ssh 2.9ssh 2.9 has been released. Thanks to LWN for the story.
Aladdin StuffIt: Linux and Solaris BetasAladdin Systems, Inc. unveiled public beta versions of StuffIt its compression technology , and StuffIt Expander, a decompression utility, for Linux and for Sun's Solaris operating systems. StuffIt for Linux and Solaris can be utilized to create Zip, StuffIt, Binhex, MacBinary, Uuencode, Unix Compress, self-extracting archives for Windows or Macintosh platforms and it can be used to expand all of the above plus tar files, bzip, gzip, arj, lha, rar, BtoAtext and Mime. The StuffIt public beta for Linux can be downloaded at www.aladdinsys.com/StuffItLinux/, and StuffIt for Solaris beta can be downloaded at http://www.aladdinsys.com/StuffItSolaris/.
XFceXFce is a GTK+-based desktop environment that's lighter in weight (i.e., uses less memory) than Gnome or KDE. Applications include a panel (XFce), a window manager (XFwm), a file manager, a backdrop manager, etc. Version 3.8.1 includes drag and drop, and session management support. Several shell scripts are provided as drag and drop "actions" for panel controls (e.g., throw a file into the trash, print a file). All configuration is via mouse-driven dialogs.
Heroix Announces Heroix eQ Management Suite for LinuxHeroix Corporation have released the Heroix eQ Management Suite, which unifies management of Windows 2000, Windows NT, Unix, and Linux Systems. The new product family improves the performance and availability of eBusiness and other critical applications by unifying monitoring and management of multiplatform computing environments.
New Product Brings Computation to the WebWolfram Research Inc. is pleased to announce the upcoming release of webMathematica, which is a solution for including interactive computations over the web. While not yet officially released, it is currently available to select customers under the preview program.
There has been significant interest in webMathematica during the testing phase, resulting in several new partnerships for Wolfram Research. Select banks, engineering firms, and other institutions are already using webMathematica. See http://library.wolfram.com/explorations for examples of possible webMathematica applications.
Lutris To Speed Development of Web and Mobile Applications with Hewlett PackardLutris Technologies Inc., a provider of application server technology for wired and wireless development and deployment, has announced a sales and marketing agreement with Hewlett-Packard to deliver Lutris Enhydra 3.5 to HP's customers for developing and deploying enterprise-level applications on HP Netserver systems running Linux and Windows 2000. The solution will enable the creation and deployment of Internet and wireless Web applications.
QuickDNS 3.5 for LinuxReykjavik, Iceland-- Men & Mice release QuickDNS 3.5, a comprehensive DNS management system for Linux systems. QuickDNS is the leading DNS management system for Mac for nearly 5 years. QuickDNS on Linux will enable simultaneous management of DNS servers on different platforms, using an easy-to-use interface. Setting up QuickDNS is simple as it runs on top of BIND 8.2.x.
QuickDNS 3.5 retails for $495 for one licence and $790 for a pack of two licences. Free downloads are also available
Opera NewsOpera Software and Google Inc., developer of the award-winning Google search engine, have signed a strategic agreement under which Opera will integrate Google's advanced search technology into its search box feature on the Opera Web Browser. Available now, direct access to Google's search technology enables Opera users to quickly search and browse more than 1.3 billion Internet pages.
Opera Software have launched a new version of Opera for Linux. Opera 5 (final) offers an Internet experience for the Linux platform as hassle-free as on Windows. Today's release affirms Opera Software's leadership in cross-platform browser development.
In addition to the usual Opera features such as speed, size and stability, users will find exciting features not yet implemented in the Windows version. The extensive customization possibilities for user settings, additional drag-and-drop features and the Hotlist search function are features only available in the Linux version. An add supported version of Opera 5 is available for free download.
New Free Xbase Compiler: Max 2.0PlugSys have announced availability of Max 2.0 Free Edition, the 32-bit Xbase compiler for Linux and Windows providing free registration to application developers worldwide. Using classic Xbase commands and functions, Max developers write character-based applications that access data from FoxPro, dBASE and Clipper. To ensure scalability, Max also connects to all popular SQL databases. The product can be downloaded from the PlugSys.com web site.
Loki Games and NokiaNokia and Loki have formed an Agreement to Distribute Linux Games with the Nokia Media Terminal, a new "infotainment" device that combines digital video broadcast, gaming, Internet access, and personal video recorder technology. As part of the agreement Linux-based games from Loki will be pre-installed on the Media Terminal. Anticipated roll out of the Media Terminal will be early Fall in Europe. Nokia is demonstrating the Media Terminal and will show the ostdev.net open source network at the E3 exhibition in Los Angeles 16-19 May.
Loki Software, Inc. have announce that MindRover: The Europa Project for Linux will ship on Wednesday, May 23. MindRover from CogniToy is the 3D strategy/programming game enabling players to create autonomous robotic vehicles and compete them in races, battles and sports. MindRover has an SRP of $29.95, and is now available for preorder from the new Loki webstore. A list of resellers is also available.
VMware/Cisco Mutliple OSs on a Single Box and Streaming Media Version 0.7.1 of OSALP AvailableBeta release 0.7.1 of the Open Source Audio Library Project has been released (Linux, Solaris Sparc, and FreeBSD). The OSALP library is a C++ class library that provides the functionality one needs to perform high level audio programming. The base classes allow for building audio functionality in a chain. The derived classes support such functions as audio editting, mixing, timer recording, reading, writing, and a high quality sample rate converter. New in the 0.7.1 release is support for FreeBSD, numerous bug fixes, new Makefile system, and a new mp3 reader module based on the open source splay library.
Other software The Answer Gang
The Answer Gang 
There is no guarantee that your questions here will ever be answered. You can be published anonymously - just let us know!
 Greetings from Heather Stern
Greetings from Heather SternFor those of you who've noticed this ran late, sorry 'bout that! I had a DSL outage ... in fact, if it had just plain died it might have been easier, since I would have known to reach for a backup plan.
But, things are all better now. Boy have I got a new appreciation for the plight of those stuck behind a slow dialup line. Ouchie. Now we have a brand new router and a freshly repaired external DSL drop.
Okay, enough of that. I want to give a big hand of appluase for the new, improved Answer Gang. The Gang deserves a giant standing ovation is that over 400 slices of mail passed through nthe box this month. That's about twice as many as the month before... and a lot of people got answers ![]()
As always I remind you that we can't guarantee that you'll get one... and nowadays I can't even manage to publish all the good ones. I stopped pubbing the short-and-sweet FAQs a few issues ago.
We have some summary bios. Not everyone -- some of us are shy -- but now you can know a few of the Gang a bit better.
Last but not least, there's a big thanks to my Dad in there. Enjoy!
Need a Free StarOffice KillerFrom Amil
Answered By Thomas Adam, Heather Stern
Hi,
I would like to know which is an alternative for staroffice5.2 . i need all word excel powerpoint in one package which acts as an substitute for star office . moreover the package should be freely available in net
Regards
Anil
[Thomas] Hi Anil,
I believe that the only package that would offer what you wanted would be the commercial product ApplixWare......
HTH,
Thomas Adam (The Linux Weekend Mechanic)
You mention MS' products by name so if you hope for file exchangeability, Siag Office won't be a usable substitute. If you don't care about that, don't limit yourself to a bundled office.
There are plenty of shots at word processors (some of them even pretty good, regardless of my editorial rants), more spreadsheets than I dare count, and a presentation package or two, available "unbundled" (the Gnome and K environments don't require you to get all of their apps) but again, their talents at handling MS' proprietary formats are severely limited.
Abiword is free and able to give Word files a half-decent shot at loading up. If you stick with RTF exports, a lot more things would work, but I know MS doesn't export everything useful when they do that. It doesn't export virii that way either
Xess looks to me to be the best Excel clone for Linux, but is also a commercial app. It will definitely read Excel files.
For Powerpoint, well... Magicpoint won't read it. Magicpoint is a decent presentation program, but designed to be much simpler, and let you embed cool effects by "swallowing" running app windows. It's very much designed for X rather than anything else. On the plus side, its files are tiny, since they're plaintext (albeit with a layout). I don't know any free source software offhand that I know loads Powerpoint slides.
If none of those are good enough, expect to pay commercial prices for commercial quality work. "Demo" does not mean "excuse to rip off the vendor" it means "chance to try the product before buying it if you like it". The "freedom" in open source work is about being able to use and improve tools long after their original vendors/authors have ditched them, not about putting the capitalist economic system on its ear.
pps filesFrom adrian darrah
Answered By Ben Okopnik, Karl-Heinz Herrmann
Hello, I've been sent a "pps" file from someone at his place of work. Can you advise where best to download the necessary software from internet source to open such a file.
Many thanks Adrian Darrah
http://www.springfieldtech.com/HOW_DO/File_type.htm
I get
.PPS MS Power Point Slide Show file
So this is probably a propietary Microsoft Power Point file. I was just going to say that _free_ and M$ don't go well together, but there seem to be some Linux projects:
- Magic Point:
- http://www.freeos.com/articles/3648
Though This looks like a "Poer Point" replacement I can't find a comment stating it will read/use PPS files.
[Dan] I've had pretty good luck viewing Power Point presentations with StarOffice.
[Karl-Heinz] All other search engine results ( http://www.google.de ) concerned the power of some floating point number.....
My conclusion would be: Get a different file format or MS Power Point if you have to use that files, Star Office would maybe be an option.
Checks vs. Plain PaperFrom James McClure
Answered By Dan Wilder, Jim Dennis, Ben Okopnik, Heather Stern, Mike Orr
I need to find a way to print to specific forms, such as checks, invoices, etc. Whenever my accounting people get ready to print out checks, it never fails that someone will send a print-job to the printer. It will then be printed on the checks instead of normal paper. Is there a way to accomplish this through LP... from what I've tried, read, and heard... I've had NO LUCK!
Any help is appreciated!
James McClure
![]() Apologies... I'm running RedHat 6.1 (Kernel 2.2) with LPD.
Apologies... I'm running RedHat 6.1 (Kernel 2.2) with LPD.
James
There's at least 4 types of possibile answer...
0. Have a seperate printer, then you don't need this question.
If you were printing more than one pre-printed form, say, checks drawn against five different accounts, each once a month, having five dedicated printers sitting idle most of the time, and a sixth for everyday use, would seem maybe just a little wastful of the equipment budget.
1. Construct a scripted front end to help you handle it:
- On printer laz insert form "company 1 checks" and hit ENTER
- [ prints check job after ENTER ]
- On printer laz insert form "plain letter-size paper" and hit ENTER
- [ prints the plain paper job ]
I'm unaware of anything quite so friendly for Linux forms handling. Instead, as you've observed, we have lpd.
Have you investigated using the lpc command for this? By doing
lpc
holdall laz
[ run the check job ]
lpq
[ lists print jobs held. Figure out which one is your check-printing batch. ]
release jobid
[ releases the job with id "jobid" for printing ]
release laz
[ releases all remaining jobs, after special forms jobs are finished ]
You'd have to set up sudo to allow selected users to run lpc.
2. Try to use the queues feature built into lpr:
lpr -Pcheck
you'd use lpc:
lpc
holdall laz
[ wait until printing on "laz" stops, then change forms ]
release check
[ or 'lpq' then 'release jobid' ]
[ wait until check printing stops ]
holdall check
release laz
This saves having to guess which jobs are checks.
Of course you can use lpc in shell scripts to automate the work of stopping and starting specific queues.
The disadvantage of "start check" is you must remember to "stop check" when you're done. By using the ":ah:" flag you _might_ not have to remember one more step at the end.
Darned if I can see from the documentation what the functional difference between "stop printer" and "holdall printer" is. Both appear to allow queuing, while holding print. "holdall" doesn't appear to apply to current jobs, so the default non-check printer might finish printing more stuff after "holdall lp" (or whatever name is used for that printer) than "stop lp".
So maybe the perfect sub-optimal solution is:
lpc stop lp [ wait for current job to finish ] [ insert check forms ] start check [ wait for checks to print ] stop check start lp quit
or a setuid CGI that issues equivalent commands.
I'd probably try the first solution suggested above, then set up some scripting stuff to save steps once the "easiest" procedure has been finalized. The "real" solution is to have a separate check printer; anything less is going to require juggling, and anything we can suggest here that's short of that is going to be painful in some way. <shrug> That's Life with Band-Aids for you.If you were printing more than one pre-printed form, say, checks drawn against five different accounts, each once a month, having five dedicated printers sitting idle most of the time, and a sixth for everyday use, would seem maybe just a little wastful of the equipment budget.
But then, I always put a monitor someplace near each printer. Often a plain old text console.
3. Or you can see if one of the new printing systems makes it easier than we described here:
- The Linux Printing HOWTO
- http://www.linuxdoc.org/HOWTO/Printing-HOWTO/index.html
This has a section on spooling software which, naturally enough, includes links to the major free spooling packages.
- The Linux Printing Usage HOWTO
- http://www.linuxdoc.org/HOWTO/Printing-Usage-HOWTO.html
- The LPRng HOWTO:
- http://www.astart.com/lprng/LPRng-HOWTO.html
Hey, check it out, you can specify job classes, so you could actually tell the single printer that it only has plain paper in it right now, so hold all jobs that are of the check class. I'm sure this can easily be extended to letterhead or other special forms. The tricky part is to have your check runs properly register that they are of the "check" class so this would work.
- [Mike] CUPS: the Common Unix Printing System
- http://www.cups.org
- PDQ: Print, Don't Queue
- http://pdq.sourceforge.net
- Links to these and more on the Linux Printing site.
- http://www.linuxprinting.org
![]() Thanks for your help!
Thanks for your help!
James
Free Business Consulting: NOT!From Abdulsalam Ajetunmobi
Answered By Jim Dennis
Dear Sir,
I am a Computer Consultant based in London, United Kingdom. I am, in conjuction with two other partners, making enquiry on how to set up Internet Service as a busness outfit in line with the estbalished ones like AOL, Compuserve etc. Our operation will be based in Africa.
Could you kindly advise me of what it entails and the modality for such a business. I would like to know the required equipment, the expertise and possibly the cost.
Thanks for your co-operation.
Yours faithfully,
Abdulsalam Ajetunmobi
It is true that Linux is ubiquitously used by ISPs as a major part of their network infrastructures. Actually FreeBSD might still have a bit of an edge over Linux. It's true that free UNIX implementations have grown to dominate the once mighty SunOS and Solaris foothold in that field.
Microsoft's NT gained some ground among ISP startups in the nineties; but lost most of that to their own instability, capacity limitations and pricing. NT at ISPs now exists primarily to support customers who demand access to Microsoft's proprietary FrontPage extensions or other proprietary protocol and service offerings.
So some might claim that your question is indirectly "about Linux." Of course that would be like saying that questions about setting up a new automotive dealership are "about automotive mechanics."
Here's my advice: if you don't know enough about the "modality" of the ISP business, if you have to ask us what setting up an Internet service entails, then you aren't qualified to start such a business.
First, the basic technical aspects of setting up an internet service should be obvious to anyone who as used the Internet. You need a persistent, reliable set of high speed and low latency connections to the Internet. (Duh!) You need some equipment (web servers, name servers, mail exchangers and hosts, routers, hubs, and some sort of administrative billing and customer management systems --- probably a database server). You need the technical expertise to manage this equipment and to deal with the vendors (mostly telcos; telephone service companies and other ISPs) that provide you with your Internet services.
Some elements that are non-obvious to casual Internet users are: ISPs are loosely arranged in tiers. Small, local ISPs connect to larger regions ISPs. Regional ISPs perform "peering" with one another and with larger, international ISPs. Some very large ISPs (like AOL/Compuserve and MSN, etc) get to charge hefty peering fees from smaller and intermediate ISPs. When you link up with "podunk.not" they often only have one connect to one "upstream" provider. A better "blueribbon.not" might have a couple of redundant POPs (points of presence) and a redundant links to a couple of upstream providers.
Now, the business requirements (for any business) depend on a detailed understanding of the business at hand. You have to know how to get the service or product on the "wholesale" side, possibly how to package and/or add value to that service or product, and how to re-sell it to your customers. If you don't know the difference between a third tier ISP and a backbone provider; you don't know enough to formulate a sensible business plan in that industry. If you don't have contacts in that industry and in your market segment within that industry then you should seriously ask what possible advantage you could have over your competitors.
(Don't start any business without an advantage. That makes no sense. If you don't truly believe in your advantage --- go work for someone who does have one).
Perhaps you think that you won't have any competitors in Africa; or that you have some business angle that none of them have. Great! Now go find and hire someone who knows that business in that market. Then you can do your own feasibility study to see if there are real opportunities there.
Keep in mind that you are likely to need professional contacts in the regional governments where you intend to operate. Throughout most of the "third world" there is quite a bit of overt corruption --- and outright graft is just a part of doing business in most places outside of the United States and western Europe. Don't get me wrong, I'm not saying that the governments and bureaucracies in Africa are more corrupt than those in the U.S. --- just that the corruption is more overt and the graft is more likely to be direct cash, rather than through the U.S. subtefuges of "campaign contributions" and various other subtleties.
Anyway, if you don't like my answer keep in mind that this question is basically not appropriate for this forum. Other readers will probably flame me and call me a racist for my comments about the customs in other countries. Oh well. I'll just drop those in /dev/null. (Rational refutations; pointing to credible comparisons or independent research would be interesting, though).
Success and Horror StoriesFrom Faber Fedor
Answered By Jim Dennis
Anyone know where I can find success/horror stories about setting up and running VPNs under (Red Hat) Linux? I've got all the HOWTOs, tutorials, and theory a guy could want. I've even heard rumblings that a Linux VPN isn't "a good business solution" but I've not seen any proof one way or another.
TIA!
However, there isn't such a forum, to my knowledge. Even if there was, it would probably not get much "legitimate" traffic considering that crackers thrive on their reputation for successful 'sploits. They'd consider it very uncool to catalogue their failures for us.
Aside from that any forum where firewalls, VPNs and security are discussed is likely to be filled with biased messages and opinions. Some of the bias is deliberate and commercially motivated ("computer security" is a competitive, even cut throat, business). In other cases the bias may be less overt. For example the comp.security.firewalls attracts plenty of people with a decided preference for UNIX. I don't see any recent traffic on comp.dcom.vpn (but that could be due to a dearth of subscribers at my ISP --- which dynamically tailors its newsfeeds and spools according to usage patterns).
I would definitely go to netnews for this sort of research. It tends to get real people expressing their real preferences (gripes especially). Most other sources would be filled with marketing drivel and hype, which is particular prevalent in the fields that relate to computer security, and encryption.
(I visited the show floor at the RSA conference in San Francisco last month. It was fascinating how difficult it was for me to figure out whether each company was hawking services, software or hardware --- much less actually glean any useful information about their products. Talk about an industry mired in vagary!)
Incidently the short answer regarding the question: "What are my choices for building a VPN using Linux systems" comes down to a choice among:
- FreeS/WAN (Linux implementation of the IETF IPSec standards)
- http://www.freeswan.org
- CIPE (Crypto IP Encapsulation over UDP)
- http://sites.inka.de/~W1011/devel/cipe.html
- VTun
- http://vtun.sourceforge.net
- vpnd
- http://sunsite.dk/vpnd
- PoPToP (MS PPTP compatible)
- http://poptop.lineo.com
There are probably others. However, I've restricted my list to those that I've heard of, which have some reasonable reputation for security (actually the PPTP protocol seems to be pretty weak, but I've included PoPToP in case a requirement for Microsoft compatibility and an aversion to better MS compatible tools overrides better judgment). I've only listed tools which are able to route TCP/IP traffic (rather than including application specific single connection "tunnels" --- which would be adequate for some applications but which don't constitute a "VPN").
I specifically left out VPS (a project that used PPP through ssh tunnels). This approach was useful in its day (before FreeS/WAN was released and while CIPE et all were maturing). However, the performance and robustness of a "PPP over ssh" approach was just barely when I was last using it with customers. I've recommended that they switch.
Normally I'd recommend the Linux Documentation Project (LDP) HOWTOs. However, this is one category (http://www.linuxdoc.org/HOWTO/HOWTO-INDEX/networking.html#NETVPN) where the LDP offerings are pretty paltry (I should try to find time to contribute more directly there). In fact the VPN HOWTO (http://www.linuxdoc.org/HOWTO/VPN-HOWTO.html) suggests and describes the VPS (PPP over ssh) approach (though it doesn't use the VPS software package, specifically). I've blind copied the author of that HOWTO on this, in case he feels like updating his HOWTO to point at the most recent alternatives for this.
The other HOWTOs in this category relate to running FreeS/WAN or CIPE behind an IP masquerading router (or Linux box), and using PPP over a telnet/tunnel to "pierce" through a firewall.
Hope that helps. There isn't much in the way of "easy to use" prepackaged VPN distros, yet.
RE: Linux Dialin ServerFrom Kashif Ullah Jan
Answered By Karl-Heinz Herrmann
Pls provide info regarding DIAL-IN SERVER for Linux with CALL BACK Facility.
I have access to a call back server here. It is setup to dial back to me, but it will act as server, i.e. it will insist on choosing the IP and everything. It also will not authenticate itself properly (or I couldn't figure out how), but I have to authenticate myself to the call back machine as if I would login there.
basically you need some program which is listening to your modem and acts o= n connections. I use mgetty which even has a auto ppp detection mode. http://www.leo.org/~doering/mgetty
A properly configured mgetty listening on the modem will not disturb outgoi= ng connections. Only when the modem is free again it will start listening for incoming calls.
Then you will have to setup pppd so incoming calls as "autoppp" will authenticate themselfs correctly to the call back server. Thats basic pppd setup with pap secrets here, but can be different for you.
If you have more specific questions I can try to help you along.
K.-H.
hello gang out there, another sendmail case :>From Piotr Wadas
Answered By Faber Fedor
I have the following sendmail problem: For backup purposes I boss ordered me to force sendmail to make carbon or blind copy of each mail (which comes in, out, or which is to be relayed through box) to specified account.
![]() While browsing sendmail docs all I found was some mysterious sounds about any sendmail 'scripting language' which supposed to be called "Milton" or "Miller" or something like that, which allows that feature, and is to be installed by patching sendmail and re-compiling it.
While browsing sendmail docs all I found was some mysterious sounds about any sendmail 'scripting language' which supposed to be called "Milton" or "Miller" or something like that, which allows that feature, and is to be installed by patching sendmail and re-compiling it.
![]() But I feel there must be a simpler rule to do this - maybe by rewriting some "From:" and "To:" envelopes or something?
But I feel there must be a simpler rule to do this - maybe by rewriting some "From:" and "To:" envelopes or something?
![]() Are you familiar with such problem?
Are you familiar with such problem?
.
However, there is an easy solution: install postfix. Postfix is a "drop-in replacement" for sendmail, i.e. any programs that already rely on sendmail will continue to work without any changes on your part.
To do what you want with postfix is done simply by adding one line to a configuration file. And, there are two nice howtos (written my the above-mentioned mail guru) that you can read at
http://www.redhat.com/support/docs/howto/RH-postfix-HOWTO/book1.html
and at
http://www.moongroup.com/docs/postfix-faq
(they assume you're running Red Hat and using RPMs, but it still legible
Linux Kernel Crashdumps: HOW?From Sachin
Answered By Jim Dennis
Hi All,
How do we configure dump device on linux( SuSE 7.1 ) so that when system panics I can get kernel crash dump.I have two scsi disks and want to use one of the scsi disk as dump device.
Thanks,
Sachin
More to the point, the canonical Linux kernel doesn't include "crashdump" support (where a kernel panic dumps the system core state to the swap partitions or some other device). Linus doesn't consider this to be a sufficiently compelling feature to offset the increased code complexity that it entails. (Linux also doesn't panic as easily as some other UNIX kernels --- it will log an "Oops" for those hardware errors or device driver bugs that are considered "recoverable").
However, if you really want this feature, you can apply the "lkcd" (Linux Kernel Crash Dump) kernel patches from SGI's OSS (Open Source Software) web site at:
http://oss.sgi.com/projects/lkcd
You'll also want to grab the suite of utilities that goes with the kernel patch. The vmdump command configures the kernel to use its dump feature (telling it which swap partition to use for example) and another vmdump directive is normally used to detect and save dumps. (If your familiar with the 'savecore' command in some other forms of UNIX, then this will make sense to you).
There's also an 'lcrash' utility which is used to help perform crashdump analysis.
Note that there are a number of other "unofficial" kernel patches like this one. For example there are interactive kernel debuggers that you can compile into your system's kernel.
You can read about some of them at:
http://oss.sgi.com/projects
... and find more at:
- Rock Projects Collection (takes over where Linux Mama left off)
- http://linux-patches.rock-projects.com
LinuxHQ http://www.linuxhq.com/kernel (Look for the links like "Unofficial kernel patches").
- IBM ("Big Blue")
- http://oss.software.ibm.com/developer/opensource/linux/patches/kernel.php
(Mostly small, deep performance tweaks and bugfixes, and simple feature enhancements).
Ibiblio (formerly Metalab, formerly Sunsite.unc.edu) http://www.ibiblio.org/pub/Linux/kernel/patches!INDEX.html (Mostly very old).
- Adrea Arcangeli (et al)'s In Kernel Debugger:
- ftp://e-mind.com/pub/andrea/ikd
- The International/Crypto Support Patch
- http://www.kerneli.org
- FreeS/WAN IPSec (includes some patches which aren't at kerneli)
- http://www.freeswan.org
- Solar Designer's Security Features Patches
- http://www.openwall.com/linux
- ... and some additions to that from "Hank":
- http://www.doutlets.com/downloadables/hap.phtml
- ... and the "Linux Intrusion Defense/Detection System"
- http://www.lids.org
(which mostly incorporates and builds upon the Openwall patches and lots more)
- U.S. National Security Agency's "Security Enhanced" Linux
- http://www.nsa.gov/selinux/download.html
(Yes, you read that right! The secretive "no such agency" has released a set of open source Linux patches. Everybody's getting into the Linux kernel security patch game!)
- ... and even more
- http://www1.informatik.uni-erlangen.de/tree/Persons/bauer/new/linux-patches.html
(Links with some duplicates to the list I've created here).
I've deliberately left out all of the links to "real-time" kernel patches. (I think I created a link list for an answer that related to various forms of "real-time" Linux (RTLinux, RTAI, KURT, TimeSys.com et al) within the last couple of months. (Search the back issues for it, if you need more on that).
So, obviously there are alot of unofficial kernel patches out there.
One reason I went to the bother of list all these sites, is that I'm guessing that you might be doing kernel development work. Linux kernels just don't crash very often in production use so that seems like the mostly likely reason for anyone to need crash dump support. (Besides, it'll amuse the rest of my readership).
Among these many patches you may find good examples and useful code that you can incorporate into your work.
Homework assignment: define these Linux termsFrom Maria Alejandra Balmaceda
Answered By Karl-Heinz Herrmann
i would like to know if you can define to me this words:
![]() Linux UNIX
Linux UNIX
- another history overview is on:
- http://perso.wanadoo.fr/levenez/unix
Since then many clones and reimplementations of very similar Operating systems have been released. Most of them were developed by some company and sold running on their hardware (HP unix, IBM 's AIX, Dec OSF, Cray unicos, ....).
Another one of them is Linux -- a Unix kernel rewrite started as a project by Linus Torvalds with the remarkable difference that the Linux kernel was and is free -- free in the sense that everybody has access to the source and is free to redistribute it as well as modifying it.
Linus' work was made possible by another project: GNU. See below.
![]() Kernel
Kernel
The kernel also is code which has more or less free access to memory and hardware in contrast to "user space" where the hardware access has to go through the method the kernel provides.
![]() GNU
GNU
This had all the tools like compilers which are necessary to buid an operating system as well as all the little commandline programs which make the Linux kernel to a Unix like operating system (what would one do without commands like ls, mv, ps or sh, bash, ....).
Among other things a real GNU project utility author would have transferred his, her, or their copyrights to FSF, something which not everyone feels inclined to do, by a long shot.
![]() Free BSD
Free BSD
![]() Open Source
Open Source
- also an interesting read:
- http://www.tuxedo.org/~esr/writings/cathedral-bazaar
![]() Sistema Operativo
Sistema Operativo
![]() RMS
RMS
Its also the initials of Richard M. Stallman: www.stallman.org or maybe http://www.eff.org (Electronic Frontier Foundation) for more on him.
![]() Linus
Linus
![]() Distribución
Distribución
"Linux" is only the kernel of an operating system. Along with it one needs GNU tools and a lot of other free, open source or commercial software for a productive computer system.
Companies evolved which pack ready made systems including a kernel and a selection of tools and programs acording to their distribution philosophy. Even if the software and kernel itself is free and freely redistributable the companies can charge for the work to arrange everything so one can choose what to install and make sure that everything will work together. Also you will get about 1 to 7 CD and a handbook from most of them.
![]() Debian, Red Hat
Debian, Red Hat
Many distros can easily be found at their .com or .org domain. Linux Weekly News (LWN) has a really nice sidebar leading to lots of distros, many especially tuned for some special purpose.
![]() LUG
LUG
This list is neither complete nor very objective, so have a loog at your search engine of choice for more details and different views
K.-H.
Download LinuxFrom bugzy247
Answered By Karl-Heinz Herrmann
I wanted to know where I can download the full version of the new Linux, that is for a personal computer (i.e. instead of using Windows)
There is a ever growing collection of Linux distributions out there.
You want to choose one to install your system. There are the bigger ones like RedHat, SuSE, Debian which will come on a several CD set. There are smaller ones like Mandrake, icelinux, .... however they are called.
Then there is slackware -- that available online and as CD (low cost) but it does not come with any support.
- [Heather] I wouldn't exactly call installation-only "no support":
- http://www.slackware.com/support
Many distros have a free version (they sometimes call it an evaluation disc) which comes with no support, but which you can copy to anyone who needs it. So, those are the kind you get for about $5 at the average CD libarary shop like CheapBytes. It's also usually only 1 or 2 discs, so at least it's less to download, if you go that route.
Debian's "pseudo image kit" is the most curious download - if you aren't stuck on an OS/2 box or somesuch, you can fetch a partial image and rsync in the corrections: http://cdimage.debian.org
- A quite puristic version would be Linux from scratch:
- http://www.linuxfromscratch.org
If you are completely new to Linux I would try to look for some Linux user nearby and take what he uses -- that way he can help a lot better.
If you don't know anybody using Linux I would recommend one of the more complete distributions together with manual -- it will help to have something printed. It's sometimes difficult to read online documentation if the system won't run properly yet .-)
If you wan't to look at the distributions websites try: http://www."name of distri".com (or maybe .org).
- Also I recommend The Linux Documentation Project:
- http://www.linuxdoc.org
- [K.H.] especially the Guides:
- http://www.linuxdoc.org/guides.html
- and "Getting Started":
- http://www.linuxdoc.org/LDP/gs/gs.html
Hope that hleps you along,
K.-H.
Kernel upgradeFrom andrew
Answered By Dan Wilder, Jim Dennis, Heather Stern
Hi,
I have recently upgraded my kernel from 2.2.12-20 to 2.2.19 & overall it is finding the new one ok. My machine is a Redhat 6.1 machine
Once you upgrade a new kernel can you simply do another make menuconfig to go through your options again.?
![]() One of the bad things that happened when i was doing this upgrade was put the tarred file in my /usr/src/ directory . This is what a help page told me to do. Problem was though that when i untarred the kernel it overwrote my linux folder that was already in there. %^%$##.
One of the bad things that happened when i was doing this upgrade was put the tarred file in my /usr/src/ directory . This is what a help page told me to do. Problem was though that when i untarred the kernel it overwrote my linux folder that was already in there. %^%$##.
What do you think ?? What do you suggest Regards...
When upacking a tar archive, first
tar tvzf your.archive.tgz | head -20
to see what it's going to do. If there's a directory in the way, move it.
I'm not sure why the linux kernel upacks to a "linux" directory. Most GNU software unpacks to a directory that contains a version number. In view of Linus's oft-repeated insistance that keeping the source tree in /usr/src/linux is considered harmful, I'd think he would archive, for example, 2.2.19 so that linux-2.2.19.tar.gz would unpack to a directory called linux-2.2.19.
I always rename my kernel source directory immediately after unpacking it. So the the 2.2.19 source is indeed in a directory called linux-2.2.19. Then I re-establish the symlink of /usr/src/linux -> /usr/src/linux/kernel-includes-2.2.xx
LFS: Large File Summit/SupportFrom Albert
Answered By Jim Dennis
Hi,
I have an Intel-based box running RedHat 7.x, 2.4.x kernel and I'm trying to write code to support large file (>4GB) writes and seeks. According to the manual pages, the llseek() would handle 64-bit seeks if the kernel supported. However, I can't get my compiler to recognize the llseek() call, perhaps an indication that the 2.4 kernel still doesn't support large files. Do you know of anything else I could try? Is there any other way of manipulating large files on 32-bit Linux? Is there going to be a 64-bit Linux version anytime soon? Please help. Thanks!
-Albert
As you are aware Linux on 32-bit platforms (x86, SPARC/classic, PowerPC, MIPS, etc) using a signed 32 bit value for off_t (the type for expressing and return offsets for the lseek(), ftell(), and related system calls and library functions). You may know be aware that the off_t on 64 bit platforms (Alpha, UltraSPARC, IA64/Merced) is already set to 64 bits.
Clearly a signed 32 value can only express an offset up to about 2Gb (the negative offsets seek from backwards, either from the end of the file or the current file offset back towards the beginning of the file). This has led to Linux historical 2Gb file size limit on the most common platforms.
This 2Gb limit was common for UNIX on 32-bit. At some point a number of UNIX vendors (well, some engineers from the major UNIX vendors and some major database and other applications vendors) got together and held a "summit" to discuss some way to overcome this limitation and to agree on a reasonably portable interface so that the ISV (the independent software vendors) could write reasonably portable code to cope with this change. So the specification that they agreed upon has been called the LFS ("large file summit" or "large file support").
Linus used to say that anyone who needed to work with larger files really should migrate to Alpha or to Merced or some other 64 bit system. This was around the time that someone had submitted LFS patches to him. However, somewhere over the years since then he changed his mind.
I suspect that his change had a couple of elements (though I hate to second guess him; but I'd hate to waste his time asking about it, even worse). First, I think it became apparent that the need for large file support was growing much faster than the market for 64 bit systems. The 64-bit platforms haven't seen nearly the growth that Linux has; and the cheap availability of very large hard drives and RAID arrays as exacerbated that need (numbers and sizes of files send to grow larger as disk capacity make room for them; demand grows to exceed supply). The increasing use of Linux in imaging compute farms (Hollywood animation production) and for scientific clustering (Beowulf) --- and the continued preference for commodity PC/x86 hardware for those applications has also underscored the need for Linux to support LFS.
I suspect that another thing that helped influence Linus opinion on this is that I think someone submitted a different or cleaned up version of the LFS patches. I seem to recall that Linus didn't like the implementation of one of the early submissions --- so his rejection was on both grounds (implementation, the surmountable one, and perceived need/elegance --- a design judgement call).
Anyway, the 2.4 kernels do support LFS. Now you need to be able to actually compile software to use this support.
What you need to do is sit down and read the libc TexInfo pages (from a shell prompt issue the command 'info libc' or just 'info' or from within EMACS or Xemacs use the M-x info function; usually bound to [F1],[i] or C-h,i )
Here's an excerpt:
- Macro: _LARGEFILE_SOURCE
If this macro is defined some extra functions are available which
rectify a few shortcomings in all previous standards. More
concrete the functions `fseeko' and `ftello' are available.
Without these functions the difference between the ISO C interface
(`fseek', `ftell') and the low-level POSIX interface (`lseek')
would lead to problems.
This macro was introduced as part of the Large File Support
extension (LFS).
- Macro: _LARGEFILE64_SOURCE
If you define this macro an additional set of function gets
available which enables to use on 32 bit systems to use files of
sizes beyond the usual limit of 2GB. This interface is not
available if the system does not support files that large. On
systems where the natural file size limit is greater than 2GB
(i.e., on 64 bit systems) the new functions are identical to the
replaced functions.
The new functionality is made available by a new set of types and
functions which replace existing. The names of these new objects
contain `64' to indicate the intention, e.g., `off_t' vs.
`off64_t' and `fseeko' vs. `fseeko64'.
This macro was introduced as part of the Large File Support
extension (LFS). It is a transition interface for the time 64 bit
offsets are not generally used (see `_FILE_OFFSET_BITS').
- Macro: _FILE_OFFSET_BITS
This macro lets decide which file system interface shall be used,
one replacing the other. While `_LARGEFILE64_SOURCE' makes the
64 bit interface available as an additional interface
`_FILE_OFFSET_BITS' allows to use the 64 bit interface to replace
the old interface.
If `_FILE_OFFSET_BITS' is undefined or if it is defined to the
value `32' nothing changes. The 32 bit interface is used and
types like `off_t' have a size of 32 bits on 32 bit systems.
If the macro is defined to the value `64' the large file interface
replaces the old interface. I.e., the functions are not made
available under different names as `_LARGEFILE64_SOURCE' does.
Instead the old function names now reference the new functions,
e.g., a call to `fseeko' now indeed calls `fseeko64'.
This macro should only be selected if the system provides
mechanisms for handling large files. On 64 bit systems this macro
has no effect since the `*64' functions are identical to the
normal functions.
... this is in a discussion about "feature test macros" (allowing you to code up your #ifdef blocks). You may also need to define some macros to include support for the LFS functions and APIs.
You see in these excerpts hints about the FSF/Glibc maintainers view of LFS. They consider the adoption of LFS to be a three stage process; before and old/legacy code, transitional code that explicity calls the *64 functions, and finally a future where LFS is the default (controlled by a #define?) and there is optional support for the older interfaces.
Further evidence of this is seen in the following:
When the sources are compiling with `_FILE_OFFSET_BITS == 64' on a
32 bits machine this function is in fact `fopen64' since the LFS
interface replaces transparently the old interface.
(in a discussion on "Opening Streams" and the fopen() function).
There is a subtle gotchya in using the LFS support with some. That would be a bug. You should explicitly define
of the f* functions, especially fgetpos for example. Many people
would use off_t (or even long int!) for storing the return values
from fgetpos()
your variables for storing file positions as fpos_t (which is
defined as off_t or off64_t as appropriate to your system and the
#define settings in your sources.
That's why I say you should read the libc info pages. Be meticulous in following the prototypes that they offer for these functions.
There is a portion of these info pages which describes some of these problems and recommends that you use the fgetpos() and fsetpos() functions in preference to the ftell() and fseek() functions.
Which scanner and printer should I buy?From das due
Answered By Karl-Heinz Herrmann, Heather Stern
Help me please, I'm quite desesperate! I'm looking for a scanner and a printer that I can buy in french and which was supported by linux mandrake 7.2.
I'm not french but from Germany. I don't think the available hardware is that big a difference between France and Germany, but anyway I can't talk about the french market.
That said, I would suggest a look at:
http://www.linuxprinting.org
There you can look up any printer you found in shops and want to know it's status with Linux, or you look on the list by manufacturer to get a picture of whats working in Linux.
- A list of suggested printers (by the author of that website):
- http://www.linuxprinting.org/suggested.html
All printers supporting postscript Level 2 (or 3) will work right out of the box as long as the interface is supported with that particular printer -- USB could be a problem. Look at www.linux-usb.org for the actual status of USB and some specific printer.
Also most printing on non-postscript printers is done by ghostscript, a postscript interpreter available on all Linux distribution I know of. To see which printers are supported by ghostscript have a look at the printing adress above or ghostscript directly: http://www.cs.wisc.edu/~ghost (or www.ghostscript.org for news and links).
![]() Moreover if it can be in near than the price of the officejet G55 it will be mervelous!
Moreover if it can be in near than the price of the officejet G55 it will be mervelous!
- anyway, the status of the officejet G55 on:
- http://www.linuxprinting.org/show_printer.cgi?recnum=421842
is "partially supported" printing and scanning seems to work, so not in perfect quality.
I myself have a low cost Ink printer from Epson and since a little while a laser from Lexmark (postscript capable). I'm very happy with that one. Most lexmark printers know the PCL language as well, so the ghostscript print drivers for HP PCL printers usually work too.
One last advice maybe: Stay away from anything saying winprinter or GDI printer. These will most probably not work since you need a windows program as printer driver.
Seeing "Additional" MemoryFrom David L Revor
Answered By Jim Dennis, Bob Martin
I have two very old server (proliant 1500,4500). I know how to configure memory in lilo for earlier version of redhat, but 7.1 won't install and I am trying desperately to modify my boot disk to make it aware of the additional memory. Please help.
Thank You
David L Revor
Newer kernels incorporate better memory detection tricks, which work on most PCs. However, there are probably some systems on which automatic memory detection is still not reliable. So we still have the mem= option to the Linux kernel, so that we can specify the amount that we know we have. (This option is also handy for programmers and software QA people, for testing their applications in reduced memory situations without having to physically remove RAM from their systems).
Domain Renaming and E-mail Routing and Re-writingFrom Peter Stilling
Answered By Jim Dennis
Mr. Dennis,
Currently our campus is making a domain change from ricks.edu to byui.edu We would like all of our email that is addressed to ricks.edu to be forwarded to the new byui.edu domain. Is there a way to do this with MX records some how?
Peter Stilling
This cannot be done with MX records (alone). It must be done by the MTAs (sendmail, qmail, postfix, exim, or whatever you want to use). The MX records will associate a list of preferences and destinations with an e-mail domain. Usually all but one of the MX destinations will be relays (your ISP, a couple of your well-connected and reasonably trustworthy friends or "partners"). Those will all contain higher precedence values (meaning "less preferred") so any proper SMTP MTA which attempts to deliver mail to that domain will ignore all the secondary/tertiary MX hosts and attempt to contact the (usually one) with the lowest precedence. (The others are for "fallback" when the preferred destination is unreachable).
So with MX records you can say that mail to ricks.edu should be delivered to a machine (hostname) which is in the byui.edu domain. Note that you MUST use a hostname and not a "CNAME" or alias and not an IP address. Of course the hostname must be listed in some valid DNS zone which provides one or more A (address) records for it.
Let's say that you choose to deliver all ricks.edu mail to rexburgmx.byui.edu. Publishing a set of MX records like:
ricks.edu. IN MX 10 rexburgmx.byui.edu.
IN MX 20 mx.byui.edu.
IN MX 30 mail.backbone.not.
rexburg.byui.edu. IN MX 10 rexburgmx.byui.edu.
rexburgmx.byui.edu. IN A 123.45.67.89
... would serve to get mail delivered to the machine at 123.45.67.89
(Any host that couldn't reach that machine would try to drop it on
mx.byui.edu and thence on mail.backbone.not (Note the bogus top-level domain here --- it's for example only!). Those secondary MX destinations should be configured to relay mail to your primary host. (It used to be allowed by default in sendmail and most other MTAs --- however the spammers exploited this courtesy and laissez faire approach and have increased the burden on sysadmins and postmasters everywhere).
Now the host named rexburgmx.byui.edu would have to be configured to consider itself the mail destination for the ricks.edu mail domain. In sendmail terms we'd have to add ricks.edu to the "who am I" class (Cw) or file/list (Fw). In qmail we'd put this in the locals or the me control file. In Postfix we'd add it do the "mydestination" list (or keyed/database file).
Unfortunately that approach, by itself might lead to some oddities. Outgoing mail from this system might end up with headers and envelope "From" addresses set to the byui.edu domain, or some rexburg.byui.edu subdomain. (In the worst case they'd end up with the hostname as their from address). In sendmail terms they might be "masqueraded as" being from byui.edu.
Here's where we get complicated. You have to make some policy decisions about how you want mail headers to look at mail goes out of your domain. This will effect how replies get routed back to you. There is no "right way" to do it. There are many possibilities and pros and cons to each.
Perhaps all you want is a simple transitional delivery mechanism. Perhaps all new addresses will be in the rexburg.byui.edu domain or even directly in the byui.edu domain or in various departmental subdomains under byui.edu --- sci. (or science students and faculty), cs (computer science), adm, admin or staff (for administrative staff) etc. Perhaps you intend to move all the old accounts and e-mail addresses to new ones (or you've already done so and resolves any name collisions that arose).
In those cases the ricks.edu e-mail domain exists purely so that mail to the old addresses gets delivered to the proper recipients. All responses to can reasonably have a From: address of or possibly even (where the mail was re-written through some form of aliasing, perhaps to resolve a name collision between Mr. Foo at byui.edu and Ms. Frances Oo (no relation) at ricks.edu).
Thost are the sorts of things that make this sort of transition "interesting." Corporate mergers and aquisitions make it a fairly common occurence; which doesn't make it any easier. Unfortunately I can't describe a simple procedure for you to follow. There are too many variables.
As implied by my title, here: renaming your e-mail domain has two distinct aspects; routing the incoming mail to its recipients (mailboxes) and generating/re-writing headers on outbound mail so that responses can make it back to their authors.
Have fun. You're in for a learning experience.
MySQL tips and tricksFrom Travis Gerspacher
Answered By Mike Orr, Karl-Heinz Herrmann
Yes, Gentle Readers, this is also in the Wanted area this month, because expanding it into a more complete article would be very tasty. Meanwhile we hope it's useful as it stands, and there's some extra URLs at the end. -- Heather
![]() I would love to see an article about making sense of MySQL.Perhaps some basic commands, and how to do something useful with it.
I would love to see an article about making sense of MySQL.Perhaps some basic commands, and how to do something useful with it.
![]() I have found a lot of articles either lack basic usage and administration or it it fails to show how to put it all together and have somehing useful come out of it.
I have found a lot of articles either lack basic usage and administration or it it fails to show how to put it all together and have somehing useful come out of it.
$ mysql test Reading table information for completion of table and column names You can turn off this feature to get a quicker startup with -A Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 1325 to server version: 3.23.35-log Type 'help;' or '\h' for help. Type '\c' to clear the buffer mysql> show tables; +------------------+ | Tables_in_test | +------------------+ | COLORS | | TEAM | +------------------+ 2 rows in set (0.00 sec) mysql> describe TEAM; +------------+---------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +------------+---------------+------+-----+---------+----------------+ | MEMBER_ID | int(11) | | PRI | NULL | auto_increment | | FIRST_NAME | varchar(32) | | | | | | LAST_NAME | varchar(32) | | | | | | REMARK | varchar(64) | | | | | | FAV_COLOR | varchar(32) | | MUL | | | | LAST_DATE | timestamp(14) | YES | MUL | NULL | | | OPEN_DATE | timestamp(14) | YES | MUL | NULL | | +------------+---------------+------+-----+---------+----------------+ 7 rows in set (0.00 sec) mysql> select count(*) from TEAM; +----------+ | count(*) | +----------+ | 4 | +----------+ 1 row in set (0.00 sec) mysql> select MEMBER_ID, REMARK, LAST_DATE from TEAM; +-----------+-----------------+----------------+ | MEMBER_ID | REMARK | LAST_DATE | +-----------+-----------------+----------------+ | 1 | Techno Needy | 20000508105403 | | 2 | Meticulous Nick | 20000508105403 | | 3 | The Data Diva | 20000508105403 | | 4 | The Logic Bunny | 20000508105403 | +-----------+-----------------+----------------+ 4 rows in set (0.01 sec)
Say we've forgotten the full name of that Diva person:
mysql> select MEMBER_ID, FIRST_NAME, LAST_NAME, REMARK -> from TEAM -> where REMARK LIKE "%Diva%"; +-----------+------------+-----------+---------------+ | MEMBER_ID | FIRST_NAME | LAST_NAME | REMARK | +-----------+------------+-----------+---------------+ | 3 | Brittney | McChristy | The Data Diva | +-----------+------------+-----------+---------------+ 1 row in set (0.01 sec)
What if Brittney McChristy changes her last name to Spears?
mysql> update TEAM set LAST_NAME='Spears' WHERE MEMBER_ID=3; Query OK, 1 row affected (0.01 sec) mysql> select MEMBER_ID, FIRST_NAME, LAST_NAME, LAST_DATE from TEAM -> where MEMBER_ID=3; +-----------+------------+-----------+----------------+ | MEMBER_ID | FIRST_NAME | LAST_NAME | LAST_DATE | +-----------+------------+-----------+----------------+ | 3 | Brittney | Spears | 20010515134528 | +-----------+------------+-----------+----------------+ 1 row in set (0.00 sec)
Since LAST_DATE is the first TIMESTAMP field in the table, it's automatically reset to the current time whenever you make a change.
Now let's look at all the players whose favorite color is blue, listing the most recently-changed one first.
mysql> select MEMBER_ID, FIRST_NAME, LAST_NAME, FAV_COLOR, LAST_DATE from TEAM -> where FAV_COLOR = 'blue' -> order by LAST_DATE desc; +-----------+------------+-----------+-----------+----------------+ | MEMBER_ID | FIRST_NAME | LAST_NAME | FAV_COLOR | LAST_DATE | +-----------+------------+-----------+-----------+----------------+ | 3 | Brittney | Spears | blue | 20010515134528 | | 2 | Nick | Borders | blue | 20000508105403 | +-----------+------------+-----------+-----------+----------------+ 2 rows in set (0.00 sec)
Now let's create a table TEAM2 with a similar structure as TEAM.
mysql> create table TEAM2 ( -> MEMBER_ID int(11) not null auto_increment primary key, -> FIRST_NAME varchar(32) not null, -> LAST_NAME varchar(32) not null, -> REMARK varchar(64) not null, -> FAV_COLOR varchar(32) not null, -> LAST_DATE timestamp, -> OPEN_DATE timestamp); Query OK, 0 rows affected (0.01 sec) mysql> describe TEAM2; +------------+---------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +------------+---------------+------+-----+---------+----------------+ | MEMBER_ID | int(11) | | PRI | NULL | auto_increment | | FIRST_NAME | varchar(32) | | | | | | LAST_NAME | varchar(32) | | | | | | REMARK | varchar(64) | | | | | | FAV_COLOR | varchar(32) | | | | | | LAST_DATE | timestamp(14) | YES | | NULL | | | OPEN_DATE | timestamp(14) | YES | | NULL | | +------------+---------------+------+-----+---------+----------------+ 7 rows in set (0.00 sec)
Compare this with the TEAM decription above. They are identical (except for the multiple index we didn't create because this is a "simple" example).
Now, say you want to do a query in Python:
$ python
Python 1.6 (#1, Sep 5 2000, 17:46:48) [GCC 2.7.2.3] on linux2
Copyright (c) 1995-2000 Corporation for National Research Initiatives.
All Rights Reserved.
Copyright (c) 1991-1995 Stichting Mathematisch Centrum, Amsterdam.
All Rights Reserved.
>>> import MySQLdb
>>> conn = MySQLdb.connect(host='localhost', user='me', passwd='mypw', db='test')
>>> c = conn.cursor()
>>> c.execute("select MEMBER_ID, FIRST_NAME, LAST_NAME from TEAM")
4L
>>> records = c.fetchall()
>>> import pprint
>>> pprint.pprint(records)
((1L, 'Brad', 'Stec'),
(2L, 'Nick', 'Borders'),
(3L, 'Brittney', 'Spears'),
(4L, 'Fuzzy', 'Logic'))
Another approach is to have Python or a shell script write the SQL commands to a file and then run 'mysql' with its standard input coming from the file. Or in a shell script, pipe the command into mysql:
$ echo "select REMARK from TEAM" | mysql -t test +-----------------+ | REMARK | +-----------------+ | Techno Needy | | Meticulous Nick | | The Data Diva | | The Logic Bunny | +-----------------+
(The -t option tells MySQL to draw the table decorations even though it's running in batch mode. Add your MySQL username and password if requred.)
'mysqldump' prints a set of SQL commands which can recreate a table. This provides a simple way to backup and restore:
$ mysqldump --opt -u Username -pPassword test TEAM >/backups/team.sql $ mysql -u Username -pPassword test </backups/team.sql
This can be used for system backups, or for ad-hoc backups while you're designing an application or doing complex edits. (And it saves your butt if you accidentally forget the WHERE clause in an UPDATE statement and end up changing all records instead of just one!)
You can also do system backups by rsyncing or tarring the /var/lib/mysql/ directory. However, you run the risk that a table may be in the middle of an update. MySQL does have a command "LOCK TABLES the_table READ", but interspersing it with backup commands in Python/Perl/whatever is less convenient than mysqldump, and trying to do it in a shell script without running mysql as a coprocess is pretty difficult.
The only other maintenance operation is creating users and assigning access privileges. Study "GRANT and REVOKE syntax" (section 7.25) in the MySQL reference manual. I always have to reread this whenever I add a database. Generally you want a command like:
mysql> grant SELECT, INSERT, DELETE, UPDATE on test.TEAM to somebody -> identified by 'her_password'; Query OK, 0 rows affected (0.03 sec)
This will allow "somebody" to view and modify records but not to change the table structure. (I always alter tables as the MySQL root user.) To allow viewing and modifying of all current and future tables in datbase 'test', use "on test.*". To allow certain users access without a password, omit the "identified by 'her_password'" portion. To limit access according to the client's hostname, use 'to somebody@"%.mysite.com"'.
Remember that MySQL usernames have no relationship to login usernames.
To join multiple tables (MySQL is a "relational" DBMS after all), see "SELECT syntax" (section 7.11). Actually, all of chapter 7 is good to have around for reference. The MySQL manual is at http://www.mysql.com/doc/
- They put their articles of past issues online:
- http://www.linux-magazin.de
http://www.linux-magazin.de/ausgabe/2001/04/index.html
http://www.linux-magazin.de/ausgabe/2001/04/PostgresMySQL/postgres-mysql.html
Maybe this is at least interesting for German speaking readers....
http://fets3.freetranslation.com:5081/
?Language=German%2FEnglish&Url=http%3A%2F%2Fwww.linux-magazin.de
%2Fausgabe%2F2001%2F04%2FPostgresMySQL%2Fpostgres-mysql.html&Sequence=core
Postgres' Foreign keys come out as "strange keys". In a sentance about transactions it says, "With the MVCC-procedure, readers do not wait for clerk".
The funniest quote is: "Like in almost all professional databank systems Trigger and Stored Procedures are confessed. Implementiert is not presently on the other hand the possibility, databank to replizieren."
Or maybe this is better, "To the Performance-increase, data models denormalisiert become frequent."
MySQL's origin "lies loudly in the 1979 databank-Tool UNIREG". Oh, and "the official pronunciation is Mei-it-kju-ell. People who say 'Mei Sequel' are pursued however not criminal."
Adding a new hard drive to a running system.From Roy Bettle
Answered By Mike Orr
Here I was, all smart and all ... Got RH7.1 running fine, then decided I needed more drive space. So I added a new drive. Now what? I used "fdisk" as root to create a partition on it, but how do I "format"? I tried "mkextfs", "mkext2fs", "make ext2 /dev/hdb", etc., after my experiences using "mkreiserfs" earlier, but all my "ext2" attempts were in vain.
mkfs -t ext2 /dev/hdb1
or:
mke2fs /dev/hdb1
Note: /dev/hdb1, not /dev/hdb. For hard disks, you format a partition, not the entire drive.
See the manpages for additional command-line options. I would especially use the -c option to check for bad blocks, since you are using a drive of unknown quality.
(For additional trivia, /sbin/mkfs.ext2 is a hardlink to /sbin/mke2fs.)
(Additional trivia: to format a floppy disk that has never been formatted, run 'superformat'. This creates a dos/vfat filesystem as a side effect. If you wish a different filesystem type, run mkfs after superformatting. The device in this case is /dev/hda since floppies don't have partitions.
![]() Also, to mount it (because I tried "mount -t ext2 /dev/hdb /mnt/tmp", etc.) do I just edit "/etc/fstab" and add the mount point or is there an additional step, possibly during the formatting stage? I tried the above line but was told the mount point didn't exist.
Also, to mount it (because I tried "mount -t ext2 /dev/hdb /mnt/tmp", etc.) do I just edit "/etc/fstab" and add the mount point or is there an additional step, possibly during the formatting stage? I tried the above line but was told the mount point didn't exist.
You can run 'mount' and 'umount' to mount and unmount the partition whenever you need it, or add a line in /etc/fstab to have it mount automatically at boot time. There is no additional step. See "man mount" and "man 5 fstab".
[big abubble]
![]() You "da bomb"! Thanks!
You "da bomb"! Thanks! ![]()
RAB
Roy Bettle
LINUX FOR THE PRODUCTION ENVIROMENTFrom Martin Sapola
Answered By Mike Orr
Hi
I don't if you are the right person to help me but the following is my request;
I embarking on a project to build entry level servers running linux (Caldera eserver) for file/printer sharing, internet access and database applications. The applications I would like to use are as follows;
I will appreciate your advice.
Except perhaps for Sql-ledger. I'm not sure what that is. Is it a specific class of applications different from an ordinary SQL server? Do you know of a product running on Linux which does Sql-ledger? Or what kinds of accounting programs would be acceptable in its place?
The Answer Gang can answer short, specific questions that would be of interest to a significant portion of our readership. (All questions and answers are considered for publication, although you can be anonymous if you request.) However, if it's a large, general question like "help me design my office network" or "help me write an application which does this", we would steer you to the Linux documentation and to paid consultants.
RE: Question: special keysFrom Helmut Heidegger
Answered By Karl-Heinz Herrmann
I would like to use the special keys on my Microsoft Natural Keyboard Pro under Linux. I have already found the keycodes (I think it was xevt), but I haven't been able to define a program for a key, e.g. the standby button starts xlock, the e-mail button starts kmail, volume + and - enables kmix and changes the volume, and so on.
For example I've set the "print" scroll" "pause" buttons to "front" back" "iconify" functionality. (doesn't even need .Xmodmap since the keys already produce keysymbols "print" "Scroll_Lock" and "pause").
If you want to use the Winkeys add something like to your .Xmodmap:
keycode 0x75 = Menu ! (is the menu key here)
then run:
xmodmap .Xmodmap
to read in the new settings.
But now the next problem: If your window manager does not know these keysymbols and what to do on key press, nothing will happen. I use the fvwm2 windowmanager here and I can set it in .fvwm2rc by something like:
Key Print A N Raise Key Scroll_Lock A N Lower Key Pause A N Iconify
for the front, back, iconify
Key Delete A CM Exec exec xlock -modelist "matrix"
will start the screen saver on Ctrl-Alt-Del
If you use kde or whatever windowmanager you will have to figure out how to define these key actions. The manual page of the windowmanager would be a good starting point.
Operation Not Permitted on SUID ProgramFrom Dann S. Washko
Answered By Karl-Heinz Herrmann, Jim Dennis
The permissions on a file like /usr/X11R6/bin/xterm are: rws--x--x which means the userid bit is set on execution so the process runs as root.
You can write a very simple C wrapper program like:
*** WARNING, THIS SCRIPT HAS RISKY BUGS ***
#include <unistd.h>
int main (int argc, char ** argv) {
int err;
char *newenv[] = { NULL };
if ((err = execle("/usr/bin/pauseme", "pauseme", NULL, newenv)) < 0 ) {
exit(err);
}
return 0; // never reached!
}
*** risky *** risky *** risky *** risky *** risky ***
This uses one of the exec*() family of system calls, specifically the "varargs" forms with a pointer to a new environment. We don't use the system() or popen() library calls and we don't use any of the forms of exec*() that search the path nor those that retain the user's environment. These are all potentially exploitable bugs for SUID programs. So we have to use execve() or execle() to be reasonably secure. Additionally, I should have written a loop like:
{ int x; for (x = 0; x < 255; x++) close(x); }
To explicitly close all of my non-standard file descriptors (there are some exploits possible when exec()'ing programs with additional open files, becuase those persist through the system call).
Then I have to explicitly re-open the files or devices that I want my program to use.
These and, alot of other considerations depend on the exact program that is being invoked. For example, if your "pauseme" program might have vulnerable signal handling, than your wrapper program might have to do a setsid() and a fork() to detach signal propagation from the user's shell's process group.
Most importantly you'll have to do your own parsing and validation of any variable arguments and options that you want to allow the user of your script to set. If those involve filenames, you'll have to check those for access under the real UID (as opposed to the "effective" UID which is set by the ownership of the wrapper binary). File paths where any component of the patch is writable by a potentially hostile user are subject to race conditions if you attempt to check the ownership and permissions prior to opening it. (Generally you have to perform go through an lstat(), save the device/inode pair, then do your open() and use the fstat(), compare its device/inode the the one you stored, and then perform your permissions and ownership checks).
In other words, there are many "gotchyas" to writing C wrappers. Writing robust, non-exploitable C is difficult and there are whole books on the topic.
![]() Why is it then, if I create a script:
Why is it then, if I create a script:
#!/bin/bash pauseme
and give it the same permissions: rws--x--x
I get an error that the operation is not allowed if I try to execute the file as a non-superuser?
A shell script needs an interpreter. Since your /usr/bin/bash or whatever is most probably non SUID root it refuses (or simply can't change to SUID root) to run a script in SUID root. You as User are effectively running /usr/bin/bash on the script. So if /usr/bin/bash is not SUID it will run with your permissions and can't change to any other user.
It seems most *NIX OS'es share the opinion that shell scripts are that unsafe that they can't be allowed to run as SUID root, so simply setting SUID on the script won't be enough. It's even recommended that /bin/true (or /bin/false) be not shell scripts with "exit(0)" but instead little compiled C programs.
It is widely considered to be almost impossible to write a sufficiently robust shell script that it could be trusted to run SUID. Therefore the kernel's policy of ignoring the SUID/SGID bits persists.
You'd install sudo, and configure it to run your command by using the 'visudo' command to edit the /etc/sudoers file. You could optionally specify the NOPASSWD option to allow a user or group of users to unconditionally access a command without needing to supply their password. sudo has been used by lots of sysadmins (it's more popular than any similar package like super or calife) for many years. There have been no critical bugs posted for it to my memory and only a couple of minor bugs (affecting uncommon configurations).
Here's a sample sudoers file:
# sudoers file. # This file MUST be edited with the 'visudo' command as root. # See the man page for details on how to write a sudoers file. Defaults shell_noargs, set_home %staff ALL=NOPASSWD:/bin/vi /etc/motd
In this example members of the "staff" group on "ALL" systems to which we distribute this sudoers file, can use vi to edit the /etc/motd (Message Of The Day) file, without using their password.
The thing that I always get into trouble with, when I'm making new sudoers entries is that part of about specifying which hosts this entry applies to. Normally I use use ALL=, since I tend to have quite limited sudoers lists, and therefore I have homogenous user/privilege matrices. NOTE: sudo isn't actually doing anything over the network, it isn't a remote access client/server or anything like that. This "host specification" feature of their sudoers file is purely to allow an admin to maintain one sudoers file and to distribute it (via some reasonably secure means, such as rsync over ssh) to all of their hosts.
If I were specifying hostnames or netgroups here, then the copy of sudo that I ran on mars.starshine.org would filter out all of the sudoer entries that didn't apply to mars.starshine.org and only consider giving me access to the commands that applied to my combination of user/group and host/netgroup.
The one disadvantage of using sudo is that your users have to remember to run "sudo ..." as part of their command. However, that's easy to work around by simply creating a wrapper shell script. This is a normal (non-SUID) shell script that simply does something like:
#!/bin/sh exec /usr/bin/sudo /some/path/to/our/target/prog "$@"
(execute sudo, on the target program and pass our argument, preserving any quoting as we specified it).
When sperl interprets a script, it performs many sanity checks. That makes it somewhat easier to write robust SUID perl scripts than SUID C wrappers. (Note, however, that sperl itself has had vulnerabilities; so questions of whether to install it on your system and which group(s) of users should be given access to the sperl binar(y|ies) do arise). There is a perlsec man page which focuses on the pitfalls and suggestions for writing robust Perl code.
You can read more than you want to know about secure programming for Linux and UNIX FAQs and HOWTOs at:
- Shmoo's Security Links:
- http://www.shmoo.com/securecode
- Secure Programming for Linux and Unix HOWTO
- http://www.linuxdoc.org/HOWTO/Secure-Programs-HOWTO/index.html
- Avoiding Security Holes when Developing an Application:
- http://www.linuxfocus.org/English/January2001/article182.meta.shtml
... and many others.
 More 2¢ Tips!
More 2¢ Tips! 2ct tip - making site icons for Konqueror
2ct tip - making site icons for KonquerorWhen you visit some sites with Konqueror, the icon in the upper left corner and the icon in the location window will sometimes become the logo for the site. You can add your own with the KDE icon editor.
Just create a 16x16 PNG file and save it in $HOME/.kde/share/icons/favicons
as <domain name>.png. For example, I created a "G" logo for visiting i the www.packers.com site. I saved my icon as "www.packers.com.png."
Jim
getting 2 dynamic ip addressesHi,
regarding your recent answer to [subj]:
[Mike] Your hub is connected directly to the DSL modem? In that case, you will have to contact your ISP to get a second dynamic address from them... if you can. A more common scenario is to have one computer (the server) connected to the modem and also to the hub. The second computer is connected only to the hub.
Not widely known is this alternative (assuming that pppoe is used):
This solution has two advantages:
There are of course also drawbacks:
Let me also point you to http://www.fli4l.de, a linux router project called "Floppy ISDN for Linux" which also supports DSL. It is a great solution for most router needs and very easy to configure. You don't even need a Linux box to install/configure it since it comes with tools for Windows / DOS as well. All you do is use the Windows based configuration program or a text editor to adjust a configuration file, run a script / batch file to create a boot floppy and boot from it. I have discovered it a month ago and switched my old SuSE based router to this one immediately.
Unfortunately the documentation is so far mostly German, but they are working on an English translation.
regards
Thomas
Mouse port Problem ?Hi,
I am having Ps/2 mouse . my startx is fine but i dont see any mouse movements . i tried attaching different mouse but the result is the same. can u help me how to make out whether its a problem of mouseport .
Regards
Anil
Hi,
Firstly you need to know on what port X is looking for a mouse and then make sure that this device actually exists and is supported by the kernel.
In /etc/XF86Config you should find a section called "Pointer" mine reads as follows.
Section "Pointer" Protocol "PS/2" Device "/dev/mouse"
/dev/mouse is a symbolic link to /dev/psaux.
Hope this will help.
Kind regards
Andrew Higgs
Anyone burning a CD should know...Hi,
I'd like to respond to a question in the April MailBag about burning .iso cd images from Windows.
When downloading an .iso image off the internet there are several steps involved. One should of course download the image and burn it to a CD. However there is a step in the middle that is even more important...getting an MD5 checksum against the resulting file.
Most sites that allow you to download an .iso file also have a matching MD5SUM file that goes with the .iso file. Go ahead and download that too. It is a very small file and is basically your insurance against making coasters (an invalid CDRom disc ).
The file really contains an MD5 digest of the .iso file. It is in ascii text and is viewable with notepad in Windows. What is an MD5 digest you ask...it is a 128-bit digital fingerprint of the file. If you want to know more you can read the spec for the algorithm at: http://theory.lcs.mit.edu/~rivest/rfc1321.txt
Because you require a way to get the MD5 digest of a file from a windows perspective, you'll need a WIN32 app that can run the digest. This utility can be picked up at: http://www.etree.org/cgi-bin/counter.cgi/software/md5sum.exe
Save it to C:\WINDOWS. Just invoke it in a dos window with the following command line (replacing the .iso filename with the name of the .iso that you downloaded).
md5sum -b myimage.iso
It's gonna run for a while....ok probably 10 minutes or so...be patient. The utility will then spit out something like: 379d89e83825d11d985b1081ab0de6de *myimage.iso
Now look at the the the number stored in the MD5SUM file that you downloaded for the .iso file. If they match, you have my approval to go for the burn...if not...try again.
There are also some low cost methods of getting the CD for just about any linux distribution like http://www.cheapbytes.com or http://www.linuxmall.com these both will do all the dirty work, including checking for valid .iso and burning it properly, for around a 5-spot.
-Raini Hixon
Slackware UpgradeRe: the tips and tricks page of the April (issue 65) question, Slackware upgrade
Reply from Jim Vanns
Awkwardly enough I have also written a program called slakup!! It's on freshmeat so go to http://freshmeat.net/projects/slakup and take a look at it. I think it'll do roughly what you want - you can search for individual packages install them resume the download (if you're disconnected for some reason) and even download and install entire directories.... I hope this helps...
Regards
Jim
Dump considered harmfulWhy 'dump' is not a safe backup tool for Linux. Short Linux Weekly News article with a quote from Linus.
-Mike
RE: Device Drivers for Linux GazetteHi, Linux.com have put an article up about writing a Device Driver which sounds like it could be just the thing asked for.
Yours
Matthew Waddilove
Linux Device DriverI'm a candidate for the doctor's degree on electronic. I'm working on a DSP and data adquisition card for ISA bus (as begin). I wrote a device driver for Linux (a file .o), and then make a special file in /dev directory with mknod; However, I don't know if I have to re-compile the kernel for associate my special file with my device drive ( any.o ). My questions are:
Which are the steps for make a device drive and install it? And then, Which are the steps for redistribute it? Where can I get more information? . Thanks a lot by anyway.
Hiya!
I've written a couple of Linux device drivers, and I found most of the information I needed in one of these two locations:
The first is a paperback book giving all the gory details of how device drivers work under Linux, including how to write them as modules so that the kernel can dynamically load and unload them as needed (this saves recompiling the kernel all the time). The book is based around kernel version 2.0, but includes lots of pointers for 2.2. I guess a new version for the 2.4 kernels will come along soon.
The second, web reference is a more general guide to writing modules, and may be slightly less useful to you.
The third place I looked for help was in the kernel source tree: lots of skilled programmers have written lots of device drivers and made the source available to you. Pick one or two modules that drive similar hardware to your device and read the code thoroughly.
Hope it helps!
Mike.
PLWMThis should spark some interest in some quarters (Hi Dan):
From PLWM's info page:
plwm is not a normal window manager, in fact, it isn't a window manager at all. Instead it is a collection of Python classes which you can use to build your own window manager. You can include the features you like and easily write your own extensions to make your plwm behave exactly as you want it to. Eventually, you will have a perfect symbiosis of user and window manager, you and the computer will be a beautiful Mensch-Maschine!
One basic idea is that the mouse should be banished, and everything should be possible to do without moving your hands from the keyboard. This is the pointless bit of plwm.
The other basic idea is to make a window manager which is is pure Unix Philosophy: a lot of simple tools you combine to make a powerful application. The "tools" are Python classes which makes it easy to inherit, extend, mixin and override to get exactly the functionality you want.
This makes plwm extremely configurable by sacrificing ease of configuration: you actually have to write some Python code to get the window manager exactly as you want it. However, if you was moved by the first paragraph, then you're probably already a hacker and will relish writing your own window manager.
A typical plwm might look rudimentary, even hostile, to people used to the glitz and glamour of more conventional window managers. However, there are a lot of powerfull features, making it really user-friendly. Provided that the user is friendly to plwm, of course.
-- Mike
Terminaal access in Un*xCommenting on http://www.linuxgazette.com/issue65/tag/23.html
Could I suggest you point this person at "The POSIX programmer's guide" (ORA, ISBN 0-937175-73-0, Donald Levine)? In particular chapter 8 describes the tc* functions, including stuff like break handling, parity generation, cooked mode, turn echo on or off, etc, etc. You can do a few more things with termios but not many and termios is a bit less portable. I think termios is quite well documented in the GNU C library manual.
I suspect the same reference will answer a lot of the other questions that this breed of program raises. Incidently just coyping the header file is unliekly to work, it just delies the problems until link time. Depending on the progrm curses/ncurses might or might not be the right thing, and it is not possibe to judge this sans the program in question.
Configuring alternate window managers.Hi,
Hello,
I have recently installed RHL6.2 on my machine. The default window manager for this is Gnome. Being more familiar with fvwm2 and olvwm, I would like to know if there is any way of making these window managers available at the login time.
If it is not possible to have these WM listed under "sessions", is there any way by which as soon as I log in, fvwm2/olvwm will start instead of Gnome?
If you go into /etc/X11/gdm, you'll see a Sessions/ directory. Inside of there, you'll see scripts that launch different WMs. Add scripts for the WMs you want to launch and they'll show up automagically when you reboot.
Regards,
Faber Fedor, RHCE, SCSA, MCSE, MCT, UVW, XYZ
Hello,
Thanks for the tip. That solved my 90% of the problem. But I figured out that there is something additional that needs to be done to get the window managers running. I had to edit /usr/X11R6/bin/RunWM and add entries for the new window managers. I don't know if this change is required only for my machine or is a generic one.
Thanks, Atul/10.May.2001
stubborn mount errorRegarding http://www.linuxgazette.com/issue65/tag/27.html
Hello,
After reading the Answer Gang article in the above URL of your Linux Gazette, I realised that I had this similar problem. My problem may or may not be related.
I see that Gabriel Florit was using RH7 with some updates installed from up2date. I ran this recently on RH7 and had some problems mounting vfat partitions afterwards. I believe, based on the list of packages that were installed, that this was due to a new version of mount being installed. There were new kernel sources with these round of updates. Until I recompiled the kernel using this new source, mount would give the same error message as Gabriel is experiencing, every time. Then, after compiling the new kernel with the new source, the problem was gone.
Apolgies not being about to tell you exactly which kernel was replaced by which, I am on a work machine at the moment and have upgraded to the 2.4 kernel under RH7.1 now anyways, but I may be able to find out if I didn't delete the old sources.
Hope this helps,
D.
Shutdown, RebootI would like to be able to allow other users to do a shutdown, or to create a special user who can be used to poweroff the system. I am not concerned about anyone turning the system off when I don't want it to happen, as there is not anything critical on the system (okay there is, but it is not a time critical type thing).
I can't just give my root password out so that someone can shut the system down......
To do a shutdown on ctrl-alt-delete, you can put this in /etc/inittab:
# What to do when CTRL-ALT-DEL is pressed. ca:12345:ctrlaltdel:/sbin/shutdown -h now
(Most distributions make it a shutdown -r but you can make it a shutdown -h.)
Or, install sudo, make a group "shutdown" and put something like this in /etc/sudoers:
%shutdown ALL = NOPASSWD: /sbin/shutdown
Then other users will be able to shutdown with
sudo /sbin/shutdown -h now
The advantage of the second approach is that sudo will log who did it.
-- Don Marti
How to create entries under /dev directory ?Hi All:
How to create entries under /dev direcory on linux ( SuSE 7.1 )? RedHat linux has a script /dev/MAKEDEV which can be used for this. I looked at /etc/init.d/* scripts on SuSE linux7.1 installation CD but couldn't find how it creates entries under /dev directory. I want to create entries for all the devices manually. If SuSE7.1 already have some script like MAKEDEV will be quite helpful.
Thanks
Sachin
You create device files with the mknod command. The major and minor numbers for devices can be found in the kernel source documenation directory in devices.txt
-- Bob Martin
relay webcam (axis) proxyHi,
I got a problem! ![]() You might probably thought that already!
You might probably thought that already!
I got several network cameras in our office (axis 2100 with own flash linux and webserver which already builds a multipart/jpeg). Due to a lack of bandwidth I want to relay the streams the cams generate to our webserver which got a MUCH bigger bandwidth avaliable.
I want that every camera only pushes the stream once though our line and the server relays it to every client how wants to see the stream.
Client-------|
|
|
Client-------|
|
|------------ Server -------------- Cam
|
Client-------|
|
|
Client-------|
|
|
...----------|
Do you know about a proxy project that does something like that? I am not a C guru but I am surviving. ![]() Maybe you got another solution for this problem (or maybe the community will
Maybe you got another solution for this problem (or maybe the community will ![]() )
)
Thanks in advance!
Heiko
-- Don Marti
RE: help. making my new linux box a server for winNTOn 15-May-01 Juan Pablo L. wrote:
hello,
i have just found many anserws at linuxdoc and i really thing u do a
great job, i dont know if this is the way to ask but i have been looking all over the net a little explanation on how to make a my linux box a server for my other home computers running winNT. If you answer me i would like you to cever things such as how to configure the server it self and how to configure the clients (running winNT). I m planning to do it with a hub and some network cards. TIA! =)
Have a look at Samba: Thats a server running running on *NIX and allows to connect Windows clients to it for file and printersharing.
or simply type samba in any search engine (like www.google.com). The Samba home page is: http://samba.org
You will wan't to run the snmb server for the actual exporting and nmbd who is handling the Windows query protocoll -- so the Linux box will answer if you doubleclick "network" in Windows and scan the environment.
K.-H.
tell me how to configure this new samba in easy steps .Dear friends :
recently i installed Samba server 2.2 on redhat linux 7.0.1 i face big problem connecting from windows to that linux box is there any way to tell me how to configure this new samba in easy steps .
thanks
-- Essam Mohsin
There are some GUI tools for it, but they still somewhat expect that you know what you want. Unless somebody has changed your setup, most distros' copy of samba contains a sample smb.conf (try looking in /etc or using locate to find it) with comments for all the options.
Other than that, the best step-by-step I know, though it's not "down to the bits" would be samba's own DIAGNOSIS.TXT file. I've configured a lot of samba boxes. So far I haven't seen a single problem that wasn't solved by going through this from beginning to end. It has 11 tests and it's over 300 lines long, in the version I've got.
The Samba site has many mirrors, but you can at least find their docs online at ftp://ftp.samba.org/pub/samba/docs -- there is a lot of good reading in there.
We also had an article in issue 48 (http://www.linuxgazette.com/issue48/blanchard.html) about setting up Samba, which you might find useful.
Deleted pager panel in GnomeDon Pollitt wrote:
How do I restore my pager panel in GNome. I inadvertently deleted it?
IIRC, if you delete the directory ~/.gnome and restart GNOME, everything will re-appear (except, of course) for your personalized settings.
-- Faber Fedor
Ouch!
I think it's better to run
$ /usr/bin/panel&
to bring the panel back, and then select
Settings/Session/Save Current Session
from the Gnome menu.
-- Breen Mullins
Expect script fails to 'Expect'....Chris Skardon wrote:
Hi,
Hello!
expect "Login:" send "csk\r" expect "word:" send "<PASSWORD>\r"
The problem that I have is that it doesn't wait for 'Login:' to appear before it types the username to the screen, so the output would be something along the lines of:
Well, two things come to mind: every script I've ever seen (except for yours ![]() looks for "ogin:" and not "Login:". You may want to do that as well, since every box you telnet to may not use a capital L for the word login (my other linux boxes don't).
looks for "ogin:" and not "Login:". You may want to do that as well, since every box you telnet to may not use a capital L for the word login (my other linux boxes don't).
spawn telnet hawk Trying <IP ADDRESS> Connected to hawk Escape character is '^]' csk Login: <PASSWORD> Password:
But, based on this output, what I said above won't help. So here, I would suggest putting another "expect" in before the "ogin:". Say, something like
expect "scape character" sleep 5 expect "word:"
or something along those lines.
HTH!
-- Regards, Faber Fedor
LPR alternativesHere's a couple, CUPS and PDQ.
What do you think of them? Is it worth switching from LPRng? -Mike
If someone out there writes up a good comparison, we'd be pleased to publish it in LG -- Heather
partitioner (was: Fatal Error from cfdisk)Back to the problem, though....I don't know what the underlying problem was but I seem to have fixed it by forking out $50 for partition magic which sorted it out. It would have been nice to have found someone who could've sorted it without the cost but there you go, I was in a hurry and couldn't find what I needed in all the reference and help info out there. I did look though, believe me(Sometimes there's just too much). Anyway, thanks for your reply; I'll try to phrase my question better next time.
Cheers, Peter.
We're a bit late for him, but if resizing a vfat or ext2 partition is something you need to do, try parted. It isn't as pretty (looks a bit like fdisk, really) but, it's in the major distros now and a cheap download from freshmeat or the debian archives if you don't have it. In this case, something unknown was funny about the partitions, and the corrective ability in resizers was able to fix it. -- Heather
I must also apologise about the lack of "depth" with this article. Things with school have been busier than I had expected!
Anyway, I think that I have rambled on long enough now. Enjoy........
From: Thomas Nyman
To: "Thomas Adam", <[email protected]>
Sent: Friday, May 04,2001 10:33 AM
Subject: Weekend mechanic
I like the "mechanic"
Two things that I would like to see explained are these.
1) If I install windows I may have a number of problems but never with my
monitor and graphical interface. Personally I have often experienced the
problem that I cannot get Xwindows to show on the screen monitor in a satisfactory
way, i.e its either way to big for my monitor or its way to small...I
have so far not found an easy to understand explanation on how to remedy such a
problem.
2) It would be "darn nifty" if you could put in a section on how to login via telnet
and run xwindows on another machine.
Anyway, thanks, and keep up the good work,
Thomas
[Thanks for your e-mail Thomas. As you can see, I have written an article about setting up monitors under Linux! -- Thomas Adam (The Weekend Mechanic)]
From: nomi To: "Thomas Adam", <[email protected]> Subject: Linux Weekend Mechanic Date: 12 May 2001 16:05 Hi, I read your article on LinuxGazette. Could you cover how to setup X, mainly the XF86Config file(s)? I'm a console guy and know what I need to know there, but when it comes to X (and editing it's settings)..I'm totally lost. Thanks. Syed N. Ahmad[Thank you for your e-mail, Syed. I have more or less done what you have suggested, except I might have gone into too much detail in some parts of X configuring and not in others....still, nevermind -- Thomas Adam (Linux Weekend Mechanic)]
From: Don Reid To: <[email protected]> Subject: shell aliases Date: 08 May 2001 21:21 Your article on "Customising the Shell Environment" has a lot of good info for people new to the command line. One point I would like to add is that you can get into a lot of trouble by aliasing over existing commands (rather than making up new names). If you run a script that uses one of these commands, your changes may alter the way it works. My preference is to retrain my fingers to type a new command. There are ways to restrict aliases to interactive shells, but those don't work for sources scripts. -- Don Reid[Don raises a very good point here, and one which I neglected to mention in my article. I shall just re-inforce that point by saying that, you should never ever have alias titles as commands, because if a program calls a bash builtin command, strange things can happen. Thanks for that Don. A valid point. -- Thomas Adam (Linux Weekend Mechanic)]
From: root To: <[email protected]> Subject: thank for the bash tip Date: 10 May 2001 13:24 I tried the tip about the shortcut in .bashrc. At first it did not work; meaning: I was recieving the no command found ect... So after a reboot, it work perfectly and made some other shortcuts that worked at the first time or trial. I wonder what will be next? and I waiting to see it. Thank you for your time Sylvain.[Umm, that is a strange problem, Sylvain, as to why you had to reboot your machine for those changes to take effect. By Sourcing the file, bash should have picked up those changes immediately. Still I am glad that it all works ok now. Best of luck -- Thomas Adam (Linux Weekend Mechanic)]
From: Paul Rowland To: <[email protected]> Subject: weekend mech Date: 02 May 2001 12:48 Dude, Your comments are totally in geekdom. You rule! Paul[Hello Paul, thank you for the vote of confidence. I am glad that you liked the article!! I also like the use of your language "geekdom". I have never heard that expression until now!! Regards -- Thomas Adam (Linux Weekend Mechanic)]
From: Josef Moffett To: <[email protected]> Subject: Your Cron bits and bobs Date: 08 May 2001 6:17 Hi there Thomas, I've been using Linux now for about 3 years, and recently (about a year ago now - time really flys when you're having fun ;-) installed debian on an old 486 at home to give me a masq box and firewall for my small home network. All my machines run linux at some point, but generally (mainly because I am a flightsim maniac - fly II is out now, woo hoo) still am tied to windows. I am dying for flight gear to come out a bit more stable so I can run it on Linux! Anyway, back the email (sorry about the ramble). I've been looking for more info about Cron for ages now. I use the linux box as a local mailserver and newserver (using leafnode). The pop3 server seems to work on its own - although I do have a few quirks. Of course for this, I've got to get it dialing in every now and then. So far what I've done is to hijack (quite blatantly) the standard once a day cron script (by the name, strangly enough of "standard" ;-) and tell it to dialup using pon with a provider script with a very short timeout (30 secs). In my ip-up script i then add fetchmail and fetchnews. It works, but of course doesn't do it more than once a day, and reading through man cron.d and the like, didn't really get me much further. I've always got some wierd error. (I can't remember what it was, I think about permissions - despite using it as root, but not serious). Added to that, is the fact that it works (just less often than I'd like) and the addage does say, "if it ain't broke...". Anyway, your article looks like just the thing to get me to sort this out more professionally. And then, perhaps I'd need to find a way to increase the "quiet hours" at home so that I can find the time to work on the linux box (or anything else in the computers!) without my 19month son helping my efforts by banging away at the keys! Cheers, and thanks again JOE[Hi Joe, You sent me this nice long e-mail, which is really quite interesting. I am also glad that you are going to find cron of some use, and thus my article. Perhaps, you could insert a crontab entry which shutdown your machine, before your 19 year old son gets to your computer!!!! Keep in touch -- Thomas Adam (Linux Weekend Mechanic)
2. Edit the file "/etc/XF86Config" using your favourite text editor.
Section "Screen"
Driver "SVGA"
SubSection "Display"
Depth 8
Modes "800x600" "640x480"
EndSubSection
SubSection "Display"
Depth 16
Modes "800x600" "640x480"
EndSubSection
SubSection "Display"
Depth 24
Modes "800x600" "640x480"
EndSubSection
SubSection "Display"
Depth 32
Modes "800x600" "640x480"
EndSubSection
Monitor "Primary-Monitor"
Device "Primary-Card"
DefaultColorDepth 8
EndSection
Modes "800x600" "640x480"
And then, if you have not done so already, change the value of "DefaultColorDepth" to be 16
And that is all there is to it. Save the file and then boot up your X display.
I know that there are programs which can do this editing for you such as "Xconfigurator", but I find that editing the file myself is much quicker!!

The other alternative that I mentioned was to use XDM. This is the login client that I use, as it is simple!! This one takes a little more configuration that KDM but it is the one that I like to use.
Here are a list of files that we shall be using, and they are all found in the directory: "/etc/X11/xdm". The files we shall be concentrating on, are the following:
/etc/X11/xdm/XresourcesI shall take each file in turn, explain that files role, and tell you the best way to customise it....
XresourcesThis file allows you to customise the look and feel of the main login window. You can also set and disable certain keystrokes. This file is probably the most important to customise.
While it may not be necessary for you to customise this file, I shall point out things that you can do, if you feel the need. I shall not be covering this file line by line, but most of the information in this file is quite self explanitory.
1. To change the text at the top of the login box, edit the value thus:
xlogin*greeting: Welcome to this console
I have changed the "Welcome to this console" to "Welcome to CLIENTHOST". This is so that I know, on my home network, which terminal I am using. The "CLIENTHOST" is actually a variable, which holds the first part of your hostname. Thus, in my case it is Grangedairy, but if you have not changed your hostname since you installed Linux, then most likely, "CLIENTHOST" will return LocalHost
Just as an aside, if you do want to change your hostname, edit the values stored in the "/etc/hostname", and in a file "/etc/sysconfig/network", if the latter exists. Note, for the changes to take effect, you will have to switch to run-level 6 (init 6)
2. You can also change the colour of this greeting, to be whatever you like. Find the following:
xlogin*greetColor: CadetBlue
I have changed the "CadetBlue" value to something a little more vitalising....guess what it is?? No? It's "Yellow", and rather surprisingly, it looks good too.
3. You can also change the width of various frames of the login window too:
xlogin*borderWidth: 2 xlogin*frameWidth: 0 xlogin*innerFramesWidth: 1
The first , sets the overall border commandwidth of the login screen. Experiment to see what a value looks like. I find that 2 looks ok, on both my desktop and laptop machines.
The second command, sets the frame width of the border. I tend to leave it at 0
The third command, set the inner frame width for each of the input fields in the main login window, namely "Login" and "Password". When I edited this value, I hated the outcome, as each of the boxes looked "embossed".
You can set things like the background colour of the main screen, and change the colour of the error message "Login Incorrect":
xlogin*failColor: red *Foreground: black *Background: #c0c0c0
Thus, the first command is very self explanitory. It should also be said, that when changing values of this type, one can either specify the name of the file, or put the #RRGGBB format aswell.
The second and third commands, sets the foreground colour and background colour respectively.
Thats it for this file. I am sorry if all of this seems rushed, but the majority of the file is fairly straightforward. I just thought that I would highlight some points of interest.
There really isn't much to say about this file, other than this file allows you to change virtual consoles. Although I would only advise changing these settings if you know that the VT you are changing to does not have mingetty running on it. I have had some interesting problems with this before!! If you are uncertain, consult the settings in "/etc/inittab"
:0 local /usr/X11R6/bin/X :0 vt07
So, to customise this value, change the number(s) after "vt", to start X on the virtual terminal of your choice. It is also worth noting that you can also specify the colour depth to use, if you are using one other than that set in the "/etc/XF86Config" file. To do this, append the following after the "vt07" bit to look like this....
:0 local /usr/X11R6/bin/X :0 vt07 -bpp 16
[I have xdm running two xservers, one on vt9 and the other on vt10. The first one is mine. I chose vt9 because F9 the first key in the third group of function keys. vt10 is for my roomates, so they can do their thang without disturbing my idle session. My /etc/X11/xdm/Xservers (on Debian) looks like this::0 local /usr/bin/X11/X :0 vt9 -bpp 24 -deferglyphs 16 dpms :1 local /usr/bin/X11/X :1 vt10 -bpp 24 -deferglyphs 16 dpms-Mike.]
This file sets the various configurations of XDM, by invoking various files. I have never had to customise this file, so I doubt if you will either!!
This file holds a list of window managers that X will use. Note that you can specify as many as you like, one after the other, line-by-line, but only the top one will get executed. And, if it cannot find it, then it executes the second one down, and so on. Thus my configuration is thus:
/usr/bin/X11/AnotherLevel /usr/bin/X11/twm #file below symlinked from "/usr/openwin/bin/openwin" /usr/bin/X11/openwin
In the meantime (and as like last weeks' ending)Happy Linuxing....
 |
Send Your Comments | |
Any comments, suggestions, ideas, etc can be mailed to me by clicking the e-mail address link below:
 Thomas Adam
Thomas AdamMailfilter is a very usable tool. It helps you to keep spam away from your mailbox. Contrary to the filtering with procmail, mailfilter filters the mail online. This means that mailfilter deletes unwanted spam directly from your POP3 account before fetchmail (or your favourite POP3 client) even sees it. This is different from procmail, which zaps the spam after it's been downloaded and is about to be put into your mailbox. (Examples of using procmail are in a recent Linux Gazette article, http://www.linuxgazette.com/issue62/okopnik.html.)
The benefit from that is that you won't download the spam anymore. This saves bandwidth and makes you a lot happier especially if you have a slow Internet link.
Mailfilter is a very good tool, easy to install and easy to maintain. You can add it to your .fetchmailrc as well, thus automating the procedure of deleting unwanted spam before downloading.
Installing mailfilter is very easy. Just download mailfilter as source (.tar.gz file) from http://mailfilter.sourceforge.net/ and follow the following steps.
To run mailfilter, just type mailfilter on the prompt. Watch out! Mailfilter needs a valid configuration file to work properly.
You can download a sample copy of this file from mailfilter.sourceforge.net, - but we will create this file from scratch here.
Each user who wants to use mailfilter, needs a configuration file. this file is called .mailfilterrc. It has to be located in the home directory of the user.
Follow these steps to create the file and make it (at least a little bit) secure.
Now we need to add some content to the configuration file. Mailfilter will refuse to work if the configuration file is missing.
Lines beginning with a # are comments and thus ignored by mailfilter. Empty lines are ignored as well.
The most important part of the configuration file contains information of your mail account. Just add the following lines to the mailfilterrc file. You may specify more than one account.
Currently, mailfilter only supports POP3 accounts.
It is important not to change the order of the lines.
Another important option is to specify a logfile using the following line.
Now, you'll have a very basic configuration file. Mailfilter now will run but it won't do anything useful on the mail.
This is the trickier part of the mailfilter configuration. We will now add commands to actually do something useful with our mail.
This is done by adding special command lines to the configuration file. Mailfilter uses regular expressions for the filtering.
To do this, add the following line to your configuration file.
Be careful! mailfilter will not try to interpret ``v i a g r a'' as viagra so blanks are not normalized.
This is easy. Add the following line to your configuration file.
This will become handy if you receive spam from the same address. Use the following syntax:
You may kill spam from entire domains as well. Use this syntax to achieve that:
As you can see, the way to tell mailfilter what to do follows an easy to use scheme. You may block mail by CC, BCC, TO as well.
This feature allows mailfilter to ignore mail sent by a specific person even if one of the other filters would apply.
You may apply this to specific subjects as well. If a spammer starts talking about mailfilter, for example.
Fetchmail has a feature to call filter programs before fetching the mail. Add the following to your .fetchmailrc to call mailfilter every time you download your mail.
preconnect mailfilterReplace mailfilter in the line above with the complete path and the name of the mailfilter binary. /usr/local/bin/mailfilter for example.
Be careful! If mailfilter fails (config file damaged, password wrong, etc.), fetchmail will not connect. So test your mailfilter configuration standalone each time you add a new directive.
Mailfilter is a very good tool. I wasn't able to force fetchmail to filter in the body of a mail. But at least, it allows working spam protection if the addresses of the spammers are valid.
This works very good and I can only emphasize: give mailfilter a try, especially if your Internet link is slow and you receive a lot of spam.
Matthias ArndtThe instructions for using your computer do not always include how to get a free operating system. [That's an understatement! -Ed.] Debian GNU/Linux is a free network operating system. You can get a Debian CD image file (".iso" or ".raw") for free from a download from the Internet. Then you can make a bootable install CD from that ".iso" file. You will need to use the ftp and rsync programs.
When you post a question about how to get a Debian CD image file, you can run into a heavy work day. A heavy work day can often frustrate you because you may get the "speedy fast answer". On those "speeding fast answer days" you would be asked to read the page at cdimage.debian.org. However, you may get stuck. Welcome to you new folks; you may get especially stuck if all of this Open Source freedom of speech and freedom of source code is new to you.
Some "speedy fast answers" may ask you this question: "Do you want to know how to do this?". To the potential new Debian-folks out in cyberspace: read between the lines. You are being offered some clues. Just say yes, my friend. So, for all of you folks who want to know the straight and direct commands, this Bud's for you. This is how you get Debian with rsync:
rsync -rv trumpetti.atm.tut.fi::debian-cd/2.2_rev3/i386/binary-i386-1_NONUS.iso /right/hereTo save trumpetti's bandwidth, use a mirror in or near your own country instead. The list of mirrors is at http://cdimage.debian.org/rsync-mirrors.html.
You can go blazing fast with costar's pseudo-image kit for making a Debian CD.
rsync -av trumpetti.atm.tut.fi::debian-cd/2.2_rev3/i386/binary-i386-1_NONUS.list /right/here http://cdimage.debian.org/cd-images/2.2_rev3/i386/binary-i386-1_NONUS.list
You can make a mirror of the Debian archive at home. When you want to access the mirror with the pseudo-image kit, you tell it the path to your mirror and also include the "debian" directory so that there is a "dists" directory waiting underneath.
/mnt/mirror/debian ftp://ftp.us.debian.org/debian
./make-pseudo-image binary-i386-1_NONUS.list /mnt/mirror/debian --or-- sh make-pseudo-image binary-i386-1_NONUS.list ftp://ftp.us.debian.org/debian **
**There must be a dists directory directly under the mirror directory.
mv pseudo-image binary-i386-1_NONUS.iso
rsync -av trumpetti.atm.tut.fi::debian-cd/2.2_rev3/i386/binary-i386-1_NONUS.iso /right/here
There are some crippled MD5SUMS files that are next to useless. Here is a crippled one:
MD5 (my-fine-new-iso-file.iso) = 9ce8f9fd8f5f1f47efe3eb77d5aae96b
They have the filename and the sum but the "md5sum -c" option can not be used on these files. Here is the way it should look:
9ce8f9fd8f5f1f47efe3eb77d5aae96b my-fine-new-iso-file.iso
There is a space or two between the sum and the filename. Do not put three spaces or a space will be part of the filename.
md5sum -c MD5SUMS
To get it all faster. Like this afternoon.
Elapsed time of a download on the release date from one of few CD iso image sites: Lots of hours and possible interrupted transmission.
Elapsed time of a download on the release date from one of many Debian package mirror sites: Lots fewer hours and less possible interrupted transmissions.
Your CD image will be made via ftp or even direct from your local mirror. Instead of wandering around in ftp-land, you got a list and nabbed only the files you need to make a CD. Smart.
To update your CD image, rsync needs the same filename on each end.
Let us say that you have made a dd of your CD.
dd if=/dev/cdrom of=/here/is/mynewfile.iso
You can keep it around and update it with rsync.
You need to know the name of the same CD file on the rsync server.
Then you can rename this new iso to the right name.
To find the filenames:
Find an rsync server.
rsync -avn the.server.goes.here::
and then its modules will appear.
rsync -avn ftp.fifi.org::
You will see a module named debian or debian-cd and you can infer that debian-cd probably has the iso images you want.
Now get the list inside that cdimages module:
rsync -avn the.server.goes.here::cdimages/ rsync -avn ftp.fifi.org::debian-cd/
will show you every entry in that module. A name and a directory location path for your CD image file will become apparent.
The image you want is the non-US version because it comes with security pgp and encryption software. You are not selling it from inside the USA to non-approved entities so you go for it. You will need to find a non-US image.
rsync -rvn the.server.goes.here::cdimages/ | less rsync -rvn trumpetti.atm.tut.fi::debian-cd/ | less
will get the list and it will be piped into the less pager.
The pager less can go blank while you wait on a delayed loading of a huge list, and you can output to a file:
rsync -avn the.server.goes.here::cdimages/ | less -o my-list-file rsync -avn ftp.fifi.org::debian-cd/ > my-list-file
The accidental big-big list:
rsync -avn ftp.fifi.org::debian/ > my-new-list-file
If you try to get a whole Debian mirror list of files it can take 7 megabytes to make your list file. Really. There is a whole world of software in Debian.
The fifi site has a module called debian and if you try for a list of files from there you will get a big file indeed.
To get an rsync update, your file has to be named the same.
mv mynewfile.iso /right/here/potato-i386-1_NONUS.iso
The command line length begins to wrap around on you and it can be shortened with the backslash newline character.
rsync -rv --block-size 8192 the.server.goes.here::cdimages/2.2_rev3/i386/potato-i386-1_NONUS.iso /mnt/here/is/where/it/goes
There is a space between "iso" and "/mnt".
rsync -rv --block-size 8192 \ the.server.goes.here::cdimages/2.2_rev3/i386/pot\ ato-i386-1_NONUS.iso /mnt/here/is/where/it/goes
You can chop it up with a backslash to compact the line.
rsync -rv trumpetti.atm.tut.fi::debian-cd/2.2_rev3/i386/binary-i386-1_NONUS.iso /right/here
The above command will put the potato-i386-1_NONUS.iso in the /right/here/ directory.
Only the differences between the two files will be transmitted. You save a lot of bandwidth.
Making a 670 MB file requires 670 MB free space!
For an update that is 670 MB in addition to the CD image file already on your disk.
rsync -av --timeout 999999 --block-size 8192 the.server.goes.here::cdimages/2.2_rev3/i386/potato-i386-1_NONUS.iso /right/here rsync -av --timeout 999999 --block-size 8192 \ the.server.goes.here::cdimages/2.2_rev3/i386/po\ tato-i386-1_NONUS.iso /right/here
There is a space between "iso" and "/right".
You can assign a temporary directory with -T if there is no room on the working directory partition. You need room for the huge shadow file which is the same size as that CD image file you are getting.
type df to see your space rsync -av --timeout 999999 --block-size 8192 -T /my/temp/dir \ the.server.goes.here::cdimages/2.2_rev3/i386/pota\ to-i386-1_NONUS.iso /right/here
There is a little catastrophe that you can do to yourself:
rsync -av the.server.goes.here::cdimages
will try to dump all of the contents of cdimages onto you!
put the / at the end of the line.
The "-n" option is the "--dry-run" and will show you what it would have done. ("Let's not and say we did.")
rsync -avn the.server.goes.here::cdimages/
will only show the list.
rsync -av trumpetti.atm.tut.fi::debian-cd
will get you 16 gigabytes of CD image goodies in all architectures. Enjoy!
rsync -av trumpetti.atm.tut.fi::debian-cd/ | less
shows a big list. Maybe use the "-n" to be safe when you are looking for files.
rsync -av --timeout 999999 --block-size 8192 -T /my/temp/dir \ trumpetti.atm.tut.fi::debian-cd/2.2_rev3/i386/potato-i386-1_NONUS.iso \ /mnt/here/is/where/it/goes
will dump the new CD image file into /mnt/here/is/where/it/goes.
The manual does not have the examples shown here.
You can make a backup, you can use ssh, you can execute commands on the remote to make the file list, you can exclude files, you can include files, you can move the temporary directory, etc. It is a fine copy program and only the differences between files of the same name are transmitted across the bandwidth.
You have got to have the same names of files locally. This rsync does a dandy job of mirroring, but if there are always a ton of new filenames then you are just doing ftp.
Here is a first timer's primer:
A lot of you are going to use rsync to grab a new CD file. Do us all a favour and keep that original CD file. You can update it to the new version by only getting the differences via rsync.
And now I am going to criticize everybody and his dog. You folks are wasting bandwidth. Are you always editing and slightly changing your web site? Then use rsync to mirror your web site. Want to add 50k of scripting everywhere on each of your pages? Then keep the same filenames and mirror it with rsync. Did you stay on the cutting edge and download that new iso file and make a brand new CD? Then rename it and update it with rsync for the newest version. What am I getting at?
When you try to get a Debian CD the huge list of files will be loaded into memory and that is what is taking so long. It is not stalled. Wait. Have patience. I quote Mr. Miyagi in the Karate Kid: "Wax on. Wax off." Each of those many files is being opened for a checksum to see if it needs to be transmitted. Wait.
Get the md5sum.txt file. When it is in your directory after the rsync, type
md5sum -c md5sum.txt
and the file will be checked for accuracy.
Get the pseudo-image kit here.
Get the list for the pseudo-image kit.
rsync -rv --timeout 999999 --block-size 8192 -T /my/temp/dir \ trumpetti.atm.tut.fi::debian-cd/2.2_rev3/i386/binary-i386-1_NONUS.list \ /mnt/here/is/where/it/goes
will put the list file in /mnt/here/is/where/it/goes. It is called binary-i386-1_NONUS.list.
That binary-i386-1_NONUS.list will be used to build your CD image. If you have a partial mirror of Debian (oh sure, 14 gigabytes of stuff) then the pseudo-image kit will make a CD for you from your local mirror. It is very blazing fast for all you speed freaks. I must admit with disk drive prices being reasonable it is time for all of us to buy up the remaining stock of usable drives. You may not know about the effort to lock you down, but the age of freedom of fair use is ending.
Why not slam your ftp server with 670 more megabytes and several hours of work?
To quote the clear coder J.A. Bezemer from a thread on debian-cd:
" > Most people get bits from the local hard disk a lot faster than > they get bits over the network. The pseudo-image kit finishes in > minutes, instead of hours, on most "fast" connections. That's one part of the story; the other is that we have only a few CD image mirrors and about 250 packages mirrors, and the Kit does a great job to distribute the used bandwidth more evenly between all mirrors. Remember that every single bit flowing from any of the Debian mirrors is sponsored by someone, and this way the people who invested in big disks for the CD images don't have to pay that much for their net connection. "'Nuff said.
The copyrighted material on a music CD is definitely covered with legal rights and permissions. With the genetically engineered mutation of Napster, we can clearly see the lock-down coming. New hard disk drives and other storage mediums are in danger of being copy-protected. You can use software, but it has to be approved software. Sounds all warm and fuzzy, eh? Put it this way: Thou shalt not reproduce.
"Using --partial will kill your valuable pseudo-image if rsync fails after 1 byte has been transferred. So either back up your pseudo-image or do NOT use --partial."So do not use partial, eh?
rsync.samba.org -- the home of rsync and its Faq-O-Matic
NSBD -- Not-So-Bad-Distribution at Bell Labs uses rsync to securely update you
rsync resources -- Multiple system install and updates with rsync
rsync resources -- Setup anonymous rsync servers
Help File for Captives -- if you are seeking freedom
There were no freeze-ups or crashes during testing of these procedures. We suspect GNU/Linux software is to blame.
Bill BennetBill, the ComputerHelperGuy, lives in Selkirk, Manitoba, Canada; the "Catfish Capitol of North America" if not the world. He is on the Internet at www.chguy.net. He tells us "I have been a PC user since 1983 when I got my start as a Radio Shack manager. After five years in the trenches, I went into business for myself. Now happily divorced from reality, I live next to my Linux box and sell and support GPL distributions of all major Linux flavours. I was a beta tester for the PC version of Playmaker Football and I play `pentium-required' games on the i486. I want to help Linux become a great success in the gaming world, since that will be how Linux will take over the desktop from DOS." It's hard to believe that his five years of university was only good for fostering creative writing skills.
OLinux: Could you tell us about your carreer, professional abilities, etc.?
Cédric Godart I've been a radio presenter and journalist for 3 years since I left the University (I graduated in translation). I'm 25 years old and I live in Brussels, Capital of Europe. My computer skills wouldn't sound very exciting. I've actually been very interested in the Linux and Open Source movement for three years. Honestly I use two different OS on my home computer, ie Linux and MacOS X.
OLinux: What were the main reasons that brought about the extinction of Linux Today French Version?
Cédric Godart: Advertising revenues have been very low since the beginning of the year. Internet.com will now only focus on profitable sites. International editions of their Linux and Open Source sites are no longer profitable. The decision was expected but it came as a surprise since LinuxToday Fr was only 9 months old.
OLinux: How many people were involved on the website? How do they react to the extinction?
Cédric Godart: I was the only "journalist" to work on LinuxToday French. A daily press review and about 5 articles a week were my main "mission" on the site. A student helped me with the press review when I was on vacation. Technical issues were in the hands of Scott COURTNEY and Paul FERRIS (the "father" of LinuxToday), both working for the Linux & Open Source Channel of internet.com, in the USA.
OLinux: What were the most significant differences between the english version and the french version of 1 today?
Cédric Godart: While the English edition only focused on a press review, adding features from time to time, the French edition offered a press review and daily articles. These articles were also posted on the popular France.Internet.Com, that supported us since Version 2, launched in January.
OLinux: Could you expect that French Linux Today wiould be successful so quickly?
Cédric Godart: I was actually very surprised to see how successful the site became in a couple of months only. Companies and Linux users soon became addicted. To me, the French audience was really in need of some kind of professional (-looking) news site about Linux and Open Source. The success of the English edition also helped us reach a wider audience : indeed, the "LinuxToday" brand is a reference. It may be the reason why the popular Linux Mandrake French site decided to display our news on their homepage.
OLinux: Did internet.com influence in your productivity and in your editorial board?
Cédric Godart: Never! Kevin REICHARD (Executive Editor, Internet Technology and Linux/Open Source Channels) trusted me.
OLinux: Despite you have received a bunch of e-mails concerning the disapperance of fr.linuxtoday.com, did you believe for a moment that internet.com could change their mind?
Cédric Godart: No, not really. I expected them to "transfer" Linux and Open Source properties to their official French site, france.internet.com. But times are bad for those international editions, as well. If Yahoo keeps telling that the advertising model will undoubtedly prove profitable in the future it's still not.
OLinux: Do you think that economic crisis which also involves open source enterprises will be reflected in Linux and open source news sites?
Cédric Godart: Of course. The Linux market is not mature yet. These are bad times for the whole IT economy. Only a limited number of companies focusing on Linux and Open Source solutions may claim to be profitable. Time will tell.
OLinux: How many page views LinuxToday french version have had per month? And how many stories did you publish every day?
Cédric Godart: Pageviews must remain confidential, I'm sorry... Every day, I could find about 15 articles for the press review and at least one real article. It took me a couple of months to find reliable sources to make a comprehensive press review.
OLinux: If internet.com choose for keeping the site's archives, and they invite you to continue working on it, would you accept or not? Why?
Cédric Godart: We can dream! I don't think they would ever do it.
OLinux: Taking into consideration the widespread adoption of Linux worldwide, do you think Linux is a adequate solution when we talk about economic advantages for governments and institutions?
Cédric Godart: I don't really agree with "widespread adoption" of Linux. Linux stands for 5 % of today's desktop market. Only a very limited number of people actually use it as their primary OS. The vast majority keep using Windows, because most people don't really care about rebooting their machine from time to time. Linux must remain a professional OS. Only MacOS X may claim to be a REALLY consumer-oriented Unix. Economical assets for governments and institutions, as well as the availability of source codes, are indeed a key factor for the adoption of Linux in the public sector. You've certainly heard that the French government recently announced their decision to support Open Source technologies.
OLinux: What does a Linux news site must have? Could you tell us some tips that you learn while french 1 today editor?
Cédric Godart: 1/ Stay focused but keep on other OS (Windows / MacOS X and BeOS); 2/ Avoid grammar and syntax errors; 3/ Keep distant from stupid OS wars (Windows sucks), leave it only to fat old geeks or newbies using Outlook Express to post messages on Linux forums ; and 4/ Never show any preference for any company.
OLinux: Can you send a message to OLinux users?
Cédric Godart: Yes, of course. Sorry for not replying in Portuguese. I was actually very surprised when I received your request for an interview. I didn't know a French site, located in Europe, could ever interest people living thousands of miles away! My message : use Linux because you love it, not because it sounds fashionable and never use the word "WindBlows" if you send your messages using Outlook Express.







A big thanks to SirFlakey for allowing us to publish his Qubism cartoon.
It's been two months since HelpDex finished up on LinuxToday.com. Since then, strips have only been appearing on www.LinuxGazette.com but nowhere else. Due to a bunch of people emailing and asking "Where the hell is my daily HelpDex!??", I'm going to try and get cracking again. I've restarted it as of the first of May. The new URL is http://www.shanecollinge.com/Linux. (Please ignore the popups. I've tried to minimize them but it's a free server.)
Stay tuned. I have a pile of Vi-Agra strips coming up, the odd Maximux strip thrown in for good measure, and of course more Carol and Tux!!!
Shane CollingeJon "SirFlakey" HarsemHere is a collection of little-known tools, a couple of which, I find extremely useful every single day. I'll warrant that most people have never heard of any of them. O.K., they are not exactly a secret - they are, after all, freely available on the net, but they do deserve more than the scant attention they receive.
Even when you are looking for applications which will perform like 'xsnap' or 'xclip' they are difficult to find. Utilities like 'showbook' and 'splitvt' are sheer serendipity.
After using 'Snap!' for years, when I made the move to Linux, this was the app I searched high and low to replace. No, xsnap doesn't have the OCR capabilities which were a part of 'Snap!', but it's still very useful none the less.
Xsnap is a little app which takes screen-shots. Big deal. Lots of programs exist which do the same thing. The difference is that xsnap allows you to capture arbitrary areas of the screen (including entire windows or screens) and it's fast.
When you run xsnap your mouse cursor will change to show an angle shape; simply position the cursor and 'drag' a rectangle describing the area of the screen you want in a snap-shot. That's it. Press either 'p' or 'w' in the resulting window to save a numbered snapshot to your home directory.
It doesn't sound like much, but when you want to email just a portion of an image, or make a little sticky-note for yourself as you peruse a website it's just what you need. Actually, taking screen-shots of running apps is the least of what I use xsnap for. Making fast, simple sticky-notes of docs, emails and man pages for just a few minutes reference is where xsnap really shines.
Really, just take my word for it, xsnap is tremendously useful, especially when assigned to a hot-key like 'print screen' (what are you using it for anyway?). In fact, xsnap is almost wasted if it's not attached to a global hot-key.
Unfortunately it saves it's files as 'xpm's. These are very large.
As always though, we can script our way around such short-comings. Just make a script which processes the file for you on the fly. Here's an example of a script I have attached to my hot-key:
#!/bin/bash # xsnap-jpg. Runs xsnap, converts to jpg and loads electric eyes. xsnap -stdout | xpmtoppm | cjpeg -quality 75 >~/snap.jpg;ee ~/snap.jpgTo save typing it shift-click here. Then type 'chmod 755 filename' on the resulting download to make it executable. This will function just the same as xsnap except that files will be jpeg and you can do all that ee can do too - also you won't have your home dir junked up with numbered files. '-quality 75' is actually the default for cjpeg. Change the '75' to a lower or higher number to get the file sizes/quality you prefer.
I should mention that there's one little extra step to compiling xsnap. You will find that it doesn't come with a working makefile or a configure script. To create a makefile just type 'xmkmf' ( x make makefile). Then make as usual.

While you're on that same page downloading xsnap , Lupe is a very nice magnifier with a few extras for colour and position (plus it has a cool 'heads-up' style display).
Xclip is a very simple app. Why it wasn't available to Linux users until now is beyond me.
Quite simply, it allows you to place whatever you wish into the clipboard. Period.
A simple example. Suppose you want to send your friend a directory listing; no problem. Just type "ls | xclip" at your nearest console and then middle-click to paste into your email. In fact any program's std out can be piped to xclip: 'whois', 'showbook.pl' whatever.
In combination with a script to grab the currently selected text it becomes even more useful. Suppose you've just typed an unsorted list, but you want it sorted alphabetically. Highlight the list with the mouse, press, say, alt-shift-S and then middle-click to paste in the freshly sorted list! This trick can be used to do any number of things: sum a column of numbers, make banner-style comment blocks, quick-notes...
Here's a python script which uses the wxWindows library to do all of the above. Just attach it to different hotkeys using the appropriate command line switch (e.g. 'clipmanip.py -c' to create comment blocks).
This little gem is indispensable if you have a lot of bookmarks. showbook.pl parses your Netscape bookmark file and returns the URLs it finds there. In fact, it's so useful that even though I haven't used Netscape in a couple of months I export my bookmarks file from Konqueror every once in a while just so I can keep using it! (nb: Konqueror mangles the syntax slightly, so you'll need to run Netscape once and explicitly save bookmarks to sort things out.)
Here's a sample search using showbook.pl:
[paul@oremus paul]$ showbook.pl wxwin == Misc == <A HREF="http://web.ukonline.co.uk/julian.smart/wxwin/">wxWindows</A>
Yes, I had just used it to grab the URL I needed for wxWindows :-)
number.pl
by Landon Curt Noll. Email: "number-mail at asthe dot com"
Prepare to be humbled: This man has more degrees than a thermometer. The cv of anyone else looks positively anemic beside that of Mr. Noll's.
number.pl is the most thorough treatment of a "number to words" script I've ever seen. Granted, you may not use it everyday (unless you hook it into your cheque register), but it's such a nice piece of perl I had to include it. I normally stop writing at the largest cheque I can conceive the customer to write. Not Mr. Noll:
[paul@oremus paul]$ number.pl 123456789123456789.12 one hundred twenty three quadrillion, four hundred fifty six trillion, seven hundred eighty nine billion, one hundred twenty three million, four hundred fifty six thousand, seven hundred eighty nine point one two
I've yet to break it.

Splitvt gives you two consoles in one by splitting the console horizontally. If you click on the thumbnail to the right you'll immediately see how handy it is for viewing man pages while you're building a command line. 'Control-W' is used to bounce back and forth between windows.
Splitvt works fine anywhere I've tried it. Everything from the real console to the tabbed notebook of konsole. No problems, very handy.
Anyone who uses English should have a copy of WordNet on their machine. WordNet is a dictionary, not just a spell-checker, but a real, honest to goodness dictionary with meanings in context.
I must warn you that it is about a 10 megabyte download, but it's worth it and you only need to do it once. Here's some sample output from 'wn' ( the executable program that comes with WordNet) using the word 'date':
Overview of noun date
The noun date has 8 senses (first 8 from tagged texts)
1. date, day of the month -- (the specified day of the month; "what is the date
today?")
2. date -- (a particular day specified as the time something will happen; "the
date of the election is set by law")
3. date, appointment, engagement -- (a meeting arranged in advance; "she asked
how to avoid kissing at the end of a date")
4. date -- (a particular but unspecified point in time; "they hoped to get
together at an early date")
5. date -- (the present; "they are up to date"; "we haven't heard from them to
date")
6. date, escort -- (a participant in a date; "his date never stopped talking")
7. date -- (the particular year (usually according to the Gregorian calendar)
that an event occurred; "he tried to memorize all the dates for his history
class")
8. date -- (sweet edible fruit of the date palm with a single long woody seed)
Overview of verb date
The verb date has 5 senses (first 3 from tagged texts)
1. date -- (go on a date with; "Tonight she is dating a former high school
sweetheart")
2. date, date stamp -- (stamp with a date, as of a postmark; "The package is
dated November 24")
3. date -- (assign a date to; determine the (probable) date of; "Scientists
often cannot date precisely archeological or prehistorical findings")
4. go steady, go out, date, see -- (date regularly; have a steady relationship
with; "Did you know that she is seeing her psychiatrist?" "He is dating his
former wife again!")
5. date -- (provide with a dateline; mark with a date; "She wrote the letter on
Monday but she dated it Saturday so as not to reveal that she procrastinated")
Whew! Very complete eh? And the above output is actually truncated!
WordNet comes with a tcl/tk front-end which I've never actually had functioning. It seems to insist on an older version of tcl/tk. I normally call it from a hot-key (control-shift-E) with this little script which uses gdialog for input and output. I think gdialog comes with most major distributions. Xdialog is very nice too and basically a drop-in replacement.
In a similar vein, and to show how easy it is to adapt a script, WORDS for LINUX (i86) is a Latin dictionary you can use the same way. The script is here. In fact I should probably make a copy of it which uses showbook.pl... Now, why not round out your bookshelf with a thesaurus? gThe is just the ticket. You can find it here. has done a nice job with this using a freely available thesaurus. I would like the gui to accept an argument from the command line though. I must remember to write and ask if he'd do that sometime.
Some of you may be wondering why I haven't mentioned exactly how to attach a program to a hot-key in the first place. The answer is a simple one: I don't know.
That is, I don't know how you can do it, because I don't know which desktop you are running. They all seem to employ different methods - if they have one at all. What follows here is not an exhaustive study, but I did spend more than a couple of hours playing around. If you know of a method that will work globally with every desktop please send me an . My results, outside of two desktops, have been abysmal. I've tried the xmodmap route, but, beside the fact that I didn't actually break anything, I didn't achieve anything either... In case it's early in the day for you, this is an anguished cry for some with this one.
IceWM
As some may have noticed from the screen-shots, I was using IceWM at the time. The theme in the screen-shots is my own peculiar blend of "blue plastic" and "Photon" (I always wanted LED's that lit up when you clicked them). In fact, I lived in IceWM for a couple of months. It's a very nice, light-weight desktop and I found it to be both servicable and stable. If you are using it without IcePref (by David Mortensen) and iceme (by ) you are really missing out. Both are written in python, so you're free to play. The first thing you should do after running iceme is use it to add itself to the menus. Now, you can have iceme whenever you want. Another benifit is that iceme has the ability to call IcePref, so you get the best of both in one go. iceme makes it so very easy to make hot-keys that I'm not even going to describe the procedure. Both these guys should be sent beer and Swedish cookies at your earliest convenience.
Sawfish/Gnome
Alas1, this was one of my failures. I have no idea what I'm doing wrong. The Sawfish configurator had a couple of likely looking candidates in the (extensive) list, but I failed to get xsnap attached to a key and come up normally. I just know that this has to be a manifestation of my own density :-). As I wrote earlier: Help...KDE
In KDE's 1.x versions there was an app call khotkeys. It had a nice gui, but you had to do a little work to make it print arbitrary strings (like a long email address at the touch of a key). Since 2.0+ some of that functionality is gone, because it hasn't been re-written yet. However, all of the above can be done if you create menu entries for every script and use kmenu to assign it a key. Simple.
Simple if you're not running Mandrake. Don't get me wrong, Mandrake's distro is great, Great even. I've been using it exclusively since the 6.2 version. The problem is that it doesn't even include kmenu and its supporting library. Given that khotkeys hasn't yet been ported to 2.x this is reasonable, but it leaves us a bit 'out in the cold' when we need hot-keys!
Fear not. There's always a way! Under KDE 2..x there is no need to run khotkeys explicitly - it's just there. If you don't want to download kmenu et al and you are running Mandrake, here's all you need to do:
Load the file "/home/yourdir/.kde/share/config/khotkeysrc" into your favourite editor. It has an entry at the top for number of sections, just increment that by one whenever you add a section. You can make entries for things which point to an already existing menu item or you can just make one up. Here is an example of each:
An entry that points to a menu item:
[Section1] MenuEntry=true Name=K Menu - Graphics/xsnap-jpg.desktop Run=Reference/xsnap-jpg.desktop Shortcut=F12An entry that points to just a command line:
[Section15] MenuEntry=false Name=calc Run=gtapecalc Shortcut=Ctrl+1
After you have added your changes to the khotkeysrc file you can tell khotkeys to re-load its configuration using dcop. This is an 'InterProcess COmmunication Protocol' or IPC. What this means is that you can 'talk' to programs while they are running and tell them what to do. Type 'kdcop' in an xterm to see what's available. Here's the command line to run in order to get khotkeys to re-read its config:
dcop khotkeys khotkeys reread_configuration
There are two other peculiarities with KDE that I should mention. One concerns your environment and the other the clipboard.
First, your menus when you start KDE with Mandrake. Mandrake has written their own, custom 'startkde' script. And with good reason: it spreads common menu entries around in a consistent manner. However, this means that whenever you log in to X using KDE, Mandrake's script will overwrite the additional entries made by either kmenu or yourself. Solution: take write permissions away from everyone - even yourself - for the directories and entries that you make by hand in '.kde/share/applnk-mdk'. This will cause a few errors to be written to your '.xsession-errors' file, but it will keep your work safe.
Second, Mandrake's re-write of the 'startkde' script (and I'm not kicking against that at all) does not recognize your environment . When started from kdm, the graphical log-in manager, you end up in a desktop which has no clue to the paths and aliases that you've set up. A quick solution to this is to modify Mandrake's 'startkde' script which is found in /usr/bin. Just add these lines near the top:
source $HOME/.bashrc
source $HOME/.bash_profile
This way it reads your environment as if you had begun with 'startx' from a console.
I may, easily, have missed your favourite desktop in this (heck, I only surveyed 3 out of a zillion). Please drop me a line with how yours works.
That's almost it, but I'd be remiss if I didn't talk about the clipboard a bit.
'Windows'/'OS2' has 256 clipboards and so does the 'Amiga'. 'X' has the same - plus. Under 'X' there exists the same, static, 256 clipboard entries plus what is called the 'Primary Selection'. This is the text that is actually highlighted at the moment. The 'Secondary Selection' refers to the usual 256 clibboard entries. Generally speaking, whatever is highlighted at the moment may be 'pasted' by pressing the middle mouse button. Very slick.
Unfortunately, things can get a bit muddled and you are entirely at the mercy of the toolkit as to how this all plays out. I have noticed that under KDE2x something is stealing the selection focus. I've tried turning off klipper, but to no avail. In practice, this makes the 'clipmanip' scripts useless, because the focus is stolen before you can paste the manipulated clipboard contents.
Fear not brave soul! We can play this game out. If we can't have a general solution, we just have to aproach things a bit, well, side-ways. We will not be thwarted by a mere difference in clipboard conventions. With the exception of 'clipmanip -n' we seem to be done for, but don't count us out just yet...
We turn for succor to our Trusty Editor. Now, I'm well aware that actually espousing a particular editor is little like offering to choose which under-garments you wear, but hear me out on this one.
We can use the same ideas, but 'shield them from attack' from the destop by doing it all inside our editor. All we need is a friendly editor. In strictly geek-speak 'emacs' is cool, because it's written in lisp and it's scriptable in lisp. Now, we, who merely aspire to be Geeks, can use Glimmer by .
Glimmer is not actually written in python (it's C++), but it's so tightly integrated that one hardly notices. I think the Scintilla project and wxwindows will allow a fully python solution any day now. I've used both and they're marvelous. Glimmer exposes many of its methods to python and that's what makes it so wonderful. You can script anything you want. All you have to do is write a python script and leave it in '/home/yourname/.glimmer/scripts' and it will be added to the 'Scripts' menu. Building on what was given to me in the distribution, I offer the glimmer equivalents of the above mentioned scripts here. They are all self-similar and easy to follow along. I've learned alot since I wrote them, but I'm biting the bullet and leaving them the way they were at the time. ( I just took up python a couple of months ago, python/wxwindows is the most sheer fun I've had in years of scripting).
Since you've hung in this long, I'll give you one more: baudline. This app is such overkill for anything we mortals could apply it to , I almost didn't mention it at all. Baudline is the King of freely available audio tools. I wrote my thanks to the author, but I was a bit worried that he might not appreciate Baudline's demise at my hands: answering the phone. I was wrong. Since then, the author, Erik Olson, has added direct support for both rmd's and mp3's et al. If you need to edit/analyse sound look no further.
I hope I have, at least, aroused your curiosity about some of these things. With the exception of WordNet, they are all small downloads. Have fun!
Footnotes
1 If Jerry Pournelle actually has a copyright on this word, I want to plead ignorance now.Paul EvansExploits are about as prolific as kernel updates. Well okay, maybe not that common. Still, vulnerabilities are abundant for any OS no matter what the platform, and the vulnerabilities in Linux are no exception. The Linux Router Project (and Linux-based routers in general) have some unique security issues that Cisco and other proprietary routers do not have, because of the nature of the PC hardware and the Linux kernel. For example, buffer overflows are common with Linux, while hardware routers are almost immune to them. The LRP sysadmin must take care to recognize and address these vulnerabilities.
So on the one hand we have a different router for everything: ISDN, Ethernet, frame relay T1, xDSL, PPP, ..., even a [cable modem/portmapping router/Ethernet hub with a nifty graphic HTML interface], each device unique and purposeful for each unique and specialized routing application. And the source code and hardware is confidential and proprietary.
On the other hand we have a general purpose x86 processor that can do anything with the right software, and the Linux Router Project is a perfect application. It is creating an open alternative to proprietary routers in the same way that a grass-roots effort made Linux an alternative to proprietary Unices. The LRP is an actual Linux kernel, streamlined to facilitate routing in all its forms, and adaptable to just about any networking situation:
Traditionally, firewalls and routers are discrete entities with one box being a router, another box being a filtering firewall, another box a proxy server or what have you. Each service has its own unique hardware, specially designed for the function it performs. In recent times the hardware for these devices started coalescing, much like the way ATA IDE is now built into the motherboard and treated as a part of the motherboard even though four years ago it was an ISA card.
Eventually these multipurpose routers will introduce a new discipline in security --and security means a million things. There's physical security, core (kernel, internal) security, network (routing) security. If the industry avoids proprietary hardware, it should rethink its security. Here's part of the plan:
Vulnerabilities between the Linux kernel and router routers differ. CERT data reports that the most common attacks are denial of service (DoS) and scanning. DoS attacks are easy to do and hard to defeat. Buffer overflows (uncommon) and DoS attacks (common) are possible in both worlds just the same. Port scanning can come from inside or outside. Scanning, though not an 'attack' per se, could easily be construed in a court of law as network reconnaissance, or even a denial of service, depending on the intensity. To my knowledge we have yet to see precedents.
We solve these two problems in the kernel with security patches and nmap. Of the main LRP distros, Oxygen kernels include the Openwall patch --in fact Oxygen is continuously upgraded. If you see a vulnerability, rest assured it's in the latest Oxygen. According to David Douthitt, the brain behind Oxygen, the kernel itself protects "against IP spoofing, unusual packet addresses (martians), and [rejects] ICMP redirects and ICMP echo requests." --Even so, standard filtering (network security, below) should include these rules as well.
nmap: I call this SATAN's successor. It's the touchstone security tool. nmap scans any set of TCP or UDP ports on any set of IP addresses to test and find vulnerabilities in your own network. nmap reveals unnecessary services running on the LRP box. There are unnecessary services running on some out-of-the-box LRP distros (e.g., discard, daytime, time). A quick trip to SecurityFocus.com or Rootshell.com can tell you how to exploit them.
CERT does not discuss other common vulnerabilities from your own users on your own network such as filesystem security or sniffing. Filesystem stuff like fdisk, mke2fs or fstab does not warrant discussion here (though I do suggest that LRP developers include the chattr command with future LRP releases that allow non-root logins), and sniffing won't matter if you only log into the LRP box from the console. --Whoops, it's headless! We will worry about sniffing.
Ethernet sniffing is dangerous. In many cases it is possible to sniff other logical networks on shared cable modem Ethernet segments. Maybe even your neighbor's dynamic PPP connection from another dialup. Viruses and scans and every one of the eleventeen thousand "UNICODE bugs" are already so rampant we can expect sniffing to become much more common and widespread --maybe become a category for CERT if it isn't already. It's interesting how a lack of IP addresses peripherally facilitates cracking...
Encryption and authentication (ssh, ssl, smime, PGP) circumvent sniffing. But since any encryption can be broken over time the best we can hope for is that our data becomes obsolete before the encryption does. We protect the data for the most important window possible --such as a telnet session. Who cares if someone decodes it a year from now? Too many routers rely on password authentication that is subject to brute force attacks or worse, depending on the interface. Here the LRP wins. It supports ssh.
Schema for a typical business infrastructure border router:
The short answer is: "Block Everything." Allow access only to ports where services are running, such as port 80 for the webserver, port 22 for ssh. Wrap and chroot whenever possible (e.g., BIND). Running X on Internet-accessible machines is a big no-no.
Back to routing. Routing is not an easy task for the beginner, hence we have HTML interfaces for Circuit City routers and such. We also have Windows(tm). For others we have the LRP. The text-based LRP menu interface presents familiar annotated /etc/conf.files --simple for the Linux (Unix, Freenix) user but intimidating as a cryptic command line for anyone else. Other one-disk router approaches hold the same disadvantageous learning curve. However, the LRP brings the mysterious Routing Tao closer to geeks than other routers: The commands are familiar. Unlike a Cisco command line 'conf term', LRP configurations and commands don't get old and stale after not touching them for a year. For the non-geek the trade off between a thousand dollar router and the LRP is money versus time.
So you can buy a specialized router router, or you can tweak your vacuum-tube hardware and add wizbang features and compile modules into the LRP kernel and customize. The tradeoff is flexibility versus security. The LRP replaces non-volatile RAM with a floppy and embedded hardware with a kernel: Just keep some special security challenges in mind.
Mark FevolaIntegrated development with productive Unified Modeling Language (UML) Computer Aided Software Engineering (CASE) tools strengthen Open Source's software models support mechanisms and aid in defining complete solutions for complex design problems. The productivity levels attainable increase significantly through productive UML CASE tool selection that provide software engineers the ability to conduct detailed analysis and design. This paper presents benefits associated with using the Open Source software model and UML CASE tools during the software engineering process. The software model is explained and compared to traditional large-scale software engineering techniques. It also explains the models development phases and how software maintenance intertwines with defining a complete solution for Open Source's customer base. This paper also introduces the software engineer to major CASE tools available for Open Source software development.
The Open Source Software Model
The Open Source software model isn't exactly a new technique or process; it's just an alternate view of software engineering techniques applied to traditional commercial developmental models (Godfrey & Tu, 2000, p. 2). Open Source projects have been around since the 1960's, but tend to experience newfound popularity today due to an increased use of the Internet as a communications and information medium. The software engineering process involves:
TheOpen Source software model supports all aspects of these processes and provide engineers with a methodology to follow in order to produce high quality products implementing client requirements. One definite advantage of the Open Source model is its extension and close relativity "to the scientific development model, with code treated as research results, and published for peer review" (Bezroukov, 2001, p.10). As such, the models strength rests in the fact that it's supported through a wider user-base than traditional software engineering models. Its major fault is the fact that "[t]he Open Source software model works best for software that's already successful. It's practically nonexistent for software that doesn't have a user base" (O'Brien, 2001, p.20).
OpenSource projects tend to have a single manager, a development team, and an interested user-base. Each have their own individual insight into the requirements solution and the process normally provides a wider tester base for system maintenance issues. The cornerstone of the methodology is that it's based upon a decentralized model that is supported from a large community of developers concerned with producing quality, mature products. Practitioners enjoy the opportunity of writing code, which is the primary motivation for almost all Open Source software development, and as such continually improve the software engineering process.
The model does have its share of problems and limitations that though, and they revolve around the decentralization of the software engineering process itself. Large portions of developers are not co-located with co-contributors and maintenance during the software development life cycle is done via the Internet. This fact, when coupled with the democratic nature of Open Source software tends to slow down product development (Bezroukov, p.6). The larger the project the greater the obstacles are to overcome. Co-located Open Source software products don't suffer from this phenomenon, as they have a concentrated effort to ensure movement through the development cycle. The Linux Gnome, KDE, and Eazel projects espouse these coordinated Open Source engineering efforts that have brought the model to the forefront of development today.
OpenSource's software model can be defined as a refinement of strengths associated with existing software engineering models. Like other models it attempts to glean the strengths from currently used software engineering models, while excluding the weakness of those models. This feat has been accomplished through open communications and sharing of ideas between major developers of the Open Source movement. The models structure improves on the incremental, build-and-fix, and rapid prototype models by creating a cyclic communications path between the project maintainer, development team, and users or debuggers, see Figure 1. For example, a Unified Modeling Language (UML) tool concept is developed and registered with the Open Source Development Network SurgeForce (http://www.surgeforce.com), an Internet repository for Open Source projects. After the project attracts a development team the maintainer provides them with an initial release for testing and feature additions. The developers, in turn inform the project manager of enhancements and once they have been coded into the application a user base is identified for product testing. The user base also has the opportunity to suggest design flaw corrections and propose new features they would like the maintainer to incorporate into the project. This improved product is then resubmitted to the development team, and this cycle continues until the project has matured into a stable releasable product.
 |
Comparative Models
TheOpen Source Software model maintains ties to traditional software engineering models by incorporating various methodologies of each model:
Synchronize andStabilize Model: This models strength is evident by Microsoft Corporation's dominance in the operating system and software industry. The model synchronizes what programmers have developed and periodically stabilizes the product during various portions on the development process rather than at the projects end. The contrast of this model with an Open Source model is that the Microsoft model focuses on consumers rather than a single client, or problem domain. Because of this difference, the Open Source software model generally suffers from incomplete marketing requirements and little system-level or detailed design along with minimal documentation. (Malik & Palencia, 1999). This lack of focus has been the demise of multiple projects, fortunately those that follow established software engineering practices, and tend to satisfy a valid need, succeed more often with their product.
Waterfall Model: This model provides a classic system development specification that can be adapted during any software development process. The model provides a background for all other models and the Open Source model is not excluded. Testing is completed during every phase of the waterfall method and integral to the success of projects utilizing the Open Source software model. It requires checks and balances during the entire process and the Open Source model extends this idea by allowing increased user interaction for functionality improvement.
Build and Fix Model: Schach (p.64) stated, "It is unfortunate that many products are developed using what might be termed as the build-and-fix model." A majority of Open Source projects begin their development life under this model because they are designed to fix some specific problem experienced by a programmer or systems administrator. If the products matures, it eventually evolves from this model into a full-blown product meeting user needs and satisfying design requirements. Planning can overcome Open Source software model limitations, as the project would apply well-established life cycle methodologies to the model itself. The Apache project started from webmasters sharing patches to NCSA web server and developed into the most popular server connected to the Internet today (Behlendorf, 1999).
Rapid PrototypeModel: The rapid prototype model is a typical solution for a defined system design problem. Several Open Source projects base their development effort on this model, as it provides users with a partially workable product and encourages user collaboration for design improvement. Open Source projects that started off as rapid prototypes during initial releases, normally fail to continue progression under this model because as developmental releases increase, either extensive testing and analysis is required or the project suffers from a lack of developer participation.
Spiral Model: Thespiral model provides extensive risk analysis throughout the entire software development life cycle for large-scale software applications. Multiple prototype systems are deployed dependant on each meeting verification and risk analysis criteria until the completed product is ready for operational release. Like other models, the Open Source software model is normally used in conjunction with the spiral model depending on the projects scope and number of users affected. Open Source relational databases have incorporated the verification and risk analysis functionality of the spiral model into their development phases as there is a significant amount of increase in risk associated with database functionality failure for business users.
The maintenance functionality provided by the Open Source software model is its strongest virtue, as the model relies on productivity to both survive and evolve. Users of the product conduct software maintenance and enhancements are normally coded into the application for later submittal to the developers themselves. The code-base normally remains in constant stable state as the users uncover product limitations and again submit fixes to the developers.
OpenSources weakest point is related to product marketing, acceptance, and an uncovering actual business need for mainstream organizations. Most Open Source projects start off with little or no funding as a solution for a problem experienced in conjunction with the programmers "day job". The Perl programming language was such a product that has matured significantly since Larry Wall first wrote the language in 1986 as a way to generate web pages programmatically. "If a company is serious about pursuing this model, it needs to do its research in determining exactly what the product needs to be for an open-source strategy to be successful" (Behlendorf, paragraph 38). This forethought is what strengthens the Open Source software model.
Open Source and UML
Open Source projects, as with proprietary projects, require a level of requirements analysis and modeling to successfully implement a solution. UML is the definitive approach to building model driven development that incorporates sound processes and robust architectures. The specification allows the developer the convenience of using standard notation to model system components, behaviors, and users. The Object Modeling Group specification for UML states:
"TheUnified Modeling Language (UML) is a graphical language for visualizing, specifying, constructing, and documenting the artifacts of a software-intensive system. The UML offers a standard way to write a system's blueprints, including conceptual things such as business processes and system functions as well as concrete things such as programming language statements, database schemas, and reusable software components" (OMG, 2001).
The OMG's major point concerning UML is that it's a"language" for specifying what a system is supposed to accomplish and not a method, nor a procedure for accomplishing specific tasks. The language may be used to support the software development life cycle in a variety of ways, but it was created to serve as a system blueprint. Requirements analysis is conducted concerning a software or system problem, then modeled via UML and presented as a conceptual solution. The UML specification does not specify the exact methodology or processes that must be used in order to solve the problem, but outlines the analysts understanding of the problem for easy translation by a design team.
UML defines notations and semantics for the following types of problem solution (Erriksson & Penker, 1998):
UMLprovides the Open Source software model with the ability to evolve from simple solution applications for personal use to large-scale applications solving industrial size system requirements. Developers are provided model elements, notation, and guidelines conforming to International OMG standards. It's the process that UML provides the development organization that enables them to refocus their development effort toward easy understanding of these complex problems.
Thefact that UML is "nonproprietary and open to all" (OMG, 1997, paragraph 24) allows the standard notation to be incorporated into a variety of tools and languages devoted to Open Source development. UML has successfully enabled open development efforts associated with the Apache Group, http://www.apache.org, and the Common ObjectRequest Broker Architecture (CORBA), http://www.corba.org, provide vendor-neutral specifications for use by developers on multipleoperating systems.
Themajority of Open Source Computer Aided Software Engineering (CASE) tools exclusively support UML, a methodology that has a combined fruition of three leading methodologists: Grady Booch, James Rumbaugh, and Ivar Jacobson. Unlike other object-oriented methodologies, UML was intended to be an open modeling standard that combined the strengths of many other methodologies that have evolved over the over the years. Manytools support UML version 1.2 and allows users to change between visualrepresentations of Booch, OMT (Object-Oriented Modeling Language), and UML inorder to assist developers that are already used to these older methods transition to UML.
Open Source Tools
Theselection of Open Source tools for system design is not an easy task to accomplish because most tools available are in varying stages of development and few of them provide the level of design required to solve complex problems. Designing an Open Source solution for C, C++, and Java only complicate issues, as many of the advanced tools only target one language, or solution. Budget restrictions suffered by most developers of design tools come to light with tool choice functionality because without funding the tool development cycle is usually a long drawn out process.
Thereare currently 28 different UML tools, in various stages of development, hosted on SurgeForce (UML, 2001) that target the Linux operating system, while several WindowsUML tools are provided by Universities or Integrated Development Environment (IDE) companies to promote their IDEs. The Open Source community maintains several tools for integrating UML support into projects ranging from single-developer applications to larger coordinated efforts. The problem is not finding a tool for a specific language or library, but finding an application that can actually provide complete round-trip Software Engineering support.
TheOpen Source software model enjoys developer support for UML modeling tools because "UML defines a semantic metamodel, not a tool interface, storage, or run-time model, although these should be fairly close to one another" (OMG, 1997, paragraph 13). The reality of Open Source tools is that most often fall short of just having an idea of what the tool should accomplish and remain in a state of incomplete development or are poorly maintained. Some tools are designed for platform independence so deployment ease has restricted the tools programming language to Java. The remaining tools target a specific operating system and a few provide extensive design support to the Software Development Life Cycle.
Dia and UML
Dia isa platform independent application for UML modeling based on the UML 1.2 specification. The application was originally developed as a Linux alternative to Microsoft Visio and provides extensive support to the entire system design process. The tool isn't a formal UML application though and can only be used to depict system Activity, Use Case, Collaborative, and Component diagrams.
Accordingto Eriksson and Penker (1998, p.35-36), Dia is a modern CASE tool because it provides functions for drawing diagrams, acts as a repository, supports model navigation, and covers the model at all abstraction levels. It doesn't meet the specifications of an advanced tool though, as it provides no functionality for code generation, reverse engineering, secondary CASE tool integration, and contains no interchangeable CASE tool models. The tool is invaluable to Open Source system modeling through its ease of use and navigation simplicity.
Diawas used to model a University Library System Use Case scenario, see Figure 2, and a partial Class diagram of the same system, see Figure 3. Any formal version of the UML specification can be modeled via Dia as long as the user remains within the constraints of that particular specification. Dia's functionality also includes the support of any formal component specification, see figure 4.
 Figure 2. Dia Library System Use-Case Diagram. |
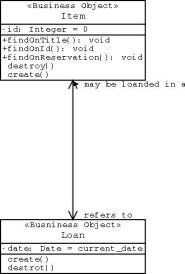 Figure 3. Dia Class Diagram |
 Figure 4. Dia Component Diagram |
kUML
kUML is an Open Source UML solution specifically designed for the Linux SuSe 6.2 operating system. kUML was developed to supports the UML 1.3 specification and is limited to the depiction of Use-Case and Class diagramming only. Like many Open Source products, configuration is the biggest hurdle to overcome as installation relies on the ability of the user for it to work correctly. Since the tool was developed on SuSe 6.2, it was optimized to run on that Linux variant, but. kUML can be installed on any Linux operating system variant with the appropriate KDE and QT libraries installed or that uses RedHat's package management (RPM) scheme as long as two extra SuSe specific RPMs are also installed (libcms.so.1 and libmng.so.0). The weakness of this tools lies with its immaturity, lack of developers, and functionality. Although the developers tout it as having successfully importing over 1200 classes relating to the kOffice project, the application consistently "core dumps" upon functionality stress testing.
kUML's strengths lie in its support of the UML specification. The tool took portions of the specification and focused on development of that portion. Class diagrams are effortlessly created, see Figures 5, and manipulated, see Figure 6, to mirror the system to be designed. Functions, attributes, and abstraction can be diagrammed to meet the design specification. The tool isn't very usable yet, but if kUML matures it will provide Open Source developers with a tool promoting effective software engineering techniques.
 Figure 5. kUML Classdiagramming functionality. |
 Figure 6. kUML Class attribute editing functionality. |
ArgoUML
TheOpen Source software model receives extended satisfaction of UML specification 1.3 with Tigris' ArgoUML CASE tool. The tool is a platform independent Java application written entirely in Java 1.2 and the Java Foundation Class while remaining compliant with OMG Standard for UML (Tigris, 2001). ArgoUML provides for complete system and component modeling of any project through a manipulative user interface. Class diagramming, see Figure 7, is intuitive and dependencies easily mapped to associated classes. The Open Source community has been given total UML support by Tigris and can easily migrate from programming-in-the-small to programming-in-the-large.
 Figure 7. ArgoUML Classdiagramming. |
Industrialsize diagramming is easily accomplished through the tools cognitive support features. It maintains a dynamic "To Do" list during the design process and suggests possible improvements based on completed diagramming. ArgoUML has one of the strongest Open Source modeling environments available due to its ability to offer multiple, overlapping diagrams that provide the designer with a full overview of their project. Throughout the design process skeleton Java code is maintained for generation whenever the design process is complete. Open Source modeling environments normally have several development cycles to progress through before they offer the software engineer a productive modeling environment, while ArgoUML provides the necessary interface for complete CASE tool support of a development project.
xFig
xFigis one of the weakest Open Source UML tools available. It provides almost no interface for the system designer to integrate their project into and is hard to manipulate. The tool contains a limited number of UML notations supporting Use-Case, Activity, and Class diagramming. xFig is an old X11 vector-drawing package that inherited UML notation diagrams due to no other Open Source packing having this functionality. Basic system design can be accomplished with xFig, but various other applications exist that provide significant improvements over what xFig can offer a software engineer. Fault for xFig's lack in functionality, isn't that of the tool or it's designers though, as with many Open Source development projects there was a need at one time for UML diagramming by a user who wrote UML notation support into the product. But its functionality for UML support is over as tools like Dia and ArgoUML have matured to support a wider range of system design requirements.
OpenTool 3.1
OpenTool 3.1 is a powerful platform independent UML modeling tool based on UML version 1.3 that also provides a complete system development solution package. The strengths of the tool lie in its ability to generate source code, in C++, Smalltalk, or Java, documentation generation, and reverse engineering for Java applications. UML diagramming support includes Package, Class, Sequence, State, Use-Case, and Collaboration diagrams. The tools ability to support the Open Source Model lies in its low-cost and complete package integration. The tool itself goes against the Open Source criteria, as it's a proprietary product but it allows development on Linux, Solaris, and Windows machines. This fact extends the tools appeal considerably.
Conclusion
Themain stumbling block for the Open Source community is convincing more developers to start looking at the bigger picture. Through tool promotion UML can be easily integrated into projects to lower development time and shorten the projects deployment timeline.
Recentproposals by Martin Fowler that the nature of design is dieing, (Fowler, 2001, p.43-46) are not unfounded as programming techniques evolve toward Extreme Programming (XP), a process that extends the software development back to an evolutionary design rather than a planned design process. XP's ability to consistently keep code as clear and simple as possible while maintaining knowledge of design patterns and then using this knowledge only where it is required.
Asignificant problem with Open Source UML support is the choice to support the UML 1.2 specification while many propriety vendors support UML 1.4 or are preparing their tools for the UML 2.0 specification. "UML 1.3 was the first mature release of the modeling language specification" (Kobryn, 1999, p.36) and although specification leading up to UML 1.2 were immature, developers should use a tools supporting the most mature specification possible. By failing to conform to the newest UML design standards Open Source projects will never support improved architectural alignment with other OMG modeling standards, remain harder to understand and not support mainstream component architectures like Entity Java Beans or COM+.
The Open Source software model is a viable alternative for the software engineering community. It has existed for over 30 years and is easily adapted to continually changing requirements with the integration of UML CASE tool support while making allowances for impending technological changes.
References
Behlendorf, B. (1999, January) Open Sources: Voices from the Open Source Revolution. Retrieved February 10, 2001 from the World Wide Web: www.oreilly.com/catalog/opensources/book/brian.html
Bezrouov, N. (2001). Open Source Software: Development as a Special Type of Academic Research (Critique of Vulgar Raymondism). Retrieved February 11, 2001 from the World Wide Web: www.firstmonday.dk/issues/issue4_10/bezroukov/
Erriksson, H., & Penker, M. (1998). UML Toolkit. New York. John Wiley & Sons.
Fowler, M. (2001, April). Is Design Dead?. Software Development Vol. 9, No. 4, 43-46.
Godfrey, M.W. & Tu, Q. (2000). Evolution in Open Source Software: A Case Study. Proceedings of the International Conference on Software Maintenance (ICSM-00), IEEE, 3. 1063-6773.
Kobryn, C. (1999, October). UML 2001: A Standardization Odyssey. Communications of the ACM, Vol.42, No.10, 29-37.
LinuxCare. (2000, February). Demystifying Open Source: How Open Source Software Development Works. Retrieved February 15, 2001 from the World Wide Web: www.linuxcare.com
Malik, S. & Palencia, J.R. (1999, December 6). Synchronize and Stabilize vs. Open-Source. (Computer Science 95.314A Research Report). Ottawa, Ontario, Canada: Carleton University, Computer Science.
O'Brien, M. (2001, January). Linux, the Big $, and Mr. Protocol. Server/Workstation Expert. 20.
Object Modeling Group. (2001). Retrieved February 15, 2001 from the World Wide Web: www.omg.org
Object Modeling Group. (1997). Press Release. Retrieved February 15, 2001 from the World Wide Web: www.omg.org/news/pr97/umlprimer.html
Schach, S.R. (1998). Classical and Object-Oriented Software Engineering: With UML and C++. 4th ed. WCB/McGraw-Hill.
Tigris.org. (2001). ArgoUML Features. Retrieved February 19, 2001 from the World Wide Web: http://argouml.tigris.org/features.html
UML. (2001). UML Notes. Retrieved March 11, 2001 from the World Wide Web: www.lut.ti/~hevi/uml/projects
James GilliamThe awk programming language often gets overlooked in the face of Perl, which is a more capable language. However, awk is found even more ubiquitously than Perl, has a less steep learning curve than Perl, and can be used just about everywhere in system monitoring scripts where efficiency is key. This brief tutorial is designed to help you get started in awk programming.
The awk language is a small, C style language which was designed for the processing of regularly formatted text. This usually includes database dumps and system log files. It's built around regular expressions and pattern handling, much like Perl is. In fact, Perl is considered to be a grandchild of the awk language.
The funny name of the awk language is due to the names of its original authors, who were Alfred V. Aho, Brian W. Kernighan, and Peter J. Weinberger. Most of you will recognize the name of Kernighan, one of the fathers of the C programming language and a major force in the UNIX world.
This is how I began using awk, to print specific fields in output. This would work surprisingly well, but the efficiency went through the floor when I was writing large scripts that took minutes to complete.
But, here you go, this can be useful sometimes:
ls -l /tmp/foobar | awk '{print $1"\t"$9}'
What this will do is take some input like this:
-rw-rw-rw- 1 root root 1 Jul 14 1997 tmpmsg
and will generate some output like this:
-rw-rw-rw- tmpmsg
Quite intuitive what it just did, it printed only the first and ninth fields. Now you can see why it's so popular for one line data extraction. But, let's move on to a full fledged awk program.
One of my favorite things about awk is the amazing readability of it, despite it's power compared to Perl or Python. Every awk program has three parts: a BEGIN block, which is executed once before any input is read; a main loop which is executed for every line of input; and an END block, which is executed after all of the input is read. Quite intuitive! Yes, I'll keep saying that about awk, because i find it to be very true.
This is a very simple awk program highlighting some of the features of the language. See if you can pick out what is happening before we dissect it:
#!/usr/bin/awk -f
#
# check the sulog for failures..
# copyright 2001 (c) jose nazario
#
# works for Solaris, IRIX and HPUX 10.20
BEGIN {
print "--- checking sulog"
failed=0
}
{
if ($4 == "-") {
print "failed su:\t"$6"\tat\t"$2"\t"$3
failed=failed+1
}
}
END {
print "---------------------------------------"
printf("\ttotal number of records:\t%d\n", NR)
printf("\ttotal number of failed su's:\t%d\n",failed)
}
Have you figured it out yet? Would it help to know the format of a typical line of the input file (sulog, from, say, IRIX)? Here's a typical pair of lines:
SU 01/30 13:15 - ttyq1 jose-root
SU 01/30 13:15 + ttyq1 jose-root
OK, read up and see if you can figure out the script. The BEGIN block sets everything up, printing out a header and initializing our one variable (in this case failed) to zero. The main loop then reads each line of input (which is the sulog file, a log of su attempts) and compares field four against the minu sign. If they match, it is because the attempt failed, so we increment out counter by one and note which attempt failed and when. At the end final tallies are presented, showing the total number of lines of input as the number of records (NR, an internal awk variable) and the number of failed su attempts we noted. Output looks like this:
failed su: jose-root at 01/30 13:15
---------------------------------------
total number of records: 272
total number of failed su's: 73
You should also be able to see how printf works, almost exactly like the printf does in C. In short, awk is a rather intuitive language.
By default the field separator is whitespace, but you can tweak that. In password files I set it to be a colon. This small script looks for users with an ID of 0 (root equivilent) and no passwords:
#!/usr/bin/awk -f
BEGIN { FS=":" }
{
if ($3 == 0) print $1
if ($2 == "") print $1
}
Other internals from awk to know and use are RS for record separator (defaults to a newline, or \n), OFS for output field separator (defaults to nothing, I think) and ORS (defaults to a newline), for output record separator. These can all be set within the script, of course.
The awk language matches normal regular expressions that you have come to know and love, and does so better than grep. For instance, I use the following awk search pattern to look for the presence of a likely exploit on Intel Linux systems:
#!/usr/bin/awk -f
{ if ($0 ~ /\x90/) print "exploit at line " NR }
You can't look for hex value 0x90 in grep, but 0x90 is popular in Intel exploits -- its the NOP call, which is used as padding in shellcode portions.
You can look for hex values using \xdd, where dd is the hex number to look for; you can look for decimal (ie ASCII) values by looking for \ddd, using the decimal value, and regular expressions based on text will, of course, work.
Random numbers in awk are readily generated, but there is an interesting caveat. The rand() function does exactly what you would expect it to, it returns a random number, in this case between 0 and 1. You can scale it, of course, to get larger values. Here's some example code to show you this, as well as an interesting bit of behavior:
#!/usr/bin/awk -f
{
for(i=1;i<=10;i++)
print rand(); exit
}
Run that a couple of times and you will see a problem: the random numbers are hardly random, they repeat every time you run it!
So what's the problem? Well we didn't seed the random number generator. Normally, we're used to our random number generator pulling entropy from a good source, like (in Linux) /dev/random. However, awk doesn't do this. To really get random numbers, we should seed our random number generator. This improved code will do this:
#!/usr/bin/awk -f
BEGIN {
srand()
}
{
for(i=1;i<=10;i++)
print rand(); exit
}
The seeding of the random number generator in the BEGIN block is what does the trick. The function srand() can take an argument, and in the absence of one the current date and time is used to seed the generator. Note that the same seed will always produce the same 'random' sequence.
This isn't the most detailed intro to awk you will find, but I hope that it is more clear to you how to use awk in a program setting. Myself, I'm quite happy programming in awk, and I've got a lot more to learn.
We haven't even touched upon arrays, self built functions or other complex language features, but suffice it to say awk is hardly Perl's little brother.
Go forth and awk!
Kernighan's homepage contains a list of good awk books as well as the source for the 'one true awk', aka "nawk". It also contains a host of other interesting links and information from Kernighan.
http://cm.bell-labs.com/who/bwk/
The standard awk implementation, nawk (for "new awk", as opposed to the "old awk, sometimes found as 'oawk' for compatability), is based on the POSIX awk definitions, and contains a few functions that were introduced by two other awk implementations, gawk and mawk. I usually keep this one around as 'nawk' and use it to test the portability of my awk scripts. This one is usually found on my commercial UNIX machines, where I often don't have gawk installed.
Source for nawk: http://cm.bell-labs.com/who/bwk/awk.tar.gz
The GNU project's awk, gawk, is also based on the POSIX awk standard, but adds a significant number of useful features, as well. These include command line features like 'lint' checking and reversion to struct POSIX mode. My favorite feature in gawk is the line breaks, using '\', and the extended regular expressions. The gawk documentation has a complete discussion of GNU extensions to the awk language. This is also the standard awk on Linux and BSD systems.
Source for gawk: ftp://gnudist.gnu.org/gnu/gawk/gawk-3.0.6.tar.gz (the GNU Project's version of awk)
This is perhaps the most popular book on these two small programs, and is highly regarded. It contains, among other things, a discussion of popular awk implementations (ie gawk, nawk, mawk), a great selection of functions and the usual O'Reilly readability. The awk homepage lists several other books on the awk programming language, though this one remains my favorite.
The sed & awk book: http://www.oreilly.com/catalog/sed2
Jose NazarioRecently I was discussing with a friend how to use SSH to achieve secure, passwordless authentication. He was looking for a way to automate some file transfers and wanted to do it using an expect script (to pump in his passphrase when prompted) to automate the process. I suggested 'ssh-agent', but didn't know quite how to make it work at the time. Since then, I've learned, and it's quite easy.
Using the agent for key based authentication is a method to facilitate communications. You can use key based authentication without the agent, you just have to unlock the key every time you want to use it. Note that by default the ssh client will attempt to authenticate using keys before a password. The agent just makes management of this much easier.
There are several implementations of the ssh protocol, each with its own peculiarities of usage and behavior. The two most common implementations are from openssh.org) and ssh.com). OpenSSH was created for OpenBSD and is thus free software. ssh.com's ssh is a commercial product that is no-cost for open-source operating systems (and for trial, non-commercial and educational use on other OSes). Each implementation of ssh has some slight peculiarities of usage and behavior.
As if multiple implementations weren't enough, there are also two ssh protocols, SSH1 and SSH2. This article focuses on using the SSH1 protocol, which differs slightly from the SSH2 protocol. Previous articles in Linux Gazette have introduced the use of ssh-agent for ssh2 (see below). Note that, by default, ssh2 uses DSA keys, and different directory and file names from ssh1, though compatability can be introduced. Since most people use the SSH1 protocol (data from recent University of Alberta Internet scans using 'scan-ssh'), we will focus on this version. OpenSSH follows, almost perfectly, the syntax of the ssh.com ssh1 program for agent based key management. Note that it differs for ssh2 handling (not covered here).
The benefits of RSA based authentication are numerous, frankly:
Hence, I can't think of any reason (other than not knowing how, which this document is trying to teach you) why you shouldn't use it.
First up, our cast of characters. These are the components that play in this whole thing, so get to know them:
-rw------- 1 jose users 530 Feb 8 12:14 identity
-rw------- 1 jose users 334 Feb 8 12:14 identity.pub
Before we begin, let's make sure the target server allows RSA key based authentication:
$ grep RSA /etc/sshd_config
RSAAuthentication yes
If that says 'no', then this whole thing is moot. Speak to your administrator if you need to.
We use ssh-keygen to generate the keypair. A typical session looks like this:
$ ssh-keygen
Initializing random number generator...
Generating p: ............................++ (distance 446)
Generating q: ...............++ (distance 168)
Computing the keys...
Testing the keys...
Key generation complete.
Enter file in which to save the key (/home/jose/.ssh/identity):
Enter passphrase: (not echoed)
Enter the same passphrase again: (not echoed)
Your identification has been saved in /home/jose/.ssh/identity.
Your public key is:
1024 37 13817424072879097025507991426858228764125028777547883762896424325959758548762313498731030035107110571218764165938469063762187621357098158111964592318604535627188332685173064165286534140697800110207412449607393488437570247411920664869426605834174366309317794215856900173541953917001003859838421924037121230161484169444067380979 jose@biocserver
Your public key has been saved in /home/jose/.ssh/identity.pub
So, now we have the two pieces we need, our public and private keys. Now, we have to distribute the public key. This is just like PGP, frankly, you can share this with anyone, then you can login without any hassle. I'll use 'scp' to copy it over:
$ scp .ssh/identity.pub jon2@li:~/.ssh/biocserver.pub
jon2@li's password:(not echoed)
identity.pub | 0 KB | 0.3 kB/s | ETA: 00:00:00 | 100%
Having copied it there, I will now login to the target machine (in this case the SCL machine 'li') and add it to the list of keys that are acceptable:
li$ cat biocserver.pub >> authorized_keys
OK, now li is all set to let me authenticate using my RSA private key I generated above. Let's go back to my client machine and set up ssh-agent. First, before I invoke the agent, let's look at a couple of environmental variables in my shell:
$ env | grep -i SSH
SSH_TTY=/dev/ttyp3
SSH_CLIENT=129.22.241.148 785 22
Now let's invoke ssh-agent properly. It starts a subshell, so you have to tell it what shell to invoke so it can set it up right.
$ ssh-agent /bin/bash
And it's now set up my environment correctly:
$ env | grep -i SSH
SSH_TTY=/dev/ttyp3
SSH_AGENT_PID=3012
SSH_AUTH_SOCK=/tmp/ssh-jose/ssh-3011-agent
SSH_CLIENT=129.22.241.148 785 22
The two new variables, SSH_AGENT_PID and SSH_AUTH_SOCK, will allow the agent and accessory applications (ie the ssh client, the cache loading tool ssh-add, and such). The sockets are just regular files in the /tmp directory:
$ ls -l /tmp/ssh-jose/
total 0 srwx------ 1 jose users 0 Apr 24 13:36 ssh-3012-agent
So, now that the agent is properly set up, load the cache with your private key. Remember, the agent communicates with the client to hand off your private key when you want to authenticate. Invoking it without any arguments assumes the standard, default private keyfile:
$ ssh-add1
Need passphrase for /home/jose/.ssh/identity (jose@biocserver).
Enter passphrase:(not echoed)
Identity added: /home/jose/.ssh/identity (jose@biocserver)
The passphrase you use here is to ensure "yes, it's me, I have a right to use this key", and it's the same passphrase you set up above when you ran ssh-keygen. Now that the key is loaded, let's look at the cache, using the -l (for 'list') option to ssh-add:
$ ssh-add -l
1024 37 11375588656963284515711893546976216491501314848762129298719958615531627297098741828662897623987120978747144865157469714395736112700558601876305400606604871996923286317135102021232606807975642627653113389875325214757393348628533138103638880715659452391252482099813547642625002508937138181011315411800330612532401318392577 jose@biocserver
Now, when you ssh to another host, you will not get prompted for a passphrase, the private key would have been used as your authenticator using ssh-agent!
$ ssh -l jon2 li
Last login: Tue Apr 24 14:53:39 2001 from biocserver.bioc.
You have mail.
bash-2.03$
Look, Mom, no passphrase needed!
Note that you can alter the above, if you would like, to add some flexibility. First, you can use the output of the ssh-agent program (when invoked without a shell argument), to modify the current shell and set up the agent socket for communication:
$ eval `ssh-agent`
Agent pid 19353;
Now you can add keys as described above, and you have not started a subshell, only having modified the login shell you are currently using. The eval and backticks combination is needed to handle the output that the agent presents to modify the shell. This is because child processes cannot modify the parent shell's parameters.
A second modification you can do is to start your X desktop, such as GNOME or KDE, as the argument to ssh-agent. This will cause every X client locally started to be aware of how to communicate with the agent, allowing for greater ease when you use terminals to log in to other hosts.
That said, you can unload specific keys using ssh-add's '-d' flag, or you can unload all of them using the '-D' flag:
$ ssh-add -D
All identities removed.
This is a good thing to do when you walk away from your workstation. It'd be neat to have a small idle timeout feature, or link this into the screensaver command on your system, or an APM suspend on your laptop.
$ ssh-agent
SSH_AUTH_SOCK=/tmp/ssh-jose/ssh-3019-agent; export SSH_AUTH_SOCK;
SSH_AGENT_PID=3020; export SSH_AGENT_PID;
echo Agent pid 3020;
Let's have a look and see if the correct environmental variables have been set in our shell. These are needed for the agent to work properly, as we saw above:
$ env | grep -i ssh
SSH_TTY=/dev/ttyp3
SSH_CLIENT=129.22.241.148 785 22
The consequences of this are evident when you try and add keys to the cache:
$ ssh-add
Need passphrase for /home/jose/.ssh/identity (jose@biocserver).
Enter passphrase: (not echoed)
Could not open a connection to your authentication agent.
It can't find the socket or the process ID, which is stored in this variable. As such, no keys are available in the cache.
Jose NazarioI finally decided to get Perl installed into PostgreSQL because PostgreSQL has all the features I like :
The overall process was a pain because of slight adjustments here and there. . Here are the basic steps:
cd /usr/local/src lynx --source http://www.tcu-inc.com/perl5.6.1.tgz > perl-5.6.1.tgz tar -zxvf perl-5.6.1.tgz cd perl-5.6.1 rm -f config.sh Policy.sh sh ConfigureChange the default prefix to "/usr" instead of "/usr/local". Also, when it asks the question "Build a shared libperl.so (y/n) [n] ", answer y. Press enter for any other question.
make make install
Tcl and Perl are options in the procedural languages. You can actually execute Perl and Tcl inside sql commands. Also, you get the standard PL/pgSQL procedural language (which is similar to pl/sql). Here are the steps I used to install PostgreSQL with Perl. Here is a text file with the same information.
### First of all, you have to compile Perl as a dynamic module. ### If you haven't done this, you should be able to install postgresql, ### but it won't have the plperl interface. cd /usr/local/src lynx --source ftp://postgresql.readysetnet.com/pub/postgresql/v7.1.1/postgresql-7.1.1.tar.gz > postgresql-7.1.1.tar.gz tar -zxvf postgresql-7.1.1.tar.gz cd postgresql-7.1.1 ### We need to set some environment variables -- which should be put #### into ~/.profile for the user postgres for the future. PATH=/usr/local/pg711/bin:$PATH export PATH export LD_LIBRARY_PATH=/usr/local/pg711/lib export PGDATA=/usr/local/pg711/data export PGLIB=/usr/local/pg711/lib export POSTGRES_HOME=/usr/local/pg711 ### This script is setup to delete any previous installation. ### I did this so that I could debug it if it didn't work the first time. #### Ignore any error message saying the database server is not running. You ### probably don't have one running. su -c '/usr/local/pg711/bin/initdb -D /usr/local/pg711/data -l logfile stop' postgres ### Ignore any error message saying this user exists. adduser postgres rm -rvf /usr/local/pg711 ### Now let us make the destination directory have postgres own it. mkdir /usr/local/pg711 chown postgres /usr/local/pg711 ### Ignore any make clean errors here. make clean ### Compile and install postgresql. ./configure --prefix=/usr/local/pg711 --with-perl --with-tcl --with-CXX --with-python --enable-odbc make make install ### Now we need to install the perl interface for postgresql. gmake -C src/interfaces/perl5 install cd /usr/local/src/postgresql-7.1.1/src/interfaces/perl5 perl Makefile.PL make ### Uncomment the next line if you want to test it. ## su -c 'make test' postgres make install ### Change ownership of all files to the user postgres. chown -R postgres /usr/local/pg711 ### Initialize the database. su -c '/usr/local/pg711/bin/initdb -D /usr/local/pg711/data' postgres ### Start the database server. su -c '/usr/local/pg711/bin/pg_ctl -D /usr/local/pg711/data -l logfile start' postgres ### The interfaces for perl, tcl, and pl/pgsql should have been created. ### Now add them. su -c 'createlang plpgsql template1' postgres su -c 'createlang pltcl template1' postgres ### Now assuming you have perl 5.6.1 installed correctly. rm -f /usr/local/pg711/lib/libperl.so ln -s /usr/lib/perl5/5.6.1/i686-linux/CORE/libperl.so \ /usr/local/pg711/lib/libperl.so su -c 'createlang plperl template1' postgres ### If it worked out correctly, any new database will copy itself from ### template1 and have perl, tcl, and pl/pgsql. ### Now additional stuff. su -c 'createdb postgres' postgresIn the home directory of the user postgres, make a file called ".profile" and put this in it.
#!/usr/bin PATH=/usr/local/pg711/bin:$PATH export PATH export LD_LIBRARY_PATH=/usr/local/pg711/lib export PGDATA=/usr/local/pg711/data export PGLIB=/usr/local/pg711/lib export POSTGRES_HOME=/usr/local/pg711Then, execute this command,
chmod 755 .profile
Since I had you create the database "postgres", all you have to do is enter these two commands starting as the user "root" to get into the psql interface.
su -l postgres psqlThis assumes you also correctly setup .profile for the user postgres. If you didn't, then follow these commands:
su -l postgres PATH=/usr/local/pg711/bin:$PATH export PATH export LD_LIBRARY_PATH=/usr/local/pg711/lib export PGDATA=/usr/local/pg711/data export PGLIB=/usr/local/pg711/lib export POSTGRES_HOME=/usr/local/pg711 psql
The following function lets you search the data and return a copy of the name if the name contains the text you search for with a case insensitive option.
drop function search_name(employee,text,integer);
CREATE FUNCTION search_name(employee,text,integer) RETURNS text AS '
my $emp = shift;
my $Text = shift;
my $Case = shift;
if (($Case > 0) && ($emp->{''name''} =~ /\\Q$Text\\E/i))
{ return $emp->{''name''}; }
elsif ($Case > 0) {return "";}
elsif ($emp->{''name''} =~ /\\Q$Text\\E/)
{ return $emp->{''name''}; }
else { return "";}
' LANGUAGE 'plperl';
insert into EMPLOYEE values ('John Doe',10000,1);
insert into EMPLOYEE values ('Jane Doe',10000,1);
insert into EMPLOYEE values ('Giny Majiny',10000,1);
select name,search_name(employee,'j',0) from employee;
select name,search_name(employee,'j',1) from employee;
select name from employee where search_name(employee,'j',1) = name;
select name from employee where search_name(employee,'j',0) = name;
Obviously, the function is a little ridiculous. It should just return 0 for false or 1 for true. But for visual reasons, I have it return a copy of name.
Below, I have three tables: jobs, jobs_backup, and contact. I will only create stored procedures for the table 'jobs'. The two perl procedures are only meant to verify that we have valid data to input, and to filter out non-printable characters, and get rid of whitespace. We use pl/pgsql to perform the actual insert, update, and delete commands.
Using this basic method of handling data, you can replicate it for any other table you have.
Some things I have to watch out for is the fact I want unique names for the jobs. I don't want two jobs to have the same name from one recruiter. This gets a little tricky, but it works fine.
Also, I could use a foriegn key restraint so that you cannot have a contact_id in 'jobs' without it existing in 'contact'. The only problem is, we may at some point accidentally delete contact_ids from contact and then things are messed up anyways. The best solution is to add a "active" column to the "jobs" and "contact" tables in which you turn off and on objects. In this way, you never delete unique ids ever.
--- Create the jobs table.
--- a good suggestion would be to have a foriegn key constraint
--- with the table contact.
create sequence Job_Sequence;
drop table jobs;
create table jobs (
job_id int4 unique DEFAULT nextval('Job_Sequence'),
contact_id int4,
job_no int4,
job_name text,
job_location text
);
CREATE UNIQUE INDEX job_index ON jobs (job_name, contact_id);
-- This is a real backup table.
-- Everytime a changes occur, insert it into this table.
-- This isn't just for deletes, but for inserts and updates.
-- This becomes a history table, not just a backup.
-- We even record the final output.
create sequence Backup_Job_Sequence;
drop table jobs_backup;
create table jobs_backup (
backup_id int4 unique DEFAULT nextval('Backup_Job_Sequence'),
action text CHECK (action in ('insert','update','delete','')),
error_code int4,
job_id int4,
contact_id int4,
job_no int4,
job_name text,
job_location text
);
create sequence Contact_Sequence;
drop table contact;
create table contact (
contact_id int4 UNIQUE DEFAULT nextval('Contact_Sequence'),
name text unique,
phone text,
website text
);
--- Insert two values for contacts.
--- I am not making stored procedures for this table, just jobs.
insert into contact (name,phone,website)
values ('Mark Nielsen','(408) 891-6485','http://www.gnujobs.com');
insert into contact (name,phone,website)
values ('Joe Shmoe','(1234) 111-1111','http://www.gnujobs.net');
insert into contact (name,phone,website)
values ('Lolix.org','(12345) 111-1111','http://www.lolix.org');
--- Select info from contact to see if it is there.
select * from contact;
--- Let use create perl function (which is probably not needed)
--- which will verify if inputted data in not blank.
drop function job_values_verify (int4,text,text);
CREATE FUNCTION job_values_verify (int4,text,text) RETURNS int4 AS '
my $Contact_Id = shift;
my $Job_Name = shift;
my $Job_Description = shift;
my $Error = 0;
if ($Contact_Id < 1) {$Error = -100;}
if (!($Job_Name =~ /[a-z0-9]/i)) {$Error = -101;}
if (!($Job_Description =~ /[a-z0-9]/i)) {$Error = -102;}
return $Error;
' LANGUAGE 'plperl';
drop function clean_text (text);
CREATE FUNCTION clean_text (text) RETURNS text AS '
my $Text = shift;
# Get rid of whitespace in front.
$Text =~ s/^\\s+//;
# Get rid of whitespace at end.
$Text =~ s/\\s+$//;
# Get rid of anything not text.
$Text =~ s/[^ a-z0-9\\/\\`\\~\\!\\@\\#\\$\\%\\^\\&\\*\\(\\)\\-\\_\\=\\+\\\\\\|\\[\\{\\]\\}\\;\\:\\''\\"\\,\\<\\.\\>\\?\\t\\n]//gi;
# Replace all multiple whitespace with one space.
$Text =~ s/\\s+/ /g;
return $Text;
' LANGUAGE 'plperl';
-- Just do show you what this function cleans up.
select clean_text (' ,./<>?aaa aa !@#$%^&*()_+| ');
--
drop function insert_job (int4,text,text);
CREATE FUNCTION insert_job (int4,text,text) RETURNS int2 AS '
DECLARE
c_id_ins int4; j_name_ins text; l_ins text;
job_id1 int4; oid1 int4; test_id int4 := 0; j_no_ins int4 := 0;
record1 RECORD; record2 RECORD; record3 RECORD; record4 RECORD;
BEGIN
j_name_ins := $2; l_ins := $3; c_id_ins := $1;
-- We execute a few Perl procedures now. These are just examples
-- of Perl procedures.
-- Clean the name of the job.
SELECT INTO record4 clean_text(j_name_ins) as text1;
j_name_ins = record4.text1;
-- Clean the location of the job.
SELECT INTO record4 clean_text(l_ins) as text1;
l_ins = record4.text1;
-- Verify the values we insert are okay.
SELECT INTO record4 job_values_verify (c_id_ins, j_name_ins, l_ins) as no;
IF record4.no < 0 THEN return (record3.no); END IF;
-- See if we have unique names, otherwise return 0.
FOR record1 IN SELECT job_id FROM jobs
where contact_id = c_id_ins and job_name = j_name_ins
LOOP
test_id := record1.job_id;
END LOOP;
-- If the job_id is null, great, otherwise abort and return -1;
IF test_id > 0 THEN return (-1); END IF;
FOR record3 IN SELECT max(job_no) from jobs_backup where contact_id = c_id_ins
LOOP
IF record3.max IS NULL THEN j_no_ins := 0; END IF;
IF record3.max > -1 THEN j_no_ins = record3.max + 1; END IF;
END LOOP;
-- Insert the stuff. Let the sequence determine the job_id.
insert into jobs (contact_id, job_no, job_name, job_location)
values (c_id_ins, j_no_ins, j_name_ins, l_ins);
-- Get the unique oid of the row just inserted.
GET DIAGNOSTICS oid1 = RESULT_OID;
-- Get the job id. Do not use SELECT INTO, since record2 needs to be assigned.
FOR record2 IN SELECT job_id FROM jobs where oid = oid1
LOOP
job_id1 := record2.job_id;
END LOOP;
-- If job_id1 is NULL, insert failed or something is wrong.
IF job_id1 is NULL THEN return (-2); END IF;
-- It should also be greater than 0, otherwise something is wrong.
IF job_id1 < 1 THEN return (-3); END IF;
-- Everything has passed, return job_id1 as job_id.
insert into jobs_backup (contact_id, job_no, job_name, job_location, action, error_code)
values (c_id_ins, j_no_ins, j_name_ins, l_ins, ''insert'', job_id1);
return (job_id1);
END;
' LANGUAGE 'plpgsql';
select insert_job (1,'Job Title 1','Boston, MA');
select insert_job (1,'Job Title 2','San Jose, CA');
select insert_job (2,'Job Title 1','Columbus, Ohio');
select insert_job (2,'Job Title 2','Houston, TX');
select insert_job (3,'Job Title 1','Denver, CO');
select insert_job (3,'Job Title 2','New York, NT');
select * from jobs;
drop function update_job (int4,text,text,int4);
CREATE FUNCTION update_job (int4,text,text,int4) RETURNS int2 AS '
DECLARE
c_id_ins int4; j_name_ins text; l_ins text;
job_id1 ALIAS FOR $4; oid1 int4; test_id int4 := 0;
record1 RECORD; record2 RECORD; record3 RECORD; record4 RECORD; record5 RECORD;
return_int4 int4 := 0; job_no1 int4 := 0;
BEGIN
j_name_ins := $2; l_ins := $3; c_id_ins := $1;
-- A few Perl procedures.
-- Clean the name of the job.
SELECT INTO record4 clean_text(j_name_ins) as text1;
j_name_ins = record4.text1;
-- Clean the location of the job.
SELECT INTO record5 clean_text(l_ins) as text1;
l_ins = record5.text1;
-- Verify the values we insert are okay.
SELECT INTO record3 job_values_verify (c_id_ins, j_name_ins, l_ins) as no;
IF record3.no < 0 THEN return (record3.no); END IF;
-- See if there is a duplicate job name for that contact.
FOR record1 IN SELECT job_id FROM jobs
where contact_id = c_id_ins and job_name = j_name_ins
and job_id != job_id1
LOOP
test_id := record1.job_id;
END LOOP;
-- If the job_id is null, great, otherwise abort and return -1;
IF test_id > 0 THEN return (-1); END IF;
-- See if the job exists, otherwise return -2.
FOR record1 IN SELECT * FROM jobs where job_id = job_id1
LOOP
update jobs set contact_id = c_id_ins,
job_name = j_name_ins, job_location = l_ins
where job_id = job_id1;
GET DIAGNOSTICS return_int4 = ROW_COUNT;
test_id := 1;
job_no1 := record1.job_no;
END LOOP;
-- If the job does not exist, what are we updating? return error.
IF test_id = 0 THEN return (-2); END IF;
-- Everything has passed, return return_int4.
insert into jobs_backup (contact_id, job_no, job_name, job_location, action, error_code, job_id)
values (c_id_ins, job_no1, j_name_ins, l_ins, ''update'', return_int4, job_id1);
return (return_int4);
END;
' LANGUAGE 'plpgsql';
select update_job (3,'Changing title and owner.','Boston, MA',1);
select * from jobs;
-- You should get an error on this one because you are duplicating name
-- and contact id.
select update_job (3,'Changing title and owner.','Boston, MA',1);
drop function delete_job (int4);
CREATE FUNCTION delete_job (int4) RETURNS int2 AS '
DECLARE
job_id1 ALIAS FOR $1;
job_exists int4 := 0;
job_backup_exists int4 := 0;
record1 RECORD;
return_int4 int4 :=0;
BEGIN
-- If the job_id1 is not greater than 0, return error.
IF job_id1 < 1 THEN return -1; END IF;
-- If we find the job, delete it, record we found it, and back it up.
-- I do not like using LOOP for one row, but I use it for a reason.
FOR record1 IN SELECT * FROM jobs where job_id = job_id1
LOOP
delete from jobs where job_id = job_id1;
GET DIAGNOSTICS return_int4 = ROW_COUNT;
job_exists := 1;
insert into jobs_backup (contact_id, job_no, job_name, job_location, action, error_code, job_id)
values (record1.contact_id, record1.job_no, record1.job_name,
record1.job_location, ''delete'', return_int4, record1.job_id);
END LOOP;
-- If job_exists == 0, Return error.
-- It means it never existed.
IF job_exists = 0 THEN return (-1); END IF;
-- We got this far, it must be true, return ROW_COUNT.
return (return_int4);
END;
' LANGUAGE 'plpgsql';
select delete_job (1);
select * from jobs;
--- We already deleted it, we should get an error this time.
select delete_job (1);
Here is a summary of the things you should consider:
First, of all, add this method right below the "permit" method in Safe.pm. My Safe.pm was at /usr/local/src/perl-5.6.1/lib/Safe.pm. Changing a module that you did not create means that if you ever update this module, the changes will get wiped. Once more, you MIGHT MESS UP THE PROGRAMMING FROM ONE OF YOUR FRIENDS WHO IS PROGRAMMING ON THAT COMPUTER AS WELL. Again, I am doing some naughty things you should not do.
sub permit_all {
my $obj = shift;
$obj->{Mask} = invert_opset full_opset;
}
Second, shut down your database server.
Third, recompile plperl with some changes.
Make these changes in the file plperl.c. From this
"require Safe; SPI::bootstrap();"
"sub ::mksafefunc { my $x = new Safe; $x->permit_only(':default');$x->permit(':base_math');"
"$x->share(qw[&elog &DEBUG &NOTICE &NOIND &ERROR]);"
" return $x->reval(qq[sub { $_[0] }]); }"
To This (which you can get from this file New_plperl.txt)
"require Safe; SPI::bootstrap();"
"sub ::mksafefunc { my $x = new Safe; $x->permit_only(':default');$x->permit(':base_math');"
"$x->permit_all('');"
"$x->share(qw[&elog &DEBUG &NOTICE &NOIND &ERROR]);"
" return $x->reval(qq[sub { $_[0] }]); }"
Now recompile plperl and install it.
cd /usr/local/src/postgresql-7.1.1/src/pl/plperl rm -f *.o make make installFourth, restart the postgresql database server.
See if you can escape to a shell,
drop function ls_bad (); CREATE FUNCTION ls_bad () RETURNS text AS ' my @Temp = `ls /tmp`; my $List = "@Temp"; $List =~ s/\n/ /g; return $List; ' LANGUAGE 'plperl'; select ls_bad();If you get the contents of your "/tmp" directory, then you can escape to a shell just fine. This is very dangerous.
For a whole day, I was trying to figure out how to get DynaLoader to work in pl/perl. Basically, I read documentation about how to embed Perl in C, and it isn't that hard to do. There is even a manpage about it. I kept on running into problems. Lastly, I tried to not use the Safe.pm module altogether, but I didn't get very far. I was so close to compiling Dynaloader into plperl, but I gave up. After blowing off a day, I want someone else to give it a try.
If you can get DynaLoader to work properly with plperl, or more accurately, you find a way to make it so I can load any module I want with plperl, then please let me know. I got to the point where I could load pure pm modules, but not modules which had c components. I would like to be able to load any module whatsoever. I believe we have to stop using Safe.pm to make it easier. Please send email to . I would be very interested if you succeed!
Please don't do this. I only wanted to show you how you can get around security issues if you really wanted to.
Mark NielsenThe Internet Revolution was founded on open systems; an open system is one whose software you can look at, a box you can unwrap and play with. It's not about secret binaries or crippleware or brother-can-you-spare-a-dime shareware. If everyone always had hidden software, you wouldn't have 1/100th the useful software you have right now.And you wouldn't have Perl.
-- Tom Christiansen
Overview
If you have been following this series, you now have a few tools - perhaps you've even experimented with them - which can be used to build scripts. So, this month we're going to take a look at actually building some, particularly by using the "open" function which allows us to assign filehandles to files, sockets, and pipes. "open" is a major building block in using Perl, so we'll give it a good long look.
Excercises
Last time, I mentioned writing a few scripts for practice. Let's take a look at a few possible ways to do that.
The first one was a script that would take a number as input, and print "Hello!" that many times. It would also test the input for illegal (non-numeric) characters. Here is a good example, sent in by David Zhuwao:
#! /usr/bin/perl -wFirst, to point out good coding practices: David has used the "-w" switch so that Perl will warn him if there are any compile-time warnings - an excellent habit. He has also used whitespace (blank lines and tabs) effectively to make the code easy to read, as well as commenting it liberally. Also, rather than checking for the presence of a number (which would create a problem with input like "1A"), he is testing for non-numerical characters and a length greater than zero - good thinking!#@author David Zhuwao
#@since Apr/19/'01print "Enter number of times to loop: ";
#get input and assign it to a variable.
chomp ($input = <>);# check the input for non-numeric characters.
if ($input !~ m/\D/ && length($input) > 0) {
for ($i = 0; $i < $input; $i++) {
print "Hello!\n";
}
} else {
print "Non-numeric input.\n";
}
Minor points (note that none of these are problems as such, simply observations): in using the match operator, "m//", the "m" is unnecessary unless the delimiter is something other than "/". As well, the Perl "for/foreach" loop would be more compact than the C-like "for" loop, while still fulfilling the function:
print "Hello!\n" for 1 .. $input;
It would also render "$i" unnnecessary. Other than those minor nits - well done, David!
Here's another way:
#!/usr/bin/perl -wUnlike David's version, mine does not print a failure message; it simply returns you to the command prompt if the input is not numeric. Also, instead of testing for non-numerical characters, I'm testing the string from its beginning to its end for only numerical content. Either of these techniques will work fine. Also, instead of using an explicit loop, I'm using Perl's "x" operator, which will simply repeat the preceding print instruction "$a" times.print "Please enter a number: ";
chomp ( $a = <> );print "Hello!\n" x $a if $a =~ /^\d+$/;
...And, One More Time...
Let's break down another one, the second suggestion from last month: a script that takes an hour (0-23) as input and says "Good morning", "Dobriy den'", "Guten Abend", or "Buenas noches" as a result (I'll cheat here and use all English to avoid confusion.)
#!/usr/bin/perl -wOn the surface, this script seems pretty basic - and, really, it is - but it contains a few hidden considerations that I'd like to mention. First, why do we need the "beginning of line" and "end of line" tests for everything? Obviously, we want to avoid confusing "1" and "12" - but what could go wrong with /1[3-8]/?$_ = <>;
if ( /^[0-6]$/ ) { print "Good night\n"; }
elsif ( /^[7-9]$|^1[0-2]$/ ) { print "Good morning\n"; }
elsif ( /^1[3-8]$/ ) { print "Good day\n"; }
elsif ( /^19$|^2[0-3]$/ ) { print "Good evening\n"; }
else { print "Invalid input!\n"; }
What could go wrong is a mis-type. Not that it matters too much in this case, but being paranoid about your tests is a good idea in general. :) What happens if a user, while trying to type "14", typed "114"? Without those "limits", it would match "11" - and we'd get a wrong answer.
OK - why didn't I use numeric tests instead of matching? I mean, after all, we're just dealing with numbers... wouldn't it be easier and more obvious? Yes, but. What happens if we do a numeric test and the user types in "joe"? We'd get an error along with our "Invalid input!":
Argument "joe\n" isn't numeric in gt at -e line 5, <> chunk 1.
As a matter of good coding practice, we want the user to see only the output that we generate (or expect); there should not be any errors caused by the program itself. A regex match isn't going to be "surprised" by non-digit input; it will simply return a 0 (no match) and pass on to the next "elsif" or "else", which is the "catchall" clause. Anything that does not match one of the first four tests is invalid input - and that's what we want reported.
Handling Files
An important capability in any language is that of dealing with files. In Perl, this is relatively easy, but there are a couple of places where you need to be careful.
# The right way
open FILE, "/etc/passwd" or die "Can't open /etc/password: $!\n";
Here are some wrong or questionable ways to do this:
# Doesn't test for the return resultBy default, files are open for reading. Other methods are specified by adding a rather obvious "modifier" to the specified filename:
open FILE, "/etc/passwd";# Ignores the error returned by the shell via the '$!' variable
open FILE, "/etc/passwd" or die "Can't open /etc/password\n";# Uses "logical or" to test - can be a problem due to precedence issues
open FILE, "/etc/passwd" || die "Can't open /etc/password: $!\n";
# Open for writing - anything written will overwrite file contents
open FILE, ">/etc/passwd" or die "Can't open /etc/password: $!\n";# Open for appending - data will be added to the end of the file
open FILE, ">>/etc/passwd" or die "Can't open /etc/password: $!\n";# Open for reading and writing
open FILE, "+>/etc/passwd" or die "Can't open /etc/password: $!\n";# Open for reading and appending
open FILE, "+>>/etc/passwd" or die "Can't open /etc/password: $!\n";Having created the filehandle ("FILE", in the above case), you can now use it in the following manner:
while ( <FILE> ) {
print; # This will loop through the file and print every line
}
Or you can do it this way, if you just want to print out the contents in one shot:
print ;
Writing to the file is just as easy:
print FILE "This line will be written to the file.\n";
Remember that the default open method is "read". I usually like to emphasize this by writing the statement this way:
open FILE, "</etc/passwd" or die "Can't open /etc/password: $!\n";
Note the "<" sign in front of the filename: Perl has no problem with this, and it makes a good visual reminder. The phrase "leaving breadcrumbs" describes this methodology, and has to do with the idea of making what you write as obvious as possible to anyone who may follow. Don't forget that the person "following" might be you, a couple of years after you've written the code...
Perl automatically closes filehandles when the script exits... or, at least, is supposed to. From what I've been told, some OSs have a problem with this - so, it's not a bad idea (though not a necessity) to perform an explicit "close" operation on open filehandles:
close FILE or die "Can't close FILE: $!\n";
By the way, the effect of the "die" function should be relatively obvious: it prints the specified string and exits the program.
Don't do this, unless you're at the last line of your script:
close;
This closes all filehandles... including STDIN, STDOUT, and STDERR (the standard streams), which leaves your program dumb, deaf, and blind. Also, you cannot specify multiple handles in one close, so you do indeed have to close them one at a time:
close Fh1 or die "Can't close Fh1: $!\n";
close Fh2 or die "Can't close Fh2: $!\n";
close Fh3 or die "Can't close Fh3: $!\n";
close Fh4 or die "Can't close Fh4: $!\n";
You could, of course, do this:
for ( qw/Fh1 Fh2 Fh3 Fh4/ ) { close $_ or die "Can't close $_: $!\n"; }
![]() That's Perl for you; There's More Than One Way To Do It...
That's Perl for you; There's More Than One Way To Do It...
Using Those Handles
Let's say that you have two files with some financial data - loan rates in one, the type and amount of your loans in the other - and you want to calculate how much interest you'll be paying, and write the result out to a file. Here is the data:
rates.txt
House 9%
Car 16%
Boat 19%
Misc 21%
loans.txt
Chevy CAR 8000
BMW car 22000
Scarab BOAT 150000
Pearson boat 8000
Piano Misc 4000
All right, let's make this happen:
#!/usr/bin/perl -wopen Rates, "<rates.txt" or die "Can't open rates.txt: $!\n";
open Loans, "<loans.txt" or die "Can't open loans.txt: $!\n";
open Total, ">total.txt" or die "Can't open total.txt: $!\n";while ( <Rates> ) {
# Get rid of the '%' signs
tr/%//d;
# Split each line into an array
@rates = split;
# Create hash with loan types as keys and percentages as values
$r{lc $rates[0]} = $rates[1] / 100;
}while ( <Loans> ) {
# Split the line into an array
@loans = split;
# Print the loan and the amount of interest to the "Total" handle;
# calculate by multiplying the total amount by the value returned
# by the hash key.
print Total "$loans[0]\t\t\$", $loans[2] * $r{lc $loans[1]}, "\n";
}# Close the filehandles - not a necessity, but can't hurt
for ( qw/Rates Loans Total/ ) {
close $_ or die "Can't close $_: $!\n";
}
Here's another example, one that came about as a result of one of my article about procmail ("No More Spam!" in LG#62). The original "blacklist" script that was invoked from Mutt pulled out the spammer's e-mail address via "formail", then parsed the result down to the actual "user@host" address with a one-line Perl script. It took the entire spam mail as piped input. Martin Bock, however, suggested doing the whole thing with Perl; after exchanging a bit of e-mail with him, I came up with the following script based on his idea:
#!/usr/bin/perl -wln
# The '-n' switch makes the script read the input one line at a time--
# the entire script is executed for each line;
# the '-l' enables line processing, which appends carriage returns to
# the lines that are printed out.# If the line matches the expression, then...
if ( s/^From: .*?(\w\S+@\S+\w).*/$1/ ) {
# Open the "blacklist" with the "OUT" filehandle in append mode
open OUT, ">>$ENV{HOME}/.mutt/blacklist" or die "Aargh: $!\n";
# Print $_ to that filehandle
print OUT;
# Close
close OUT or die "Aargh: $!\n";
# Exit the loop
last;
}
[email protected]
<[email protected]>
[email protected] (Joe Blow)
Joe Blow <[email protected]>
[ The artist formerly known as squiggle ] <[email protected]>
(Joe) [email protected] ["Wildman"]
To "decode" what the regular expression in it says, consult the "perlre" manpage. It's not that complex. ![]() Hint: look for the word "greed" to understand that ".*?", and look for the word "capture" to understand the "(...) / $1" construct. Both of them are very important concepts, and both have been mentioned in this series.
Hint: look for the word "greed" to understand that ".*?", and look for the word "capture" to understand the "(...) / $1" construct. Both of them are very important concepts, and both have been mentioned in this series.
Here's a somewhat more compact (and that much less readable) version of the above; note that the mechanism here is somewhat different:
#!/usr/bin/perl -wln
BEGIN { open OUT, ">>$ENV{HOME}/.mutt/blacklist" or die "Aargh: $!\n"; }
if ( s/^From: .*?(\w\S+@\S+\w).*/$1/ ) { print OUT; close OUT; last; }
Next Time
Next month, we'll be looking at a few nifty ways to save ourselves work by using modules: useful code that other people have written from the Comprehensive Perl Archive Network (CPAN). We'll also take a look at how Perl can be used to implement CGI, the Common Gateway Interface - the mechanisms that "hew the wood and draw the water" behind the scenes of the Web. Until then, here are a few things to play with:
Write a script that opens "/etc/services" and counts how many ports are listed as supporting UDP operation, and how many support TCP. Write the service names into files called "udp.txt" and "tcp.txt", and print the totals to the screen.
Open two files and exchange their contents.
Read "/var/log/messages" and print out any line that contains the word "fail", "terminated/terminating", or " no " in it. Make it
case-insensitive.
Until then -
perl -we 'print "See you next month!"'
Ben Okopnik
perl -we'print reverse split//,"rekcah lreP rehtona tsuJ"'
References:
Relevant Perl man pages (available on any pro-Perl-y configured
system):
perl - overview perlfaq - Perl FAQ
perltoc - doc TOC perldata - data structures
perlsyn - syntax perlop - operators/precedence
perlrun - execution perlfunc - builtin functions
perltrap - traps for the unwary perlstyle - style guide
"perldoc", "perldoc -q" and "perldoc -f"
Ben Okopnikcowsay is a configurable talking cow, written in Perl. It draws an ASCII cow with a speech balloon (or a think balloon) saying whatever pithy comment you give it on the command line. The program requires Perl 5.005_03 or newer. Debian Weekly News calls cowsay "an absolutely vital program for turning text into happy ASCII cows". So there you go; you need it.
According to the manpage, there are several command-line options to change the apparance of the cow:
You can also pass in characters for the eyes and tongue, use any of 47 supplied cowfiles (not all of which are cows), or create your own cowfile. A cowfile is a Perl script ending in .cow. The script contains a variable $the_cow containing a picture of the cow. Remember to backslash your "@"'s!
- -b
- Borg
- -d
- dead
- -g
- greedy
- -p
- paranoid
- -s
- stoned
- -t
- tired
- -w
- wired (opposite of tired)
- -y
- youthful
For those who can't wait to see the cows, here are some screenshots:
Script started on Fri May 25 11:56:46 2001
$ cowsay "Hello, bovine world! "
_______________________
< Hello, bovine world! >
-----------------------
\ ^__^
\ (oo)\_______
(__)\ )\/\
||----w |
|| ||
$ cowsay -b "Hello, bovine world! "
_______________________
< Hello, bovine world! >
-----------------------
\ ^__^
\ (==)\_______
(__)\ )\/\
||----w |
|| ||
$ M="Hello, bovine world\!"
$ cowsay -d $M
______________________
< Hello, bovine world! >
----------------------
\ ^__^
\ (xx)\_______
(__)\ )\/\
U ||----w |
|| ||
$ cowsay -p $M
______________________
< Hello, bovine world! >
----------------------
\ ^__^
\ (@@)\_______
(__)\ )\/\
||----w |
|| ||
$ cowsay -s $M
______________________
< Hello, bovine world! >
----------------------
\ ^__^
\ (**)\_______
(__)\ )\/\
U ||----w |
|| ||
$ cowsay -y $M
______________________
< Hello, bovine world! >
----------------------
\ ^__^
\ (..)\_______
(__)\ )\/\
||----w |
|| ||
$ cowsay -f tux $M
_______________________
< Hello, bovine world! >
-----------------------
\
\
.--.
|o_o |
|:_/ |
// \ \
(| | )
/'\_ _/`\
\___)=(___/
$ cowsay -f dragon $M
_______________________
< Hello, bovine world! >
-----------------------
\ / \ //\
\ |\___/| / \// \\
/0 0 \__ / // | \ \
/ / \/_/ // | \ \
@_^_@'/ \/_ // | \ \
//_^_/ \/_ // | \ \
( //) | \/// | \ \
( / /) _|_ / ) // | \ _\
( // /) '/,_ _ _/ ( ; -. | _ _\.-~ .-~~~^-.
(( / / )) ,-{ _ `-.|.-~-. .~ `.
(( // / )) '/\ / ~-. _ .-~ .-~^-. \
(( /// )) `. { } / \ \
(( / )) .----~-.\ \-' .~ \ `. \^-.
///.----..> \ _ -~ `. ^-` ^-_
///-._ _ _ _ _ _ _}^ - - - - ~ ~-- ,.-~
/.-~
$
Script done on Fri May 25 11:59:03 2001
I like that dragon, BTW.
Find cowsay at http://www.nog.net/~tony/warez/cowsay.shtml or in the unstable branch of your nearest Debian mirror, in section "games". (PS. The author's site has a link to the Cows with Guns site, which has a shadow image of, er, two cows with guns saying, "Four legs good. Two legs bad," from Orwell's Animal Farm. I wonder if Eric Raymond would approve? ![]()
Mike OrrRhubarbAnswered By Dan Wilder, Ben Okopnik, Don Marti, Heather Stern, Iron
![]() [Dan] No doubt you mean "rhubarb". I cut off the leaves, wash in cold water, slice, and parblanch it, if freezing for later use. From my childhood in Michigan, I learned that tender young stems are a nice snack fresh, washed and dipped in sugar.
[Dan] No doubt you mean "rhubarb". I cut off the leaves, wash in cold water, slice, and parblanch it, if freezing for later use. From my childhood in Michigan, I learned that tender young stems are a nice snack fresh, washed and dipped in sugar.
![]() [Ben] Bessie, I'd suggest that you take a look at http://groups.google.com, and search for "rhubarb" (not "rhubard") in the rec.cooking group. My quick search has turned up 189 recipes, including the following:
[Ben] Bessie, I'd suggest that you take a look at http://groups.google.com, and search for "rhubarb" (not "rhubard") in the rec.cooking group. My quick search has turned up 189 recipes, including the following:
Yum. Wonder if I can find any rhubarb pie for lunch... :) Cleaning it is pretty much like cleaning celery, nothing special; cooking is as per any of the above recipes, depending on what you want to make.
![]() [Don] Either the leaves or the stems are poisonous, so you shouldn't eat whichever one is the poisonous part. And whatever you do, don't eat the top part of the stem where it meets the leaves -- no matter which part of the plant is poisonous, there will be some poison where they meet. At least if you pick leaves or stems you have a 50/50 chance.
[Don] Either the leaves or the stems are poisonous, so you shouldn't eat whichever one is the poisonous part. And whatever you do, don't eat the top part of the stem where it meets the leaves -- no matter which part of the plant is poisonous, there will be some poison where they meet. At least if you pick leaves or stems you have a 50/50 chance.
And how do you "parblanch"? There's no definition of that term in the Rhubarb-HOWTO.
I don't think rhubarb is ready for the desktop yet, at least until you techie type people straighten out the poison issue and make it parblanch itself.
![]() [Ben]
[Ben]
Don, the GNU version of rhubarb is due out in just a few days; not only does it parblanch itself, it will also frizz, wargle, blatter, *and* mangulate everyone and everything in a 7,000-mile radius. Instead of just a small part of it being poisonous, the entire plant consists of pure potassium cyanide, thus saving you time, money and effort. Not only _that,_ but it also comes with an attractive set of Ginsu knives, and - if you order within the next thirty minutes - our combination orange peeler, toilet disassembler, Fortran debugger, and spaceship detector. Best of all, the source code is included.
Just say "no" to all those proprietary commercial versions of rhubarb! Open Source rules!
![]() [Heather]
[Heather]
At least you won't have to debug the garden anymore.
![]() [Ben] <snerch> Or the rest of Terra, either.
[Ben] <snerch> Or the rest of Terra, either.
![]() [Heather] Say, can you just send me the source to that combination orange peeler, toilet disassembler, fortran debugger, and spaceship detector? I want to compile a local version that detects orange spaceships, and peels them if they have buggy Fortran code installed.
[Heather] Say, can you just send me the source to that combination orange peeler, toilet disassembler, fortran debugger, and spaceship detector? I want to compile a local version that detects orange spaceships, and peels them if they have buggy Fortran code installed.
![]() [Ben] That's disabled by default, but it's easy enough to fix:
[Ben] That's disabled by default, but it's easy enough to fix:
make --with-orange-spaceships-and-buggy-Fortran-autopeelLoooove those "make" options...
![]() [Don] It also comes with an attractive set of Ginsu knives...
[Don] It also comes with an attractive set of Ginsu knives...
![]() [Iron] ...known to those in the know as GiNsU knives. (Bet you didn't know there's a GNU in every Ginsu.)
[Iron] ...known to those in the know as GiNsU knives. (Bet you didn't know there's a GNU in every Ginsu.)
![]() [Dan] And to some others as G1n5u kn1v35.
[Dan] And to some others as G1n5u kn1v35.
Toto je zpráva ve formátu MIME obsahující více částí.
Oggetto: Super offer
Messaggio: I offer SUPER accomodeation in Prague. Only for Linux users. Only 12 EUR/night/room ( 2 pers.) !!
[I'm giving the real address for this site because it's so hilarious. Buy your boss one. -Iron.]www.mylogonmaster.com
This the ultimate lo-tech way to remember your passwords in style! It'ss a blank book in which you can write in the username and password of all the web sites you visit. It's multi-platform, so you can use it with any Operating System. There are special pages to record important system information, such as the model number of your printer cartridge. There's a page for always-forgotten e-mail addresses, and even a pages for Scribbles and Doodles!
Detailed help includes icons showing where to write the site address, your username and your password, and there are even two pages of examples!
Keep passwords cracker-safe! No cracker can reach through the computer to see what you've written down in this little book.
Testimonials from satisfied customers.
Tak a look at the St Bernard on the cover.
Article about designing a space elevator. [Space Daily, courtesy Slashdot.]
![]() [Ben] <laugh> That "folk song to the tune of" 'Those Were the Days' is the "Dorogoi Dlinnoyu".
[Ben] <laugh> That "folk song to the tune of" 'Those Were the Days' is the "Dorogoi Dlinnoyu".
![]() [Iron] How did "Dear Longs" (whatever that means) get translated as "Those Were the Days"? Is it a reference to the 24-hour summer days in St Pete?
[Iron] How did "Dear Longs" (whatever that means) get translated as "Those Were the Days"? Is it a reference to the 24-hour summer days in St Pete?
![]() [Ben] Wrong accent. "do-ro-GOI" would be "dear"; "do-RO-goi" is "<along the> road". It's "[Along|By] the Long Road", and Raskin managed (very well, too) to keep the sense of the song... if not the traditionally morbid /fin-de-siecle/ ending.
[Ben] Wrong accent. "do-ro-GOI" would be "dear"; "do-RO-goi" is "<along the> road". It's "[Along|By] the Long Road", and Raskin managed (very well, too) to keep the sense of the song... if not the traditionally morbid /fin-de-siecle/ ending.
![]() [Iron] I just remembered there are two "Those Were the Days" songs in English. One has the same tune as the Russian song and starts off, "Those were the days, my friend. We don't know where nor when..."
[Iron] I just remembered there are two "Those Were the Days" songs in English. One has the same tune as the Russian song and starts off, "Those were the days, my friend. We don't know where nor when..."
![]() [Breen Mullins]
[Breen Mullins]
Those were the days, my friend, We thought they'd never end. We'd sing and dance forever and a day. We'd live the life we'd choose, We'd fight and never lose, Those were the days, Oh yes those were the days.
![]() [Iron] Then there's the "All in the Family" theme that goes something like, "When girls were girls and men were men." Perhaps the two songs are related, but they sound awfully different.
[Iron] Then there's the "All in the Family" theme that goes something like, "When girls were girls and men were men." Perhaps the two songs are related, but they sound awfully different.
![]() [Breen]
[Breen]
[who?] wrote and Miller played, Songs that made the Hit Parade. Guys like us we had it made, Those were the days. And you knew when you were then, Girls were girls and men were men. Mister, we could use a man like Herbert Hoover again. Didn't need no welfare state, Everybody pulls his weight. [umty umty umty...] Those were the days.
I think the second was inspired by the first, but as Mike says the tunes are completely different.
PC speakerAnswered By Iron
![]() [Iron]
[Iron]
$ dosemu C:\> halloween.exe Welcome to Halloween, version 1.2
Have you ever heard a computer scream?
Would You Like To Be On A TV Commercial?Answered By Heather Stern, Ben Okopnik
![]() [Heather] We asked Tux but it seems that he already has enough appearance engagements. We've considered TeX the lion but he won't come unless we also sign his girlfriend - negotiations are still underway. The l'il Daemon in Tennis Shoes says we're not related to BSD and declined to comment further.
[Heather] We asked Tux but it seems that he already has enough appearance engagements. We've considered TeX the lion but he won't come unless we also sign his girlfriend - negotiations are still underway. The l'il Daemon in Tennis Shoes says we're not related to BSD and declined to comment further.
We hope you understand that we are trying to get ONLY serious people who really want to try and like the camera.Anybody who makes the camera unhappy will be let go without further notice. He's our star, and you're just a new actor. If we really like your work we might call you back on another set, sometime.
There is absolutely no payment of any form required from your side. On the oposite, all jobs we offers are well paid.We hope you like peanuts, because you'll get a lot of them.
This email is sent to you in full compliance with all existing and proposed email legislation.
We have a legal telepath on staff who is able to delete all our outbound email the moment any countering legislation is proposed in the House or Senate. We think. We often worry about whether we pay him enough.
Note: You are not on a mailing list, and this is a one-time email. If we don't get an answer, you'll never hear from us any more. You are removed by default. You can still reply with the word Remove in the subject. This right is yours by law.
Mr. Mailbox, you have the right to remain full. You may state "Remove" but it may be used against you and you won't be able to tell who did it. You have the right to mail filters. If you can't afford one then articles about procmail may be provided by the Linux Gazette. Please do not resist while I put on these "delete" handcuffs.
Use Fax nr 1-###-###-####
We'd fax you, but our legal telepath advises against it. I'm not really sure why he winced when he said that, but anyways, you know the number now.
![]() [Ben] <hi-five> Hea-THER! Yeah!!! <Laugh> A smackdown full of "Go Away, Spammer" goodness. /me likes.
[Ben] <hi-five> Hea-THER! Yeah!!! <Laugh> A smackdown full of "Go Away, Spammer" goodness. /me likes.
Win at Online BlackJack - Guaranteed!
Look, this is no BS or scam. We have now released the way to win at online blackjack - guaranteed. I have been banned from playing at most online casinos and this is my way of payback. I make money doing this EVERYDAY and now you can too. I will only sell 500 of these books and then I and the website go away again.
I visited your site at http://www.linuxgazette.com/ and offer to translate into Russian language. Maybe this decision will be a lucky step forward in the history of your company. Russian businessmen are looking for partners abroad all the time, organizations of culture are looking for friends. PS The translations may be done both from English into Russian and from Russian into English. Minimum amount $20.
Over the last 4 years I have built my retirement income stream in a Network Marketing Company that has eclipsed every measurable growth category in the history of the industry. We have grown faster than Microsoft, IBM and Coca Cola did in their first 3 years. Although we do no advertising and you most likely have never heard of us we currently are operating at THIRTY-TWO MILLION DOLLARS per MONTH in 22 countries !!
This phenomenal growth has been fueled by a product that my company has the exclusive world-wide distribution rights to and enjoys a 83% reorder order rate with the consumer base.
I am looking to pass the baton to the right person or persons. I can and will offer the following:
I am not looking for an investor, I am looking for a working partner or partners.
Only the seasoned NETWORKER or experienced business entrepreneur with the right aptitude and attitude for success starting today need reply.
![]() [Iron] If you're so successful, why are you looking for an unknown partner on the Internet? You must know lots of people suitable to turn your company over to.
[Iron] If you're so successful, why are you looking for an unknown partner on the Internet? You must know lots of people suitable to turn your company over to.
Is this company still growing even though the other dot coms are not? Or is this an old letter still being recycled?
![]() [Ben]
[Ben]
Over the last 4 years I have built my retirement income stream in ascheme based on embezzlement, theft, and con games that I call a
Network Marketing Company that has eclipsed every measurable growthof jock and toe fungus. In fact, it has supplanted that entire medical
category in the history of the industry. We have grown faster thananyone in the files of the FBI, DOJ, and the DEA, up to and including
Microsoft, IBM and Coca Cola did in their first 3 years. Althoughwe haven't yet been caught due to the fact that we run and hide and
we do no advertising and you most likely have never heard of us westill manage to come up with insanely moronic claims, like: we
currently are operating at THIRTY-TWO MILLION DOLLARS per MONTH in 22 countries !!This should be enough to convince you that we've been cutting our crack with too much plutonium, but if you're not yet convinced - read on!
This phenomenal growth has been fueled by a product that my companystole from Salvation Army trash cans. We like to pretend that it
has the exclusive world-wide distribution rights to and enjoys a 83%rate of not being spotted raiding the trash. We call that our
reorder order rate with the consumer base.just to throw in some cool-sounding words we read in _real_ ads.
I am looking to pass the baton to the right person or persons. I cando to you what I've always fantasized about (since I have no girlfriend)
and will offer the following:Those trash cans are *still* unwatched! The world is MINE!!!
- a. An inexhaustible world wide lead source - at no expense to you.
Black mask only $9.95; you must bring your own gloves and flashlight.b. A tested and proven duplicable training system, created and ran by me..for you
Two of us have done this for three months, but we really suck at math.c. 21 years of experience in this industry which we will compound into your success
I am not looking for an investor, I am looking for a working partner or partners.The darn cans rattle if nobody holds them!
Only the seasoned NETWORKER or experienced business entrepreneurwill laugh at this... well, OK, everybody will, but all those
with the right aptitude and attitude for success starting today needto hold their guffaws; one day, they might have a stupid idea too! Of course, anyone with even the slightest semblance of intelligence won't
reply.
Hello I visited your web site and I noticed that you did not have a message board.. So I just wanted to say that you should add one, because it will allow your visitors to interact with each other.. and also allows you to interact with them too..
[Great idea. In fact, we already have it! Click the "Talkback" link on the bottom of any article except the columns. -Iron.]
Several months ago, I made a conscious decision not to delete what I figured was just another “junk” e-mail. That decision has changed my life. Here you have the very same opportunity in front of you. If you take just five minutes to read through the following program you won't regret it. See for yourself!
Dear Friends & Future Millionaires:
AS SEEN ON NATIONAL TV
Making over half a million dollars every 4 to 5 months from your home for an investment of only $25 U.S. dollars expense one time. THANKS TO THE COMPUTER AGE AND THE INTERNET !
Before you say ''Bull'', please read the following. This is the letter you have been hearing about on the news lately.
NEW CD ROM is helping to Create HUGE FORTUNES!!
Free Info:
We will email you all you need to know to get signed up and making money TODAY!!!
OUR NEXT STOCK PICK: XXXX $0.59. Target Price: $3.00 - $3.50. We consider XXXX a STRONG BUY!
We offer you to PLUGIN to the largest SEX-SERVER on the WEB.
This mail is never sent unsolicited. You received this “auto respond” email because you or someone you know submitted your address to our info page. Upon submission you agreed to receive this email about our program.
Hello Fellow Online Marketer. Greetings! We hope everything is going well for you in your online marketing adventure. This is just a quick one-time note to let you know about an Internet Training Program that can put $200 cash ($20 x 10) in your mailbox. EVERYDAY!
Legitimate start-up dot-com seeks motivated and innovative sales representatives for international marketing campaign. Online and offline sales. High earning potential (30-40% commission to start)! No start-up costs to you!!!
May I have your permission to send you free information on how to get started in business?
1. How many hours a day do you spend generating new sales leads? Select 0 1 2 3 4 5 or More Hours
2. What primary Industry are your in? Select Hardware Software Telecommunications Commercial Real Estate Insurance Recruiting/Staffing Other. If Other, please provide.
3. Do you use Company Press Releases Sources to find new sales leads? Yes No PR Sources. [List of eight publications not shown.] Press Releases are a great way to find out which companies are growing, etc. You can find these releases in individual releases from News Wires or thru recaps in Daily Newsletters.
4. How often do you use these sources? Select Everyday 2-3 Times a Week Once a Week Once a Month Never
5. How many hours a day do you spend going thru these Press Release Sources? Select 0 1 2 3 4 5 or More Hours
6. Would you be interested in a new daily resource that gives you detailed Sales Leads of Executives from companies that are growing? Yes No
7. Would you pay $70 a month for the service mentioned above along with a database of more than 4000 companies with the same info? Yes No
Dear Fellow Network Marketer,
Recently you requested information on our Full Questionnarre Network Marketing Leads. Our Leads are exclusive to your opportunity. We guarantee results and have a no questions asked replacement policy for any "bad" leads.
Bottom line. Our Leads create residual income for you.
Every lead guaranteed to be a Network Marketer and to have marketing experience. What does this mean for you? NO DEADBEATS!
Call today and ask how you can recieve 20 FREE quality Leads!
Lead orders sent VIA email same day recieved. NO WAITING!
Dear Sir/Madam from The Answer Guy, are you measuring the response rate when doing marketing activities?
Introducing our fantastic new service to the UK - Joke Line XXXXX All your favourite wind-ups, but now you can listen in!
Call #### ### #### and pick the joke you wish to play on your friend. Then, enter your friend's phone number and they will be called Finally, you can hear the joke and your friend's voice as well. They cannot hear or know it is you.
Happy Linuxing!
Mike ("Iron") Orr
Editor, Linux Gazette,

